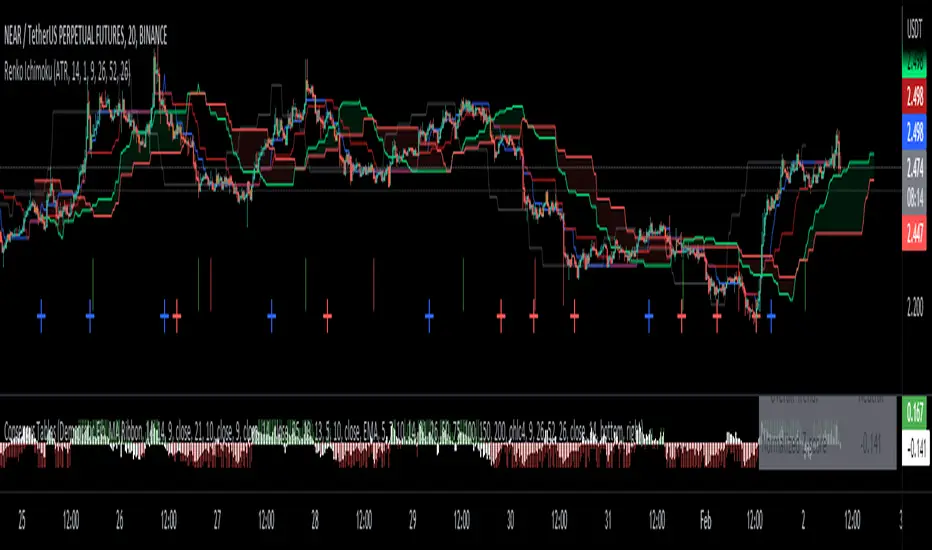
Renko Ichimoku CloudThis script utilizes its source from a non-repainting renko closing price. Renko charts focus solely on price movement and minimize the impacts of time and the extra noise time creates. Employing the renko close helps smooth out the Ichimoku Cloud. Insignificant price movements will not cause a change in the plotted lines of the indicator unless a new threshold is breached or a "brick" is created.
This Ichmoku Cloud includes all standard lines with standard lengths. These include:
Tenken Sen
Kiju Sen
Senkou A/B
Chikou Span
We have also included plotted marks for when there is a Tenken Sen/ Kiju Sen cross and for the Kumo cloud twist.
There are two methods for selecting the box size. Box size is critical for the overall function and efficacy of the plots you will visually see with this indicator. Box size is set automatically using the Average True Range "ATR" or manually using the "Traditional" setting. The simplest way to determine a manual box six is to take the ATR of the given instrument and round it to the nearest decimal place. As an example, if the ATR for the asset is 0.017, you would round that number to 0.02 and utilize this as your traditional box size.
Smoothing
NET BSP NET BSP derived from Buying & Selling Pressure which is a volatility indicator that monitors average metrics of green and red candles separately.
We could navigate more confidently through market with projected market balance.
BSP allowed us to track and analyze the ongoing performance of bullish and bearish impulsive waves and their corrections.
Due to unintuitive way of measuring decline with SP going up, I decided to remake it into more intuitive version with better precision.
When we encounter the fall it's better to have declining values of tool to be able to cover it visually with ease.
One of the solutions was to create a sense of balance of Buying Pressure against Selling Pressure.
Since we are oriented by growth, it'd be more logical to summarize the market balance with BP - SP
Comparison:
When Buying and Selling Pressure are equal, NET BSP would be at 0.
NETBSP > 0 and NETBSP > NETBSP = 🟢
NETBSP > 0 and NETBSP < NETBSP = 🟡
NETBSP < 0 and NETBSP < NETBSP = 🔴
NETBSP < 0 and NETBSP > NETBSP = 🟡
Hence, we get visualized stages of uptrends and downtrends which allows to evaluate chances and estimations of upcoming counter-waves.
Also, it is worth to note that output clearly shows how one wave is derived from another in terms of sizing.
Feel free to adjust NET BSP arguments to adapt sensitivity to the timeframe you're working on.

Library_SmoothersLibrary "Library_Smoothers"
CorrectedMA(Src, Len)
CorrectedMA The strengths of the corrected Average (CA) is that the current value of the time series must exceed a the current volatility-dependent threshold, so that the filter increases or falls, avoiding false signals when the trend is in a weak phase.
Parameters:
Src
Len
Returns: The Corrected source.
EHMA(src, len)
EMA Exponential Moving Average.
Parameters:
src : Source to act upon
len
Returns: EMA of source
FRAMA(src, len, FC, SC)
FRAMA Fractal Adaptive Moving Average
Parameters:
src : Source to act upon
len : Length of moving average
FC : Fast moving average
SC : Slow moving average
Returns: FRAMA of source
Jurik(src, length, phase, power)
Jurik A low lag filter
Parameters:
src : Source
length : Length for smoothing
phase : Phase range is ±100
power : Mathematical power to use. Doesn't need to be whole numbers
Returns: Jurik of source
SMMA(src, len)
SMMA Smoothed moving average. Think of the SMMA as a hybrid of its better-known siblings — the simple moving average (SMA) and the exponential moving average (EMA).
Parameters:
src : Source
len
Returns: SMMA of source
SuperSmoother(src, len)
SuperSmoother
Parameters:
src : Source to smooth
len
Returns: SuperSmoother of the source
TMA(src, len)
TMA Triangular Moving Average
Parameters:
src : Source
len
Returns: TMA of source
TSF(src, len)
TSF Time Series Forecast. Uses linear regression.
Parameters:
src : Source
len
Returns: TSF of source
VIDYA(src, len)
VIDYA Chande's Variable Index Dynamic Average. See www.fxcorporate.com
Parameters:
src : Source
len
Returns: VIDYA of source
VAWMA(src, len, startingWeight, volumeDefault)
VAWMA = VWMA and WMA combined. Simply put, this attempts to determine the average price per share over time weighted heavier for recent values. Uses a triangular algorithm to taper off values in the past (same as WMA does).
Parameters:
src : Source
len : Length
startingWeight
volumeDefault : The default value to use when a chart has no volume.
Returns: The VAWMA of the source.
WWMA(src, len)
WWMA Welles Wilder Moving Average
Parameters:
src : Source
len
Returns: The WWMA of the source
ZLEMA(src, len)
ZLEMA Zero Lag Expotential Moving Average
Parameters:
src : Source
len
Returns: The ZLEMA of the source
SmootherType(mode, src, len, fastMA, slowMA, offset, phase, power, startingWeight, volumeDefault, Corrected)
Performs the specified moving average
Parameters:
mode : Name of moving average
src : the source to apply the MA type
len
fastMA : FRAMA fast moving average
slowMA : FRAMA slow moving average
offset : Linear regression offset
phase : Jurik phase
power : Jurik power
startingWeight : VAWMA starting weight
volumeDefault : VAWMA default volume
Corrected
Returns: The MA smoothed source

KG StabilizerThis is a personal experimental stabilizer , which utilizes multitiered highest and lowest levels to hold an average with historical levels where the source value has a bias direction.
Settings
Smoothing ema length
Lines count for additional passes (forming a pseudo ribbon)
User choice of 2 colors to fade between
Bias choice input to either follow a mid-level, or to pull strongly towards either high or low values.
You can use any source input of your own to pass through this. it works especially well on Oscillators.
There is a Output of the average for 'indicator on indicator' outputs to chain.
Demonstration shows the difference between the bottom indicator, and the middle indicator being applied on top of it.
The Top indicator is simply applied on the close value.

Smooth EMA/DEMA/TEMA/EHMA (SEMA)This is my attempt at smoothing the exponential moving average any its cousins. I literally just smoothed the source and alpha and this is what we got. I really like this because you get a nice smooth yet fast acting moving average that works better than a traditional simple moving average. This script also included directional alerts.
Smooth EMA
Smooth DEMA
Smooth TEMA
Smooth EHMA

Adaptive Fisherized ROCIntroduction
Hello community, here I applied the Inverse Fisher Transform, Ehlers dominant cycle determination and smoothing methods on a simple Rate of Change (ROC) indicator
You have a lot of options to adjust the indicator.
Usage
The rate of change is most often used to measure the change in a security's price over time.
That's why it is a momentum indicator.
When it is positive, prices are accelerating upward; when negative, downward.
It is useable on every timeframe and could be a potential filter for you your trading system.
IMO it could help you to confirm entries or find exits (e.g. you have a long open, roc goes negative, you exit).
If you use a trend-following strategy, you could maybe look out for red zones in an in uptrend or green zones in a downtrend to confirm your entry on a pullback.
Signals
ROC above 0 => confirms bullish trend
ROC below 0 => confirms bearish trend
ROC hovers near 0 => price is consolidating
Enjoy! 🚀
Fisherized CCIIntroduction
This here is a non-repainting indicator where I use inverse Fisher transformation and smoothing on the well-known CCI (Commdity Channel Index) momentum indicator.
"The Inverse Fisher Transform" describes the calculation and use of the inverse Fisher transform by Dr . Ehlers in 2004. The transform is applied to any indicator with a known probability distribution function. It enables to transform an indicator signal into the range between +1 and -1. This can help to eliminate the noise of an indicator.
The CCI is an momentum indicator which describes the distance of the price to the average price.
For smoothing I used the Hann Window and NET (Noise Elimination Technique) methods.
Additional Features
Divergence Analysis
Trend-adaptive Histogram
Timeframe selection
Usage
It is usually used to spot potential trend reverals or mean-reversion (against the trend) trades on lower timeframes. IMO it can be even used to spot trend-following trades. It always depends on which settings you have, which timeframe do you use and which indicators you combine with it.
The suggested timeframe for this indicator is 15 min (with the length setting on 50).
The histogram with adaptive mode enabled could be used as filter applied on the buy and sell signals.
The divergence analysis can help to spot additional entries/exits or confirm the buy and sell signals.
Always try to find the best settings! This indicators has a lot of customization options you should take advantage of.
Signals
The indicator uses the following logic to generate the buy and sell signals:
Normal
Buy -> When CCI and MA go above the top band (usually +100) and cross
Sell -> When CCI and MA go below the the bottom band (usually -100) and cross
Fisherized
Buy -> When CCI and MA go above the the zero line and cross
Sell -> When CCI and MA go below the the zero line and cross
Have fun with the indicator! I am open for feedback and questions. :)

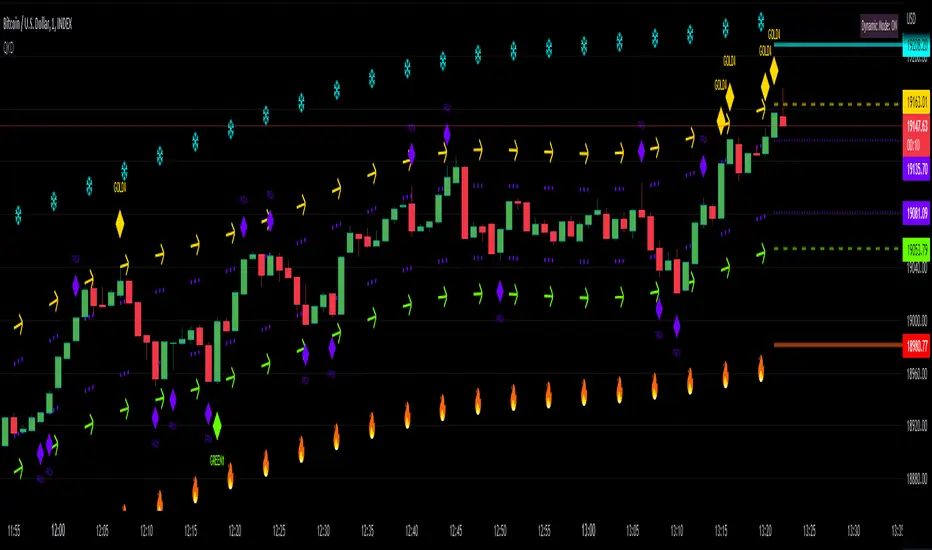
Quantitative Kernel DelimiterQuantitative Kernel Delimiter QKD - aka "Fire and ICE" - is a six-level multiple Kernel regression estimator with cross-timeframe semi-coordinated delimiters (bands) enabled by mathematical validation to our own Kernel regression code with historical Kernel formulas having custom variable bandwidths , mults , and window width – all achieving an advanced alerting system and directional price-action pointers for Novice, Intermediate and Advanced Traders within the TradingView Graphical User Interface.
In the course of our work, we have found that such six delimiters are ideal for generating signals of varying strengths.
99.9% of observations should be in our delimiters' range:
Kernel regression is a nonparametric smoothing method for data modeling.
Kernel regression of statistics was derived independently by Nadaraya and Watson in 1964 with a mathematical foundation given by Parzen’s earlier work on kernel density estimation.
If you are interested in reading more about the mathematical basis of this method from which our code is derived, you can follow these scholarly links:
Expert Trading Systems: Modeling Financial Markets with Kernel Regression
Estimation of the bandwidth parameter in Nadaraya-Watson
Adaptive optimal kernel density estimation for directional data
How kernel regression differs from the other Moving Averages?
In most MA's data points in the specified lookback window are weighted equally. In contrast, the Gaussian Kernel function used in this indicator assigns a higher weight to data points that are closer to the current point. This means that the indicator will react more quickly to changes in the market.
Regression method from which our code is derived is a widely known formula that is laid out in many sources, we used this source:
Kernel regression estimation
Kernel
During the regression counting process, a `kernel function` is used, which is traditionally chosen from a wide variety of symmetric functions.
In this indicator, we use the Gaussian density of statistics as the kernel function.
The Gaussian Kernel is one of the most commonly used Kernel functions and is used extensively in many Machine Learning algorithms due to its general applicability across a wide variety of datasets.
The kernel regression averages all the data contained within the range of the kernel function.
The effective range of the kernel function is defined by its window width .
Kernel Delimiters (Bands / Levels)
This indicator has 6 tailored price range* delimiters:
Cold / Fire - the furthest delimiters. In a range market when the price enters the cold/fire zones it is assumed that it has deviated strongly from the average and there is a high probability that it will immediately return to the average, or at least into the underlying zone, also in a trending market it signals a change in trend.
ALERT: the indicator performs best during relatively sideways price action within an established range. The trader must check higher timeframes during hits on the extreme Cold or Fire delimiter bands as a break in the lower, or even higher timeframe price range may result in a need to reset the regression calculation once price velocity calms down after a major move allowing the indicator to best function again. The reset will be done automatically by the indicator’s code. The indicator is not intended for use with unusually aggressive pricing behavior. Always beware of extreme market conditions. The indicator is intended as an ordinary range trading tool.
Gold / Green - we call it the middle ground / golden mean / happy medium zone. When the price comes out here but the momentum is not enough to get to the higher zone we consider it a good signal.
Pro - most often we receive signals in this area. We call it the professional zone because it is literally the zone for professional traders who know what they are dealing with.
*NOTE: the indicator is intended to be used as a range trading tool, and does not protect against total BREAKS from one Range to a new Range, wherein the bands reset for the trader.
Alerts / Labels
We have spent a lot of time implementing and testing signal labels* and alerts**.
Now you have access to an advanced alert system.
*NOTE: DUE TO the ongoing regression calculations performed by our code, the trader will note that a label may change color at a later point in time, or even soon after the hit on the quantitative delimiter band in question. This is a process that was reviewed and is favored to achieve visual clarity over historical accuracy for the trader. Real-time trading hits of price line to band, along with alerts generated, remain accurate. We look forward to receiving feedback on this issue from the end users. Additional revisions by our team on this matter are anticipated if a harmony between visual clarity and historical accuracy is not satisfied.
**NOTE: Smaller and especially micro timeframes will result in more repeated alerts given the tight proximity with price vis-à-vis the quantitative delimiter. Larger timeframes tend to eliminate any issue with repeated alerts aside from obvious re-contacting of the quantitative delimiter by the active price line.
You can turn off alerts you don't need in the indicator settings.
All alerts are set with one click.
Themes
Different people like different things, which is why we decided to make several visual design themes so you can choose what suits you.
Themes will continue to evolve over time.
Pro Theme:
Modern Theme:
How to remove colored text labels next to price scale to maximize screen space on mobile:
Go to General Chart Settings :
Click on “SCALES”
Un select “Indicators and financial name.”
Dynamic Mode
Projection of Indicator bands on history is subject to repainting due to its regressive calculation nature. Be cautious: old signals are drawn once at the first loading of the chart and by default (to speed up the start-up time of the indicator) correspond to the current regression levels. All labels remain in their places as the chart progresses. Also new, real-time labels appear on the chart, and do not disappear. In order to display the old signals on the chart as they were at the time of their appearance, uncheck the "History labels transition" in the indicator settings (it may increase the initial loading time of the chart but will give you an opportunity to check the alerts you received before and may also be useful for visual backtesting).
Because of the very nature of modeling financial markets (i.e., thousands of data records and perhaps hundreds of candidate predictors), the need for computational speed is paramount.
The use of kernel regression in data modeling for the types of problems associated with financial markets requires careful consideration of computational time.
Once we acknowledge that the order of the data is important, then the choice of the learning-data-set becomes crucial. The time dimension introduces another level of complexity to the analysis: how much importance do we attach to recent data records as opposed to earlier records? Is there a simple way to take this effect into consideration? Common sense leads us to the basic conclusion that if we are to predict a value of Y at a given time, we should only use learning data from an earlier time. But this procedure tends to be overly restrictive. This problem has a simple solution: All that one must do is to make the learning data set dynamic . In other words, once a record has been tested, it is then available for updating the learning data set prior to testing the next record. The analyst can allow the learning data set to grow, or, alternatively, for each record added, the earliest remaining record in the learning set can be discarded. These two alternatives have led us to the necessity of using moving window option and adding a disclaimer that dynamic mode is enabled.
This indicator will be updated frequently based on community feedback see the Author’s instructions below to get instant access
―――――――――――――――――――――
Liability Disclaimer
Never fully rely on one indicator as you trade. Successful trading may require an orchestral mindset and harmonіc blend of trading tools, know-how, and devices. VIP Trader . com is not responsible for any damages or losses incurred by use or misused of this indicator. Neither this description above, nor the indicator, is intended to be used as financial advisory tool, nor to be used without proper education or training in the field of trading.
Nadaraya-Watson CombineThis is a combination of the Lux Algo Nadaraya-Watson Estimator and Envelope. Please note the repainting issue.
In addition, I've added a plot of the actual values of the current barstate of
the Nadaraya-Watson windows as they are computed (lines 92-95). It only plots values for the current data at
each time update. It is interesting to compare the trajectory of the end points of the Estimator and
Envelope to the smoothing function at each time update. Due to the kernel smoothing at each update the
history is lost at each update (repaint).
I've added a feature to allow adjustment to the kernel smoothing algorithm as suggested by thomsonraja (line 59).
The settings and usage are repeated from Lux Algo below.
Settings
Window Size: Determines the number of recent price observations to be used to fit the Nadaraya-Watson Estimator.
Bandwidth: Controls the degree of smoothness of the envelopes , with higher values returning smoother results.
Mult: Controls the envelope width.
Src: Input source of the indicator.
Kernel power: See line 59, adjusts the exponential power (powh) as suggested by thomsonraja
Kernel denominator: See line 59, adjusts the denominator (den) as suggested by thomsonraja
Usage
This tool outlines extremes made by the prices within the selected window size.
This is achieved by estimating the underlying trend in the price using kernel smoothing,
calculating the mean absolute deviations from it, and adding/subtracting it
from the estimated underlying trend.
I repeat Lux Algo's caution: 'we do not recommend this tool to be used alone
or solely for real time applications.'
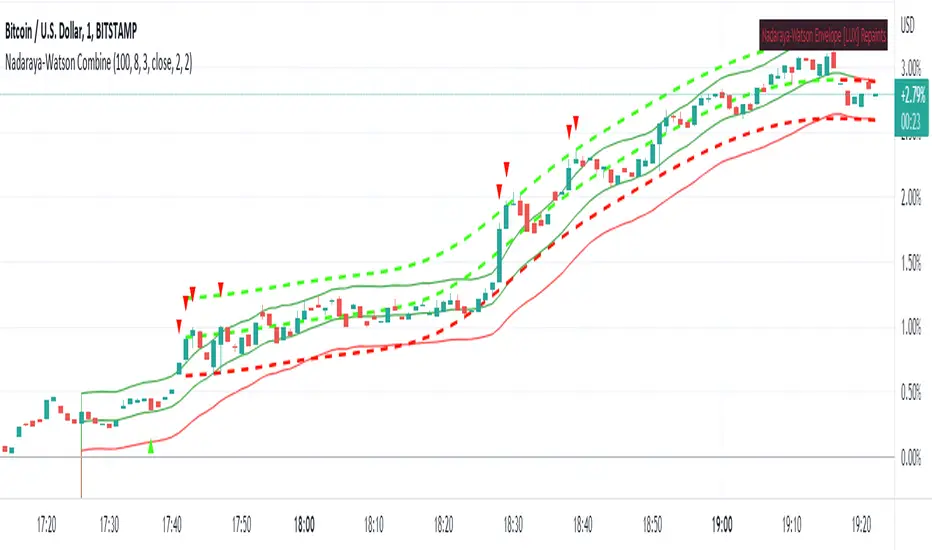
Nadaraya-Watson: Rational Quadratic Kernel (Non-Repainting)What is Nadaraya–Watson Regression?
Nadaraya–Watson Regression is a type of Kernel Regression, which is a non-parametric method for estimating the curve of best fit for a dataset. Unlike Linear Regression or Polynomial Regression, Kernel Regression does not assume any underlying distribution of the data. For estimation, it uses a kernel function, which is a weighting function that assigns a weight to each data point based on how close it is to the current point. The computed weights are then used to calculate the weighted average of the data points.
How is this different from using a Moving Average?
A Simple Moving Average is actually a special type of Kernel Regression that uses a Uniform (Retangular) Kernel function. This means that all data points in the specified lookback window are weighted equally. In contrast, the Rational Quadratic Kernel function used in this indicator assigns a higher weight to data points that are closer to the current point. This means that the indicator will react more quickly to changes in the data.
Why use the Rational Quadratic Kernel over the Gaussian Kernel?
The Gaussian Kernel is one of the most commonly used Kernel functions and is used extensively in many Machine Learning algorithms due to its general applicability across a wide variety of datasets. The Rational Quadratic Kernel can be thought of as a Gaussian Kernel on steroids; it is equivalent to adding together many Gaussian Kernels of differing length scales. This allows the user even more freedom to tune the indicator to their specific needs.
The formula for the Rational Quadratic function is:
K(x, x') = (1 + ||x - x'||^2 / (2 * alpha * h^2))^(-alpha)
where x and x' data are points, alpha is a hyperparameter that controls the smoothness (i.e. overall "wiggle") of the curve, and h is the band length of the kernel.
Does this Indicator Repaint?
No, this indicator has been intentionally designed to NOT repaint. This means that once a bar has closed, the indicator will never change the values in its plot. This is useful for backtesting and for trading strategies that require a non-repainting indicator.
Settings:
Bandwidth. This is the number of bars that the indicator will use as a lookback window.
Relative Weighting Parameter. The alpha parameter for the Rational Quadratic Kernel function. This is a hyperparameter that controls the smoothness of the curve. A lower value of alpha will result in a smoother, more stretched-out curve, while a lower value will result in a more wiggly curve with a tighter fit to the data. As this parameter approaches 0, the longer time frames will exert more influence on the estimation, and as it approaches infinity, the curve will become identical to the one produced by the Gaussian Kernel.
Color Smoothing. Toggles the mechanism for coloring the estimation plot between rate of change and cross over modes.

Kalman Gain Parameter MechanicsFrequently asked question is to explain how Gain parameter works in kalman funtion. This script serves as a visual representation of Gain parameter of Kalman function used in HMA-Kalman & Trendlines script. (The function creator's name was misspeled in that script as Kahlman)
To see better results set your Chart's timeframe to Daily.

Kendall Rank Correlation NET on SMA [Loxx]Kendall Rank Correlation NET on SMA is an SMA that uses Kendall Rank Correlation to form a sort of noise elimination technology to smooth out trend shifts. You'll notice that the slope of the SMA line doesn't always match the color of the SMA line. This is behavior is expected and is the NET that removes noise from the SMA.
What is Kendall Rank Correlation?
Also commonly known as “Kendall’s tau coefficient”. Kendall’s Tau coefficient and Spearman’s rank correlation coefficient assess statistical associations based on the ranks of the data. Kendall rank correlation (non-parametric) is an alternative to Pearson’s correlation (parametric) when the data you’re working with has failed one or more assumptions of the test. This is also the best alternative to Spearman correlation (non-parametric) when your sample size is small and has many tied ranks.
Kendall rank correlation is used to test the similarities in the ordering of data when it is ranked by quantities. Other types of correlation coefficients use the observations as the basis of the correlation, Kendall’s correlation coefficient uses pairs of observations and determines the strength of association based on the patter on concordance and discordance between the pairs.
Concordant: Ordered in the same way (consistency). A pair of observations is considered concordant if (x2 — x1) and (y2 — y1) have the same sign.
Discordant: Ordered differently (inconsistency). A pair of observations is considered concordant if (x2 — x1) and (y2 — y1) have opposite signs.
Kendall’s Tau coefficient of correlation is usually smaller values than Spearman’s rho correlation. The calculations are based on concordant and discordant pairs. Insensitive to error. P values are more accurate with smaller sample sizes.
Included:
-Toggle on/off bar coloring
Adaptive, Double Jurik Filter Moving Average (AJFMA) [Loxx]Adaptive, Double Jurik Filter Moving Average (AJFMA) is moving average like Jurik Moving Average but with the addition of double smoothing and adaptive length (Autocorrelation Periodogram Algorithm) and power/volatility {Juirk Volty) inputs to further reduce noise and identify trends.
What is Jurik Volty?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
That's why investors, banks and institutions worldwide ask for the Jurik Research Moving Average ( JMA ). You may apply it just as you would any other popular moving average. However, JMA's improved timing and smoothness will astound you.
What is adaptive Jurik volatility?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
Included
- Double calculation of AJFMA for even smoother results
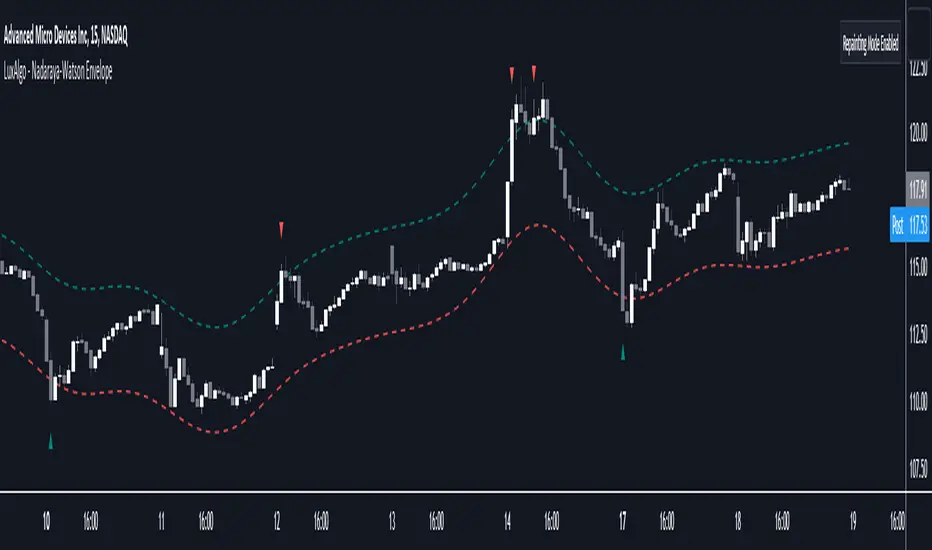
Nadaraya-Watson Envelope [LuxAlgo]This indicator builds upon the previously posted Nadaraya-Watson smoothers. Here we have created an envelope indicator based on Kernel Smoothing with integrated alerts from crosses between the price and envelope extremities. Unlike the Nadaraya-Watson estimator, this indicator follows a contrarian methodology.
Please note that by default this indicator can be subject to repainting. Users can use a non-repainting smoothing method available from the settings. The triangle labels are designed so that the indicator remains useful in real-time applications.
🔶 USAGE
🔹 Non Repainting
This tool can outline extremes made by the prices. This is achieved by estimating the underlying trend in the price, then calculating the mean absolute deviations from it, the obtained result is added/subtracted to the estimated underlying trend.
The non-repainting method estimates the underlying trend in price using an "endpoint Nadaraya-Watson estimator", and would return similar results to more classical band indicators.
🔹 Repainting
The repainting method makes use of the Nadaraya-Watson estimator to estimate the underlying trend in the price. The construction of the band extremities is the same as in the non-repainting method.
We can expect the price to reverse when crossing one of the envelope extremities. Crosses between the price and the envelopes extremities are indicated with triangles on the chart.
For real-time applications, triangles are always displayed when a cross occurs and remain displayed at the location it first appeared even if the cross is no longer visible after a recalculation of the envelope.
By popular demand, we have integrated alerts for this indicator from the crosses between the price and the envelope extremities. However, we do not recommend this precise method to be used alone or for solely real-time applications. We do not have data supporting the performance of this tool over more classical bands/envelope/channels indicators.
🔶 SETTINGS
Bandwidth: Controls the degree of smoothness of the envelopes, with higher values returning smoother results.
Mult: Controls the envelope width.
Source: Input source of the indicator.
Repainting Smoothing: Determine if a repainting or non-repainting method should be used for the calculation of the indicator.
🔶 RELATED SCRIPTS
For more information on the Nadaraya-Watson estimator see:
Smoothed Wave ScalperThis one is a little different.
Instead of layering lots of indicators to filter noise, I'm instead using two different kinds of price averaging to smooth the candles and better define the direction. Just select a smoothing value that fits your chart and timeframe. In theory, this should remove a fair bit of noise (although nothing's perfect)
I've managed to determine when the candles change colour, signifying a potential new trend. When the candle colours do change, an alert is fired. It's as simple as that! Wyckoff wave volume analysis is then applied to each alert to validate the move. Further filtering can be achieved using heikin ashi candles if this is your preference.
Alerts are built in for both the candle colour change and the wave filtered signals (long/short). Use long/short for entries and the colour changes for exits.
I'm currently trading with linear regression to help indentify obvious channels and areas of support/resistance. The candles bouncing down off of the upper band can confirm a downward trend, and bouncing off of the lower band can signify an up trend. It's much easier to see with smoothed candles like these and can give you confidence when trading manually. These bands are rendered automatically, but aren't essential to taking a trade.

Nadaraya-Watson Smoothers [LuxAlgo]The following tool smoothes the price data using various methods derived from the Nadaraya-Watson estimator, a simple Kernel regression method. This method makes use of the Gaussian kernel as a weighting function.
Users have the option to use a non-repainting as well as a repainting method, see the USAGE section for more information.
🔶 USAGE
🔹 Non Repainting
When Repainting Smoothing is disabled the returned indicator acts similarly to a regular causal moving average. This result could be described as an "endpoint Nadaraya-Watson estimator".
Unlike a regular moving average whose degree of smoothness is commonly determined by the length of its calculation window, the degree of smoothness of the proposed indicator is determined by the bandwidth setting, with a higher value returning smoother results.
In the above chart, a bandwidth value of 50 is used. An increasing value of the smoother is indicative of an uptrend, while a decreasing value is indicative of a downtrend.
🔹 Repainting
Non-causal smoothing methods have found low support from technical analysts because they tend to repaint. Yet, they can provide powerful insights such as estimating underlying trends in the price as well as seeing how far prices deviate from them. They can also make drawing certain patterns easier and can help see underlying structures in the price more clearly.
Using higher bandwidth values allows for estimating longer-term trends in the price.
Triangular labels highlight points where the direction of the estimator change. This allows for the identification of tops and bottoms in the underlying trend which can be compared to the actual price tops and bottoms.
Note that multiple labels can appear in real time, highlighting real-time changes in the estimator's direction. The most recent label on a series of labels is the first to appear. This can eventually be useful for the real-time predictive application of the estimator. However, it is not a usage we particularly recommend.
🔶 DETAILS
The Nadaraya-Watson estimator can be described as a series of weighted averages using a specific normalized kernel as a weighting function. For each point of the estimator at time t , the peak of the kernel is located at time t , as such the highest weights are attributed to values neighboring the price located at time t .
A lower bandwidth value would contribute toward a more important weighting of the price at a precise point and would as such less smooth results. In the case where our bandwidth is so small that the resulting kernel is just an impulse, we would get the raw price back.
However, when the bandwidth is sufficiently large, prices would be weighted similarly, thus resulting in a result closer to the price mean.
It can be interesting to note that due to the nature of the estimator and its weighting procedure, real-time results would not deviate drastically for points in the estimator near the center of the calculation window.
🔶 SETTINGS
Bandwidth : controls the bandwidth of the Gaussian kernel, with higher values returning smoother results.
Src : Input source of the kernel regression.
Repainting Smoothing : Determine if the smoothing method should repaint or not. If disabled the "endpoint Nadaraya-Watson estimator" is returned.

Ehlers Adaptive Relative Strength Index V1 [CC]The Adaptive Relative Strength Index was created by John Ehlers and this is his first version. I will of course publish his updated version at a later date along with publishing the final script from Jim Sloman's Ocean Theory book. I have changed his script to include extra smoothing to provide clear buy and sell signals. This is a version of a RSI that is very adaptive to changes by finding the length of the current cycle and using that to calculate the rsi and I use this same basic process to provide extra smoothing. A great strategy of course is to buy right after the indicator goes from below the oversold level to right above it and stay in until the indicator turns red or when it reaches the overbought level. I have included strong buy and sell signals in addition to normal ones and the darker colors mean strong signals and lighter colors are normal signals.
Let me know what other indicators you would like to see me publish!
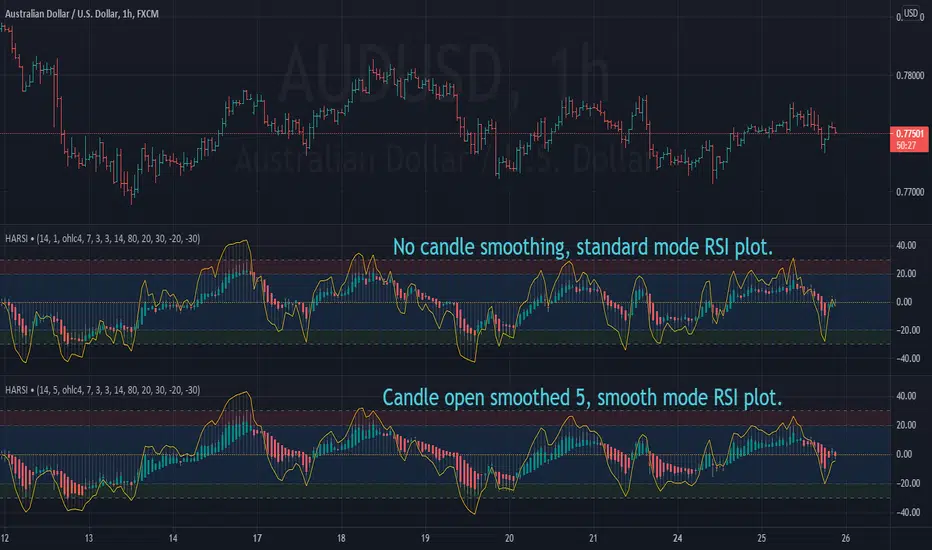
Heikin Ashi RSI OscillatorIntroducing HARSI - the RSI based Heikin Ashi candle oscillator.
...that's right, you read it correctly. This is Heikin Ashi candles in an oscillator
format derived from RSI calculations, aimed at smoothing out some of the
inherent noise seen with standard RSI indicators.
Science!
We likes it we does.
Included plot options for standard RSI plot overlay, and a smoothed variant with
it's own seperate length from the candles, oh and histogram option, for reasons.
Articles and further reading:
investopedia.com - RSI
investopedia.com - Heikin Ashi
This is a REALTIME indicator, so any values used for conditions should use
history 1, or alternatively, alerts should be called using once-per-bar-close.
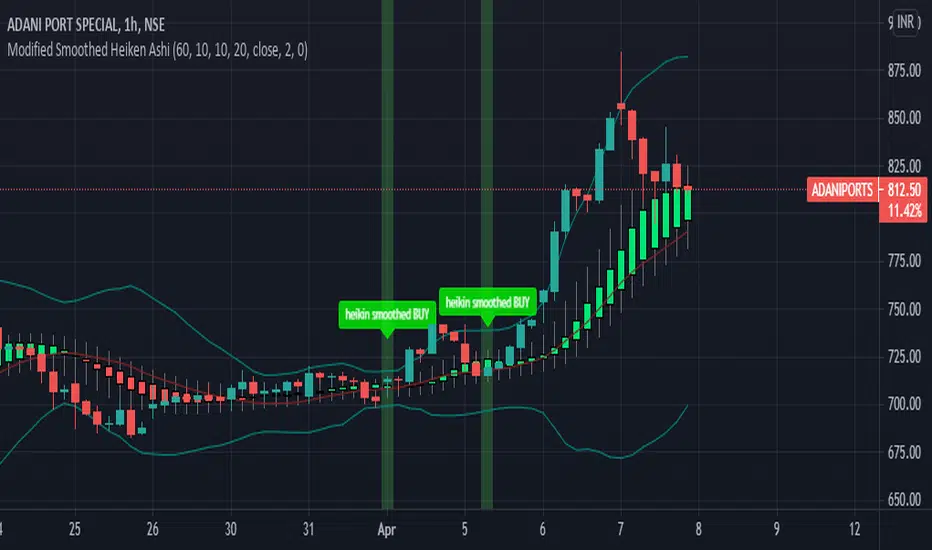
Modified Smoothed Heiken AshiThis code is based on Smoothed HA candle which will work on all chart types
condition for BUY:
1. When close crosses Smoothed HA
2.Close should be in side upper band
3.BBW must be greater than the average
vice versa for sell
this code takes data from HA chart so that it can be applied on all chart type.
Bollinger band and Bollinger band width conditions added for removal of unwanted signals
Alert added so that you can apply alert and check it in real time performance
thanks to The Secret Mindset You tube channel from where I got the idea to convert this into a pine script indicator
smooth HA taken from "Smoothed Heiken Ashi Candles v1" at //@jackvmk
SAK-MPI: Smooth DXDescription : This SwissArmyKnife - MultiPurposeIndicator allows user to modify the Directional index based on one of filtering tools proposed by John F.Ehlers .
Details of each filtering type can be read in Ehlers Technical Papers: "Swiss Army Knife Indicator" and/or his book "Cybernetics Analysis for Stock and Futures"
Disclaimer:
These study scripts was built only to test/visualize an idea to see its viability and if it can be used to optimize existing strategy.
This is experimental indicator. Any ideas to further improve this indicator are welcome :)
Blackman Filter - The Smoother The BetterIntroduction
Who doesn't like smooth things? I'd like a smooth market price for christmas! But i can't get it, instead its so noisy...so you apply a filter to smooth it, such filters are called low-pass filters, they smooth and its great but they have lag, so nobody really use them, but they are pretty to look at.
Its on a childish note that i will introduce this indicator, so what it is all about? I propose a new FIR filter using a blackman function as filter kernel for financial time-series smoothing, do you prefer the childish tone ? Fear not its surprisingly easy!
The Blackman Function
The blackman function look like a bell shaped curve, look:
The blackman function will produce such curve. This function is called a cosine sum function because she is based on the sum of cosine functions, here only 2.
0.42 - 0.5 * cos(2 * pi * k) + 0.08 * cos(4 * pi * k)
Originally you use this function for windowing , what does it means? In signal processing you have a function called sync function , if you use this function as filter kernel you would get the ideal frequency domain response filter, sometime called brickwall filter, it would be extremely smooth.
Above the optimal low pass filter frequency response.
However the sync function has no ending values and goes on forever, therefore we can't use it for convolution, expect if we apply windowing. Filters using windowing are called windowed-sinc filters, i will describe the procedure below :
1 - Create a sync function = sin(pi*n)/(pi*n)
2 - Truncate it = I only keep the first length points of the sync function.
This create a abrupt end, the frequency of a filter using step 1 as kernel would contain ripples in the pass band and stop band, this is bad! The frequency response would look like this :
3 - I multiply my values of step 2 by a window function, it can the blackman window, i no longer have an abrupt end, its smooth!
The frequency response of the filter using this kernel would no longer have ripples! This is the power of windowing functions.
Here we are not using such thing, but we could in the future. Here instead we use the blackman function as filter kernel, because this function is bell shaped this mean that the filter will certainly be smooth (symmetrical weighting is a rule of thumb for kernels when we want really smooth filters).
The Filter
This filter is quite smooth, unlike the gaussian filter this filter give less weights to recent and past values, this is because the blackman function has fatter tails than the gaussian one. I could make a comparison of both, however they are quite alike, if you often use a gaussian filter its up to you to decide which one you prefer.
The filter can do a better job than the moving average when it comes to preserve the frequency components that constitute the cycles/trend.
We can see that the filter has a greater performance when it comes to keep the shape of the market price, thus it has a slightly better fit.
Conclusion
Ok so in this post you learned a bit about the sync function and windowing, those are basic subjects in signal processing, they allow us to approximate the filter with the ideal frequency response, i also showed you that those windowing function could be used as kernel and that they where pretty smooth on their own, there are many others, but the one i prefer is the blackman windowing function.
I know what you are thinking, "we want trailing stops, alerts, colors, arrows!", and i understand you pal, but sometimes its cool to take a break from all this stuff. However i can tell that i'am working on a side project that aim to estimate rolling maximum/minimum as fast as possible, any experiments will be published here, and i can ensure you that those indicators will make your day quite brighter, we will see that soon.
I hope you learned something from this post! I'am a bit tired (look i'am disappearing !)
Thanks for reading !

Setting-Less Trend-Step FilteringIntroduction
Indicators settings have been a major concern in trading strategies, in order to provide the best results each indicators involved in the strategy must have its settings optimized, when using only 1 indicator this task can easily be achieved, but an increasing number of indicators involve more slower computations, lot of softwares will use brute force for indicators settings optimization, this involve testing each indicator settings and see which setting/combination maximize the equity, in order to fasten this process softwares can use a user defined range for the indicator settings. Nonetheless the combination that maximize the equity at time t might be different at time t+1...n .
Therefore i propose an indicator without any numerical setting that aim to filter small price variations using the architecture of the T-step lsma, such indicator can provide robust filtering and can therefore be used as input for other indicators.
Robustness Vs Non Robustness
Robustness is often defined as the ability of certain statistical tools to be less affected by outliers, outliers are defined as huge variations in a data-set, high volatility movements and large gaps might be considered as outliers. However here we define robustness as the ability of an indicator to be non affected by price variations that are not correlated with the main trend, which can be defined in technical analysis as pullbacks.
Some small pullbacks in INTEL, the indicator is not affected by them, which allow the indicator to filter the price in a "smart" way.
This effect is made possible by using exponential averaging in the indicator, exponential averaging is defined as y = sc*x + (1-sc)*y , with 1 > sc > 0 . Here sc is calculated in a similar way as the kalman gain, which is in the form of a/(a + b) , in our case this is done with :
sc = abs(input - nz(b ))/(abs(input - nz(b )) + nz(a ))
Non Robust Version Of The Indicator
The user is allowed to use the non robust version of the indicator by unchecking "robust" in the setting panel, this allow a better fit with the price at the cost of less filtering.
robust checked
robust unchecked
Conclusion
I proposed a technical indicator that aim to filter short frequencies without the use of parameters, the indicator proven to be robust to various pullbacks and therefore was able to follow the main trend, although using the term trend for such small price variations might be wrong. Removing high frequencies is always beneficial in trading, noisy series are harder to manipulate, this is why you'll see a lot of indicators using median price often defined as hl2 instead of the closing price.
Like previous settings-less indicators i published this one can behave differently depending on the time frame selected by the user, lower time frames will make the indicator filter more. I'll try to make more setting-less indicators that will correct this effect.
Acknowledgements
The support and interest of the community is only thing that allowed me to be where i'am today, i'am thankful. Special thanks to the tv staff, LucF, and my family who may not have believed in this project but are still proud of their son.

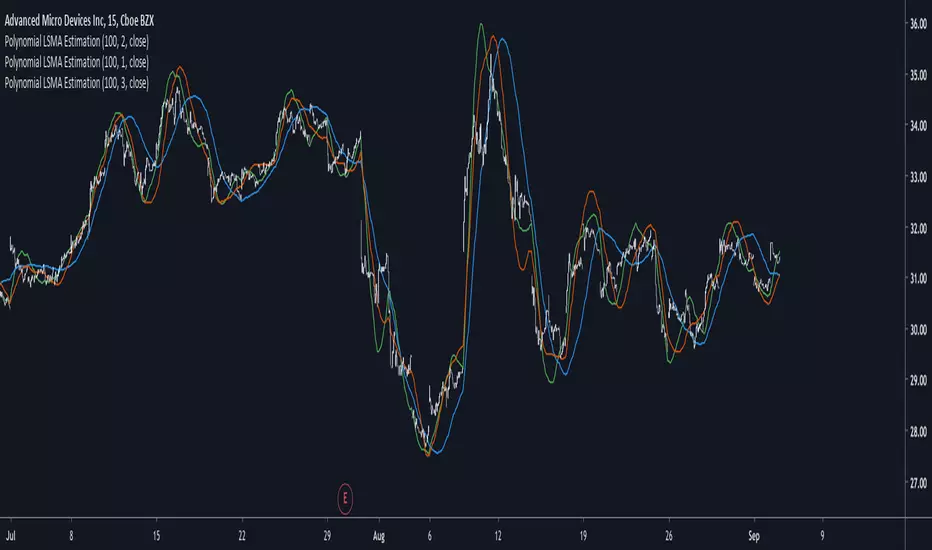
Polynomial LSMA Estimation - Estimating An LSMA Of Any DegreeIntroduction
It was one of my most requested post, so here you have it, today i present a way to estimate an LSMA of any degree by using a kernel based on a sine wave series, note that this is originally a paper that i posted that you can find here figshare.com , in the paper you will be able to find the frequency response of the filter as well as both python and pinescript code.
The least squares moving average or LSMA is a filter that best fit a polynomial function through the price by using the method of least squares, by default the LSMA best fit a line through the input by using the following formula : ax + b where x is often a linear series 1,2,3...etc and a/b are parameters, the LSMA is made by finding a and b such that their values minimize the sum of squares between the lsma and the input.
Now a LSMA of 2nd degree (quadratic) is in the form of ax^2 + bx + c , although the first order LSMA is not hard to make the 2nd order one is way more heavy in term of codes since we must find optimal values for a , b and c , therefore we may want to find alternatives if the goal is simply data smoothing.
Estimation By Convolution
The LSMA is a FIR filter which posses various characteristics, the impulse response of an LSMA of degree n is a polynomial of the same degree, and its step response is a polynomial of degree n+1, estimating those step response is done by the described sine wave series :
f(x) =>
sum = 0.
b = 0.
pi = atan(1)*4
a = x*x
for i = 1 to d
b := 1/i * sin(x*i*pi)
sum := sum + b
pol = a + iff(d == 0,0,sum)
which is simple the sum of multiple sine waves of different frequency and amplitude + the square of a linear function. We then differentiate this result and apply convolution.
The Indicator
length control the filter period while degree control the degree of the filter, higher degree's create better fit with the input as seen below :
Now lets compare our estimate with actual LSMA's, below a lsma in blue and our estimate in orange of both degree 1 and period 100 :
Below a LSMA of degree 2 (quadratic) and our estimate with degree 2 with both period 100 :
It can be seen that the estimate is doing a pretty decent job.
Now we can't make comparisons with higher degrees of lsma's but thats not a real necessity.
Conclusion
This indicator wasn't intended as a direct estimate of the lsma but it was originally based on the estimation of polynomials using sine wave series, which led to the proposed filter showcased in the article. So i think we can agree that this is not a bad estimate although i could have showcased more statistics but thats to many work, but its not that interesting to use higher degree's anyways so sticking with degree 1, 2 and 3 might be for the best.
Hope you like and thanks for reading !