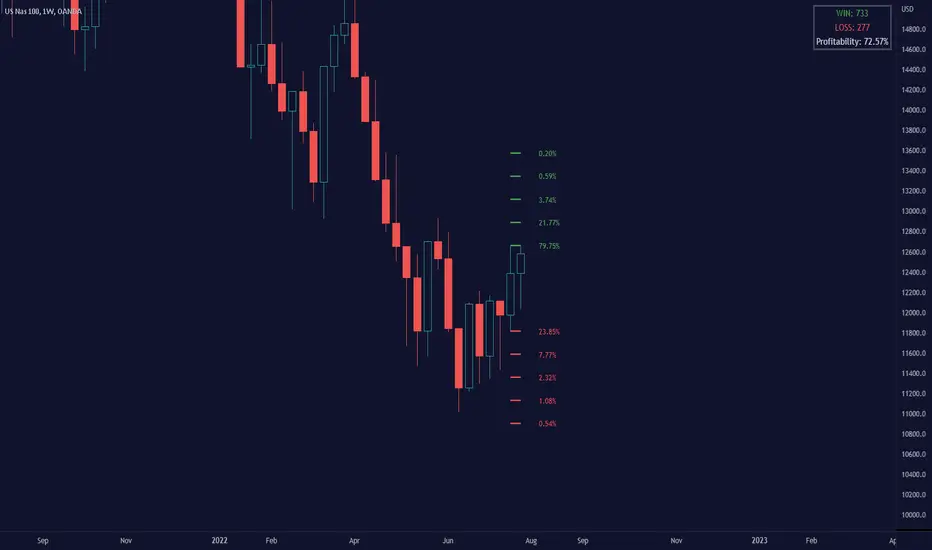
Breakout Probability (Expo)█ Overview
Breakout Probability is a valuable indicator that calculates the probability of a new high or low and displays it as a level with its percentage. The probability of a new high and low is backtested, and the results are shown in a table— a simple way to understand the next candle's likelihood of a new high or low. In addition, the indicator displays an additional four levels above and under the candle with the probability of hitting these levels.
The indicator helps traders to understand the likelihood of the next candle's direction, which can be used to set your trading bias.
█ Calculations
The algorithm calculates all the green and red candles separately depending on whether the previous candle was red or green and assigns scores if one or more lines were reached. The algorithm then calculates how many candles reached those levels in history and displays it as a percentage value on each line.
█ Example
In this example, the previous candlestick was green; we can see that a new high has been hit 72.82% of the time and the low only 28.29%. In this case, a new high was made.
█ Settings
Percentage Step
The space between the levels can be adjusted with a percentage step. 1% means that each level is located 1% above/under the previous one.
Disable 0.00% values
If a level got a 0% likelihood of being hit, the level is not displayed as default. Enable the option if you want to see all levels regardless of their values.
Number of Lines
Set the number of levels you want to display.
Show Statistic Panel
Enable this option if you want to display the backtest statistics for that a new high or low is made. (Only if the first levels have been reached or not)
█ Any Alert function call
An alert is sent on candle open, and you can select what should be included in the alert. You can enable the following options:
Ticker ID
Bias
Probability percentage
The first level high and low price
█ How to use
This indicator is a perfect tool for anyone that wants to understand the probability of a breakout and the likelihood that set levels are hit.
The indicator can be used for setting a stop loss based on where the price is most likely not to reach.
The indicator can help traders to set their bias based on probability. For example, look at the daily or a higher timeframe to get your trading bias, then go to a lower timeframe and look for setups in that direction.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!
Indikatoren und Strategien
Point of Control V2 The genesis of this project was to create a POC library that would be available to deliver volume profile information via pine to other scripts of indicators and strategies.
This is a republish of an invite only script to open access
This is the indicator version of the library function.
A few points of significance:
- Allows the choice of reset of the study period, day/week or bars. This is simple enough to expand to other conditions
- Bar count resets starting from the beginning of the data set (bar index =0) vs bars back from the end of the data set
- A 'period' in this context is the time between resets - the start of the POC (eg. start of Day or Week) until it resets (for example at the beginning of a next day or week)
- Automates the determination of the increment level rather than the user specifying ticks or price brackets
- Does not allow for setting the # of rows and then calculating the implied price increment levels
- When a period is complete it is often useful to look back at the POCs of historical periods, or extend them forward.
- This script will find the historical POCs around the current price and display them rather than extend all the historical POC lines to the right
- This script also looks across all the period POCs and identifies the master POC or what I call the Grand POC, and also the next 3 runner up POCs
This indicator is also available as a library.
BINANCE:BTCUSDT NSE:NIFTY OANDA:XAUUSD NASDAQ:AAPL TVC:USOIL

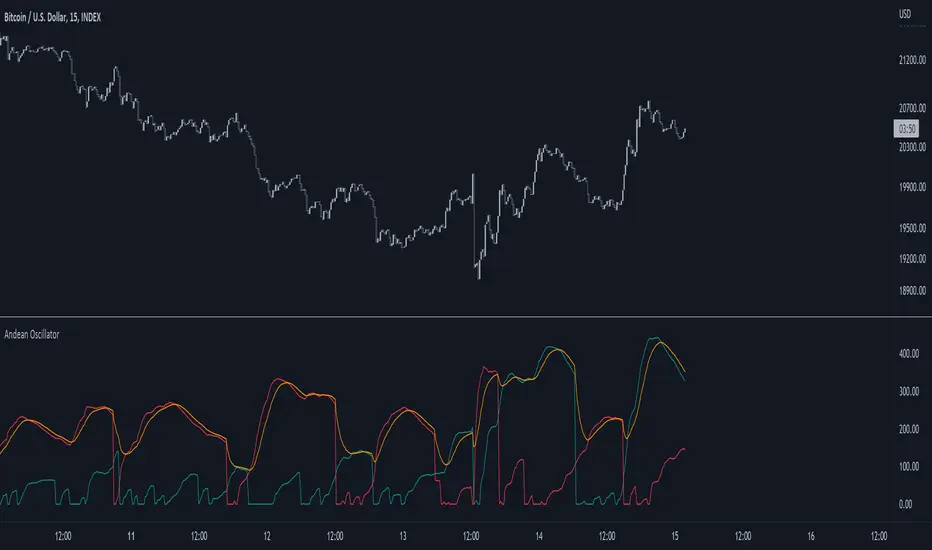
Andean OscillatorThe following script is an original creation originally posted on the blog section of the broker Alpaca.
The proposed indicator aims to measure the degree of variations of individual up-trends and down-trends in the price, thus allowing to highlight the direction and amplitude of a current trend.
Settings
Length : Determines the significance of the trends degree of variations measured by the indicator.
Signal Length : Moving average period of the signal line.
Usage
The Andean Oscillator can return multiple information to the user, with its core interpretation revolving around the bull and bear components.
A rising bull component (in green) indicates the presence of bullish price variations while a rising bear component (in red) indicates the presence of bearish price variations.
When the bull component is over the bear component market is up-trending, and the user can expect new higher highs. When the bear component is over the bull component market is down-trending, and the user can expect new lower lows.
The signal line (in orange) allows a more developed interpretation of the indicator and can be used in several ways.
It is possible to use it to filter out potential false signals given by the crosses between the bullish and bearish components. As such the user might want to enter a position once the bullish or bearish component crosses over the signal line instead.
Details
Measuring the degree of variations of trends in the price by their direction (up-trend/down-trend) can be done in several way.
The approach taken by the proposed indicator makes use of exponential envelopes and the naive computation of standard deviation.
First, exponential envelopes are obtained from both the regular prices and squared prices, thus giving two upper extremities, and two lower extremities.
The bullish component is obtained by first subtracting the upper extremity of the squared prices with the squared upper extremity of regular prices, the square root is then applied to this result.
The bearish component is obtained in the same way, but makes use of the lower extremities of the exponential envelopes.
Auto Trendline Indicator (based on fractals)A tool that automatically draws out trend lines by connecting the most recent fractals.
Description:
The process of manual drawing out trend lines is highly subjective. Many times, we don’t trade what we see, but what we “want to see”. As a result, we draw lines pointing to the direction that we wishfully want price to move towards. While there are no right/wrong ways to draw trend lines, there are, however, systematic/unsystematic ways to draw trend lines. This tool will systematically draw out trend lines based on fractals.
Additional feature:
This tool will also plot out symbols (default symbol “X”) to signify points of crossings. This can be useful for traders considering to use trend lines as part of their trading strategies.
Here is an interesting observation on the price actions of NASDAQ futures on a 5 second chart during regular trading hours on July 14, 2022.
It’s a phenomenon. People like to see straight lines connecting HL/LH, etc., so it's possible for the market as a whole to psychologically react to these lines. However, it is important to note that is is impossible to predict the direction of price. In the case above, price could have tanked below auto-drawn trend line. Fractal based trend lines should only be taken as references and regarded as price levels. No studies have ever proven that the slope of trend lines can indicate price's future direction.
More about fractals:
To understand more about fractals:
www.investopedia.com
www.tradingview.com
Contrary to what it sounds like, fractal in "technical analysis" does not refer to the recursive self-repeating patterns that appear in nature, such as the mesmerizing patterns found in snowflakes. The Fractal Markets Hypothesis claims that market prices exhibit fractal properties over time. Assuming this assertion to be true, then fractals can be used a tool to represent the chaotic movements of price is a simplified manner.
The purpose of this exercise is to take a tool that is readily available (ie. in this case, TradingView’s built-in fractals tool), and to create a newer tool based on it.
Parameters:
Fractal period (denoted as ‘n’ in code): It is the number of bars bounding a high/low point that must be lower/higher than it, respectively, in order for fractal to be considered valid. Period ‘n’ can be adjusted in this tool. Traditionally, chartists pick the value of 5. The longer it is, the less noise seen on the chart, and the pivot point may also be exhibited in higher timeframes. The drawback is that it will increase the period of lag, and it will take more bars to confirm the printed fractal.
Others: Intuitive parameters such as whether to draw historical trend lines, what color to use, which way to extend the lines, and whether or not to show points of crossings.

Chart VWAP█ OVERVIEW
This indicator displays a Volume-Weighted Average Price anchored to the leftmost visible bar of the chart. It dynamically recalculates when the chart's visible bars change because you scroll or zoom your chart.
If you are not already familiar with VWAP, our Help Center will get you started. The typical VWAP is designed to be used on intraday charts, as it resets at the beginning of the day. Our Rolling VWAP , instead, resets on a rolling time window. You may also find the VWAP Auto Anchored built-in indicator worth a try.
█ HOW TO USE IT
Load the indicator on an active chart (see the Help Center if you don't know how). By default, it displays the chart's VWAP in orange and a simple average of the chart's visible close values in gray. This average can be used as a companion to the VWAP, since both are calculated from the same set of bars. The script's settings allow you to hide it.
You may also use the script's settings to enable the display of the chart's OHLC (open, high, low, close) levels and the values of the high and low. These are also calculated from the range of visible bars. You can complement the high and low lines with their price and their distance in percent from the chart's latest visible close . You can use the levels to quickly identify the distances from extreme points in the visible price range, as well as observe the visible chart's beginning and end prices.
█ NOTES FOR Pine Script™ CODERS
This script showcases three novelties:
• Dynamic recalculation on visible bars
• The VisibleChart library by PineCoders
• The new `anchor` parameter of ta.vwap()
Dynamic recalculation on visible bars
This script behaves in a novel way made possible by the recent introduction of two new built-in variables: chart.left_visible_bar_time and chart.right_visible_bar_time , which return the opening time of the leftmost and rightmost visible bars on the chart. These are only two of many new built-ins in the `chart.*` namespace. See this blog post for more information, or look up them up by typing "chart." in the Pine Script™ Reference Manual .
Any script using chart.left_visible_bar_time or chart.right_visible_bar_time acquires a unique property, which triggers its recalculation when traders scroll or zoom their chart, causing the range of visible bars to change. This new capability is what makes it possible for this script to calculate its VWAP on the chart's visible bars only, and dynamically recalculate if the user scrolls or zooms their chart.
This script is just a start to the party; endless uses for indicators that redraw on changes to the chart will no doubt emerge through the hands of our community's Pine Script™ programmers.
The VisibleChart library by PineCoders
The newly published VisibleChart library is designed to help programmers benefit from the new capabilities made possible by the fact that Pine Script™ code can now tell when it is executing on visible bars. The library's description, functions and example code will help programmers make the most of the new feature.
This script uses three of the library's functions:
• `PCvc.vVwap()` calculates a VWAP for visible bars.
• `PCvc.avg()` calculates the average of a source value for visible bars only. We use it to calculate the average close (the default source).
• `PCvc.chartXTimePct(25)` calculates a time value corresponding to 25% of the horizontal distance between visible bars, starting from the left.
The new `anchor` parameter of ta.vwap()
Our script also uses this new `anchor` parameter to reset the VWAP at the leftmost visible bar. See how simple the code is for the VisibleChart library's `vVwap()` function.
Look first. Then leap.

Ichimoku Kinkō hyō 目均衡表█ OVERVIEW
Ichimoku is known to be an Indicator that completes itself, for its power but also for its complexity. This is why I decided to improve the work of
Goichi Hosoda in order to offer the maximum number of options for the most seasoned users but also beginners with options to simplify the
reading of Ichimoku (such as a panel directly giving you the status of each Ichimoku options or Supports/Resistances drawn automatically
according to the conditions chosen in the settings.
█ OPTIONS
Here is the complete list of options to implement :
- "Source" and "Alternative Source" (with lots of choices)
- Heikin Ashi volume.
- Weighted Moving Average Smoothing
- Minimum, Maximum and Adaptive Percentage Length adjustable for Tenkan-Sen, Kijun-Sen, Chikou Span and Senkou-Span)
- The Chikou has a Filter with modifiable Length (in Lookback Percentage)
- Advanced Filter Settings: Volume, Tenkan-Sen/Kijun-Sen Cross, Volatility, Tenkan-Sen Equal Kijun-Sen, Chikou Greater Than Price,
Chikou Momentum, Price Greater Than Kumo, Price Greater Than Tenkan-Sen, Chikou Trend Filter .
- Oscillator volume adjustable via drop-down menu with 5 types of oscillators available: "TFS Volume", "On Balance Volume",
"Klinger Volume", "Cumulative Volume", "Volume Zone".
- Relative Volume Strength Index with Length, Peak and EMA's adjustable. 3 Oscillators available: “On Balance Volume”,
“Cumulative Volume”, “Price Volume Trend”.
- Volatility adjustable with Fast and Slow Length.
- Totally customizable Support and Resistance.
- Bar Trend Color based on chosen settings.
- Fully customizable help panel.
- Alerts available for: Labels Detection, Support/Resistance Line Cross, Panel Trend Status Direction.
█ NOTES
Remember to only make a decision once you are sure of your analysis. Good trading sessions to everyone and don't forget,
risk management remains the most important!

Traling.SL.TargetTrailing SL and Target
I have seen few requests in PineScripters telegram group asking questions about implementation of trailing stop-loss (SL) and targets. This script is one of the way to implement the same.
This script is developed based on dark color theme and is best viewed using dark color theme.
How and where can this script be used:
The script is built to demonstrate how one can implement the trailing SL and target, so by referring the script one can mimic the approach and add trailing SL and target implementation in their own strategy.
How it works:
To demonstrate the SL and target implementation, i have considered simple EMA crossover strategy.
Key Input Parameters
Method to use for SL/Target trailing:
1. % Based Target and SL - Used to calculate trailing based on parameters defined under group '% Based Target SL'
2. Fixed point Based Target and SL - Used to calculate trailing based on parameters defined under group 'Fixed point Based Target and SL'
% Based Target and SL:
Initial profit % - This is used to calculate target when trade is initiated
Initial SL % - This is used to calculate SL when trade is initiated
Initiate trailing % - This parameter determines, when to start trailing SL and target.
Trail profit by % - Target would be trailed by % specified as this parameter
Trail SL by % - SL would be trailed by % specified as this parameter
e.g.
Trade type: - Long
Trade price: 10000
initial profit %: 1
Initial SL %: 1
Initiate trailing %: 0.5
Trail profit by %: 0.3
Trail SL by %: 0.4
Calculations based on above:
initial profit %: 10100 (trade price + 1%)
Initial SL %: 9900 (trade price - 1%)
Initiate trailing %: 10049.5 (initial profit - 0.5%)
Trail profit by %: 10130 (initial profit + 0.3%)
Trail SL by %: 9939.6 (initial SL + 0.4%)
For next iteration of Trailing SL and target above calculated values will be taken as a base and next set of values will be calculated. these calculations will continue till the trade is exited either on price reaching profit or SL point.
Fixed point Based Target and SL:
Initial profit target points - To derive initial target, parameter value is added to trade price in case of long trade.
Initial SL points - To derive SL point, parameter value is subtracted from trade price
Initiate trailing points - To derive start of trailing logic, parameter value is subtracted from initial profit point.
Trail profit by points - In case of long trade, parameter value is added to the profit target to derive new trailed profit target.
Trail SL by % - In case of long trade, parameter value is added to the SL initial point to derive new trailed SL.
Calculation of Trailing SL and target will continue till the trade is exited either on price reaching profit or SL point.
Plots displayed on the chart:
Apart from default trade markings i have added 3 shapes on the chart to describe working of Trailing SL and targets.
Diamond shape marks - These are added on the chart when trade is initiated. These shapes gives additional trade information by way of 'tooltip'. This information can be viewed by placing mouse pointer on the shape.
Circle shape marks - These are added on the chart whenever Trailing SL and targets are calculated. These shapes gives additional trade information by way of 'tooltip'. This information can be viewed by placing mouse pointer on the shape. You will also notice a number displayed just above or below circle denoting Trailing iteration.
Labels up and label down shapes - These are dynamically placed on the chart whenever trade is in progress. These labels will display ongoing trades, Target and SL points.

Market Structure Break & Order Block by EmreKbThis indicator shows the market structure break (msb) and order blocks (ob). Msb occurs after the breakout old high when the price make lower lows or occurs after the breakout old low when the price make higher highs. OB occurs after the msb, ob is the last bullish candle before high if msb is bearish but if the msb is bullish then ob is the last bearish candle before low.
Zigzag Lenght - A number for the zigzag calculation
Show Zigzag - Show/Hide Zigzag lines
Fib Factor - Fib level for the breakout confirmation. For example if new high larger than old high to low fib 1+fib_factor when the down trend then it's a breakout.

Template Trailing Strategy (Backtester)💭 Overview
+ Title: Template Trailing Strategy (Backtester)
+ Author: Iason Nikolas (jason5480)
+ License: CC BY-NC-SA 4.0
💢 What is the "Template Trailing Strategy (Backtester)" ❓
The "Template Trailing Strategy (Backtester)" (TTS) is a back-tester orchestration framework. It supercharges the implementation-test-evaluation lifecycle of new trading strategies, by making it possible to plug in your own trading idea.
While TTS offers a vast number of configuration settings, it primarily allows the trader to:
Test and evaluate your own trading logic that is described in terms of entry, exit, and cancellation conditions.
Define the entry and exit order types as well as their target prices when the limit, stop, or stop-limit order types are used.
Utilize a variety of options regarding the placement of the stop-loss and take-profit target(s) prices and support for well-known techniques like moving to breakeven and trailing.
Provide well-known quantity calculation methods to properly handle risk management and easily evaluate trading strategies and compare them.
Alert on each trading event or any related change through a robust and fully customizable messaging system.
All of the above makes TTS a practical toolkit: once you learn it, many repetitive tasks that strategy authors usually re-implement are eliminated. Using TradingView’s built-in backtesting engine makes testing and comparing ideas straightforward.
By utilizing the TTS one can easily swap "trading logic" by testing, evaluating, and comparing each trading idea and/or individual component of a strategy.
Finally, TTS, through its per-event alert management (and debugging) system, provides an automated solution that supports live trading with brokers via webhooks.
NOTE: The "Template Trailing Strategy (Backtester)" does not dictate how you can combine different indicator types. Thus, it should not be confused as a "Trading System", because it gives its user full flexibility on that end (for better or worse).
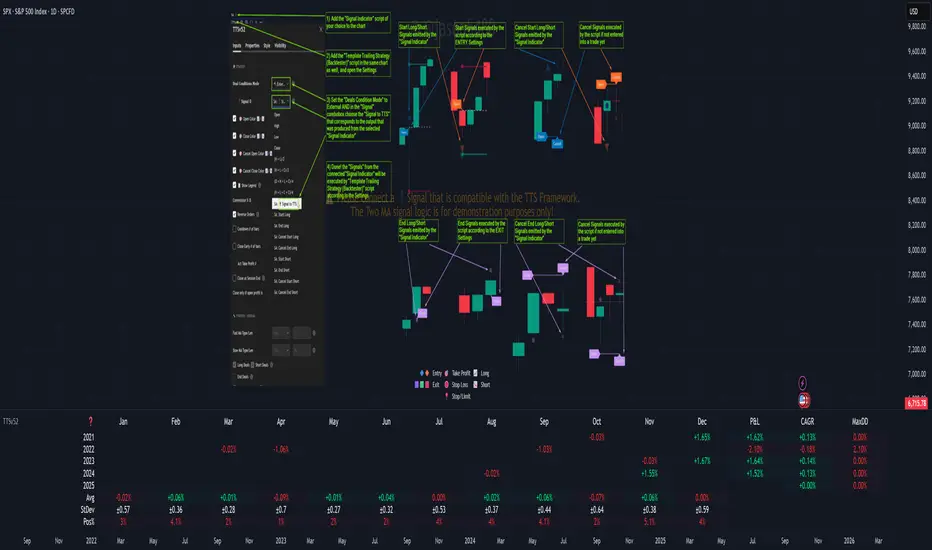
💢 What is a "Signal Indicator" ❓
"Signal Indicator" (SI) is an indicator that can output a "signal" that follows a specific convention so that the "Template Trailing Strategy (Backtester)" can "understand" and execute the orders accordingly. The SI realizes the core trading logic signaling to the TTS when to enter, exit, or cancel an order. A SI instructs the TTS "when" to enter or exit, and the TTS determines "how" to enter and exit the position once the Signal Indicator generates a signal.
A very simple example of a Signal Indicator might be a 200-day Simple Moving Average Signal. When the price of the security closes above the 200-day SMA, a SI would provide TTS with a "long entry signal". Once TTS receives the "long entry signal", the TTS will open a long position and send an alert or automated trade message via webhook to a broker, based on the Entry settings defined in TTS. If the TTS Entry settings specify a "Market" order type, then the open long position will be executed by TTS immediately. But if the TTS Entry settings specify a "Stop" order type with a 1% Stop Distance, then when the price of the security rises by 1% after the "long entry signal" occurs, the TTS will open a long position and the Long Entry alert or webhook to the broker will be sent.
🤔 How to Guide
💢 How to connect a "signal" from a "Signal Indicator" ❓
The "Template Trailing Strategy (Backtester)" was designed to receive external signals from a "Signal Indicator". In this way, a "new trading idea" can be developed, configured, and evaluated separately from the TTS. Similarly, the SI can be held constant, and the trading mechanics can change in the TTS settings and back-tested to answer questions such as, "Am I better with a different stop loss placement method, what if I used a limit order instead of a stop order to enter, what if I used 25% margin instead of trading spot market?"
To make that possible by connecting an external signal indicator to TTS, you should:
Add both your SI (e.g. "Two MA Signal Indicator" , "Click Signal Indicator" , "Signal Adapter" , "Signal Composer" ) and the TTS script to the same chart.
Open the script's Settings / Inputs dialog for the TTS.
In the 🛠️ STRATEGY group set 𝐃𝐞𝐚𝐥 𝐂𝐨𝐧𝐝𝐢𝐨𝐧𝐬 𝐌𝐨𝐝𝐞 to 🔨External (this makes TTS listen to an external signal source).
Still inside 🛠️ STRATEGY locate the 🔌𝐒𝐢𝐠𝐧𝐚𝐥 🛈 input and choose the plotted output of your SI. The option should look like: "<SI short title>:🔌Signal to TTS" .
Verbose troubleshooting & tips
If the SI does not appear in the 🔌Signal 🛈 selector, confirm both scripts are added to the same chart and the SI exposes a plotted series (title often "🔌Signal to TTS").
When using multiple SIs, pick the SI instance that actually outputs the "🔌Signal to TTS" plotted series.
Validate on the chart: when your SI changes state, the plotted "🔌Signal" series in the TTS (visible in the data window) should change accordingly.
The TTS accepts only signals that follow the tts_convention DealConditions structure. Do not attempt to feed arbitrary scalar series without using conv.getDealConditions / conv.DealConditions.
Make sure your SI composes a DealConditions value following the TTS convention (startLong, endLong, startShort, endShort — optional cancel fields). See the template below.
If the plot is present but TTS does not react, ensure the SI plot is non-repainting (or accept realtime/backtest limitations). Test on historical bars first.
Create alerts on the strategy (see the Alerts section). Use the {{strategy.order.alert_message}} placeholder in the Create Alert dialog to forward TTS messages.
💢 How to create a custom trading logic ❓
The "Template Trailing Strategy (Backtester)" provides two ways to plug in your custom trading logic. Both of them have their advantages and disadvantages.
✍️ Develop your own Customized "Signal Indicator" 💥
The first approach is meant to be used for relatively more complex trading logic. The advantages of this approach are the full control and customization you have over the trading logic and the relatively simple configuration setup by having two scripts only. The downsides are that you have to have some experience with pinescript or you are willing to learn and experiment. You should also know the exact formula for every indicator you will use since you have to write it by yourself. Copy-pasting from existing open-source indicators will get you started quite fast though.
The idea here is either to create a new indicator script from scratch or to copy an existing non-signal indicator and make it a "Signal Indicator". To create a new script, press the "Pine Editor" button below the chart to open the "Pine Editor" and then press the "Open" button to open the drop-down menu with the templates. Select the "New Indicator" option. Add it to your chart to copy an existing indicator and press the source code {} button. Its source code will be shown in the "Pine Editor" with a warning on top stating that this is a read-only script. Press the "create a working copy". Now you can give a descriptive title and a short title to your script, and you can work on (or copy-paste) the (other) indicators of your interest. Once you have the information needed to decide, define a DealConditions object and plot it like this:
import jason5480/tts_convention/ as conv
// Calculate the start, end, cancel start, cancel end conditions
dealConditions = conv.DealConditions.new(
startLongDeal = ,
startShortDeal = ,
endLongDeal = ,
endShortDeal = ,
cnlStartLongDeal = ,
cnlStartShortDeal = ,
cnlEndLongDeal = ,
cnlEndShortDeal = )
// Use this signal in scripts like "Template Trailing Strategy (Backtester)" and "Signal Composer" that can utilize its value
// Emit the current signal value according to the TTS framework convention
plot(series = conv.getSignal(dealConditions), title = '🔌Signal to TTS', color = #808000, editable = false, display = display.data_window + display.status_line, precision = 0)
You should import the latest version of the tts_convention library and write your deal conditions appropriately based on your trading logic and put them in the code section shown above by replacing the "…" part after "=". You can omit the conditions that are not relevant to your logic. For example, if you use only market orders for entering and exiting your positions the cnlStartLongDeal, cnlStartShortDeal, cnlEndLongDeal, and cnlEndShortDeal are irrelevant to your case and can be safely omitted from the DealConditions object. After successfully compiling your new custom SI script add it to the same chart with the TTS by pressing the "Add to chart" button. If all goes well, you will be able to connect your "signal" to the TTS as described in the "How to connect a "signal" from a "Signal Indicator"?" guide.
🧩 Adapt and Combine existing non-signal indicators 💥
The second approach is meant to be used for relatively simple trading logic. The advantages of this approach are the lack of pine script and coding experience needed and the fact that it can be used with closed-source indicators as long as the decision-making part is displayed as a line in the chart. The drawback is that you have to have a subscription that supports the "indicator on indicator" feature so you can connect the output of one indicator as an input to another indicator. Please check if your plan supports that feature here
To plug in your own logic that way you have to add your indicator(s) of preference in the chart and then add the "Signal Adapter" script in the same chart as well. This script is a "Signal Indicator" that can be used as a proxy to define your custom logic in the CONDITIONS group of the "Settings/Inputs" tab after defining your inputs from your preferred indicators in the VARIABLES group. Then a "signal" will be produced, if your logic is simple enough it can be directly connected to the TTS that is also added to the same chart for execution. Check the "How to connect a "signal" from a "Signal Indicator"?" in the "🤔 How to Guide" for more information.
If your logic is slightly more complicated, you can add a second "Signal Adapter" in your chart. Then you should add the "Signal Composer" in the same chart, go to the SIGNALS group of the "Settings/Inputs" tab, and connect the "signals" from the "Signal Adapters". "Signal Composer" is also a SI so its composed "signal" can be connected to the TTS the same way it is described in the "How to connect a "signal" from a "Signal Indicator"?" guide.
At this point, due to the composability of the framework, you can add an arbitrary number (bounded by your subscription of course) of "Signal Adapters" and "Signal Composers" before connecting the final "signal" to the TTS.
💢 How to set up ⏰Alerts ❓
The "Template Trailing Strategy (Backtester)" provides a fully customizable per-event alert mechanism. This means that you may have an entirely different message for entering and exiting into a position, hitting a stop-loss or a take-profit target, changing trailing targets, etc. There are no restrictions, and this gives you great flexibility.
First enable the events you want under the "🔔 ALERT MESSAGES" module. Each enabled event exposes a text area where you can craft the message using placeholders that TTS replaces with actual values when the event occurs.
The placeholder categories (exact names used by the script) are:
Chart & instrument:
{{ticker}}
{{base_currency}}
{{quote_currency}}
Entry / exit / stop / TP prices & offsets:
{{entry_price}}
{{exit_price}}
{{stop_loss_price}}
{{take_profit_price_1}} ... {{take_profit_price_5}}
{{entry+_price}}, {{entry-_price}}, {{exit+_price}}, {{exit-_price}} — Optional offset helpers (computed using "Offset Ticks")
Quantities, percents & derived quantities:
{{entry_base_quantity}} — base units at entry (e.g. BTC)
{{entry_quote_quantity}} — quote amount at entry (e.g. USD)
{{risk_perc}} — % of capital risked for that entry (multiplied by 100 when "Percentage Range " is enabled)
{{remaining_quantity_perc}} — % of the initial position remaining at close/SL
{{remaining_base_quantity}} — remaining base units at close/SL
{{take_profit_quantity_perc_1}} ... {{take_profit_quantity_perc_5}} — % sold/bought at each TP
{{take_profit_base_quantity_1}} ... {{take_profit_base_quantity_5}} — base units closed at each TP
❗ Important: the per-event alert text is injected into the Create Alert dialog using TradingView's strategy placeholder:
{{strategy.order.alert_message}}
During the creation of a strategy alert, make sure the placeholder {{strategy.order.alert_message}} exists in the "Message" box. TradingView will substitute the per-event text you configured and enabled in TTS Settings/Inputs before sending it via webhook/notification.
Tip: For webhook/broker execution, set the proper "Condition" in the Create Alert dialog (for changing-entry/exit/SL notifications use "Order fills and alert() function calls" or "alert() function calls only" as appropriate).
💢 How to execute my orders in a broker ❓
To execute your orders in a broker that supports webhook integration, you should enable the appropriate alerts in the "Template Trailing Strategy (Backtester)" first (see the "How to set up Alerts?" guide above). Then you should go to the "Create Alert/Notifications" tab check the "Webhook URL" and paste the URL provided by your broker. You have to read the documentation of your broker for more information on what messages are expected.
Keep in mind that some brokers have deep integration with TradingView so a per-event alert approach might be overkill.
📑 Definitions
This section tries to give some definitions in terms that appear in the "Settings/Inputs" tab of the "Template Trailing Strategy (Backtester)"
💢 What is Trailing ❓
Trailing is a technique where a price target follows another "barrier" price (usually high or low) by trying to keep a maximum distance from the "barrier" when it moves in only one direction (up or down). When the "barrier" moves in the other direction the price target will not change. There are as many types of trailing as price targets, which means that there are entry trailing, exit trailing, stop-loss trailing, and take-profit trailing techniques.
💢 What is a Moonbag ❓
A Moonbag in a trade is the quantity of the position that is reserved and will not be exited even if all take-profit targets defined in the strategy are hit, the quantity will be exited only if the stop-loss is hit or a close signal is received. This makes the stop-loss trailing technique in a trend-following strategy a good candidate to take advantage of a Moonbag.
💢 What is Distance ❓
Distance is the difference between two prices.
💢 What is Bias ❓
Bias is a psychological phenomenon where you make decisions based on market sentiment. For example, when you want to enter a long position you have a long bias, and when you want to exit from the long position you have a short bias. It is the other way around for the short position.
💢 What is the Bias Distance of a price target ❓
The Bias Distance of a price target is the distance that the target will deviate from its initial price. The direction of this deviation depends on the bias of the market. For example, suppose you are in a long position, and you set a take-profit target to the local highest high. In that case, adding a bias distance of five ticks will place your take-profit target 5 ticks below this local highest high because you have a short bias when exiting a long position. When the bias is long the bias distance will be added resulting in a higher target price and when you have a short bias the bias distance will be subtracted.
⚙️ Settings
In the "Settings/Inputs" tab of the "Template Trailing Strategy (Backtester)", you can find all the customizable settings that are provided by the framework. The variety of those settings is vast; hence we will only scratch the surface here. However, for every setting, there is an information icon 🛈 where you can learn more if you mouse over it. The "Settings/Inputs" tab is divided into ten main groups. Each one of them is responsible for one module of the framework. Every setting is part of a group that is named after the module it represents. So, to spot the module of a setting find the title that appears above it comes with an emoji and uppercase letters. Some settings might have the same name but belong to different modules e.g. "Tgt Dist Mtd" (Target Distance Method). Some settings are indented, which means that they are closely related to the non-indented setting above. Usually, indented settings provide further configuration for one or more options of the non-indented setting above. The groups that correspond to each module of the framework are the following:
🗺️ Quick Module Cross-Reference (use emojis to jump to setting groups)
📆 FILTERS — session, date & weekday filters
🛠️ STRATEGY — internal vs external deal-conditions; pick the signal source
🔧 STRATEGY – INTERNAL — built-in Two MA logic for demonstration purposes
🎢 VOLATILITY — ATR / StDev update modes
🔷 ENTRY — entry order types & trailing
🎯 TAKE PROFIT — multi-step TP and trailing rules
🛑 STOP LOSS — stop placement, move-to-breakeven, trailing
🟪 EXIT — exit order types & cancel logic
💰 QUANTITY/RISK MANAGEMENT — position sizing, moonbag, limits
📊 ANALYTICS — stats, streaks, seasonal tables
🔔 ALERT MESSAGES — per-event alert templates & placeholders
😲 Caveats
💢 Does "Template Trailing Strategy (Backtester)" have repainting behavior? ❓
The answer is that the "Template Trailing Strategy (Backtester)" does not repaint as long as the "Signal Indicator" that is connected also does not repaint. If you developed your own SI make sure that you understand and know how to prevent this behavior. The publication by @PineCoders here will give you a good idea on how to avoid most of the repainting cases.
⚠️ There is an exception though, when the "Enable Trail⚠️💹" checkbox is checked, the Take Profit trailing feature is enabled, and a tick-based approach is used, meaning that after a while, when the TradingView discards all the real-time data, assumptions will be made by the backtesting engine that will cause a form of repainting. To avoid making false assumptions please disable this feature in the early stages and evaluate its usefulness in your strategy later on, after first confirming the success of the logic without this feature. In this case, consider turning on the bar magnifier feature. This way you will get more accurate backtest results when the Take Profit trailing feature is enabled.
💢 Can "Template Trailing Strategy (Backtester)" satisfy all my trading strategies ❓
While this framework can satisfy quite a large number of trading strategies there are cases where it cannot do so. For example, if you have a custom logic for your stop-loss or take-profit placement, or if you want to dollar cost average, then it might be better to start a new strategy script from scratch.
⚠️ It is not recommended to copy the official TTS code and start developing unless you are a Pine wizard! Even in that case, there is a stiff learning curve that might not be worth your time. Last, you must consider that I do not offer support for customized versions of the TTS script and if something goes wrong in the process you are all alone.
💝 Support & Feedback
For feedback, bug reports, or feature requests, contact me via TradingView PM or use the script comments.
Note: The author's personal links and contact are available on the TradingView profile.
🤗 Thanks
Special thanks to the welcoming community members, who regularly gave feedback all those years and helped me to shape the framework as it is today! Thanks everyone who contributed by either filing a "defect report" or asking questions that helped me to understand what improvements were necessary to help traders.
Enjoy!
Jason
TASC 2022.07 Pairs Rotation With Ehlers Loops█ OVERVIEW
TASC's July 2022 edition of Traders' Tips includes an article by John Ehlers titled "Pairs Rotation With Ehlers Loops". This is the code that implements the Ehlers Loops applied to pairs rotation trading.
█ CONCEPTS
John Ehlers developed Ehlers loops as a tool to visualize the performance of one data stream versus another. Initially, he used this tool to chart price versus volume. However, Ehlers loops proved to be suitable for determining the timing of the pairs rotation strategy . This strategy works by having a long position in only one of two securities, depending on which one is considered stronger at a given time.
When the prices of two securities (filtered and scaled with a standard deviation for consistent presentation) are plotted against each other, the curvature and direction of rotation on the chart can help guide decisions on long positions. For example, when plotting a stock versus a referenced symbol, a vertical upward movement while rotating clockwise is a sign of going long the stock. Similarly, a horizontal movement to the right while rotating counterclockwise is the sign to go long the reference. A higher probability of a reversal is expected when the price moves more than one or two standard deviations.
█ CALCULATIONS
The script uses the following steps to calculate the Ehlers Loops:
The price data of both securities in the pair are individually filtered using identical high-pass and SuperSmoother filters. This results in two band-limited data streams, having a nominally zero mean. The input parameters Low-Pass Period and High-Pass Period control the filter bandwidth and thus can modify the shape of the Ehlers Loops.
Subsequently, the filtered data streams are scaled in terms of standard deviation by dividing each of them by their root-mean-square (RMS) values. These data streams are plotted as zero-mean oscillators.
Finally, the scaled data streams are displayed one against another for the selected time interval (defined by the input parameter Loop Segments ). In the resulting scatterplot, the thicker line corresponds to the later data points. The fluctuations of the filtered price data of the chart symbol are plotted along the y -axis, and the price changes of the referenced symbol are shown along the x -axis.

CVD - Cumulative Volume Delta Candles█ OVERVIEW
This indicator displays cumulative volume delta in candle form. It uses intrabar information to obtain more precise volume delta information than methods using only the chart's timeframe.
█ CONCEPTS
Bar polarity
By bar polarity , we mean the direction of a bar, which is determined by looking at the bar's close vs its open .
Intrabars
Intrabars are chart bars at a lower timeframe than the chart's. Each 1H chart bar of a 24x7 market will, for example, usually contain 60 bars at the lower timeframe of 1min, provided there was market activity during each minute of the hour. Mining information from intrabars can be useful in that it offers traders visibility on the activity inside a chart bar.
Lower timeframes (LTFs)
A lower timeframe is a timeframe that is smaller than the chart's timeframe. This script uses a LTF to access intrabars. The lower the LTF, the more intrabars are analyzed, but the less chart bars can display CVD information because there is a limit to the total number of intrabars that can be analyzed.
Volume delta
The volume delta concept divides a bar's volume in "up" and "down" volumes. The delta is calculated by subtracting down volume from up volume. Many calculation techniques exist to isolate up and down volume within a bar. The simplest techniques use the polarity of interbar price changes to assign their volume to up or down slots, e.g., On Balance Volume or the Klinger Oscillator . Others such as Chaikin Money Flow use assumptions based on a bar's OHLC values. The most precise calculation method uses tick data and assigns the volume of each tick to the up or down slot depending on whether the transaction occurs at the bid or ask price. While this technique is ideal, it requires huge amounts of data on historical bars, which usually limits the historical depth of charts and the number of symbols for which tick data is available.
This indicator uses intrabar analysis to achieve a compromise between the simplest and most precise methods of calculating volume delta. In the context where historical tick data is not yet available on TradingView, intrabar analysis is the most precise technique to calculate volume delta on historical bars on our charts. Our Volume Profile indicators use it. Other volume delta indicators in our Community Scripts such as the Realtime 5D Profile use realtime chart updates to achieve more precise volume delta calculations, but that method cannot be used on historical bars, so those indicators only work in real time.
This is the logic we use to assign intrabar volume to up or down slots:
• If the intrabar's open and close values are different, their relative position is used.
• If the intrabar's open and close values are the same, the difference between the intrabar's close and the previous intrabar's close is used.
• As a last resort, when there is no movement during an intrabar and it closes at the same price as the previous intrabar, the last known polarity is used.
Once all intrabars making up a chart bar have been analyzed and the up or down property of each intrabar's volume determined, the up volumes are added and the down volumes subtracted. The resulting value is volume delta for that chart bar.
█ FEATURES
CVD Candles
Cumulative Volume Delta Candles present volume delta information as it evolves during a period of time.
This is how each candle's levels are calculated:
• open : Each candle's' open level is the cumulative volume delta for the current period at the start of the bar.
This value becomes zero on the first candle following a CVD reset.
The candles after the first one always open where the previous candle closed.
The candle's high, low and close levels are then calculated by adding or subtracting a volume value to the open.
• high : The highest volume delta value found in intrabars. If it is not higher than the volume delta for the bar, then that candle will have no upper wick.
• low : The lowest volume delta value found in intrabars. If it is not lower than the volume delta for the bar, then that candle will have no lower wick.
• close : The aggregated volume delta for all intrabars. If volume delta is positive for the chart bar, then the candle's close will be higher than its open, and vice versa.
The candles are plotted in one of two configurable colors, depending on the polarity of volume delta for the bar.
CVD resets
The "cumulative" part of the indicator's name stems from the fact that calculations accumulate during a period of time. This allows you to analyze the progression of volume delta across manageable chunks, which is often more useful than looking at volume delta cumulated from the beginning of a chart's history.
You can configure the reset period using the "CVD Resets" input, which offers the following selections:
• None : Calculations do not reset.
• On a fixed higher timeframe : Calculations reset on the higher timeframe you select in the "Fixed higher timeframe" field.
• At a fixed time that you specify.
• At the beginning of the regular session .
• On a stepped higher timeframe : Calculations reset on a higher timeframe automatically stepped using the chart's timeframe and following these rules:
Chart TF HTF
< 1min 1H
< 3H 1D
<= 12H 1W
< 1W 1M
>= 1W 1Y
The indicator's background shows where resets occur.
Intrabar precision
The precision of calculations increases with the number of intrabars analyzed for each chart bar. It is controlled through the script's "Intrabar precision" input, which offers the following selections:
• Least precise, covering many chart bars
• Less precise, covering some chart bars
• More precise, covering less chart bars
• Most precise, 1min intrabars
As there is a limit to the number of intrabars that can be analyzed by a script, a tradeoff occurs between the number of intrabars analyzed per chart bar and the chart bars for which calculations are possible.
Total volume candles
You can choose to display candles showing the total intrabar volume for the chart bar. This provides you with more context to evaluate a bar's volume delta by showing it relative to the sum of intrabar volume. Note that because of the reasons explained in the "NOTES" section further down, the total volume is the sum of all intrabar volume rather than the volume of the bar at the chart's timeframe.
Total volume candles can be configured with their own up and down colors. You can also control the opacity of their bodies to make them more or less prominent. This publication's chart shows the indicator with total volume candles. They are turned off by default, so you will need to choose to display them in the script's inputs for them to plot.
Divergences
Divergences occur when the polarity of volume delta does not match that of the chart bar. You can identify divergences by coloring the CVD candles differently for them, or by coloring the indicator's background.
Information box
An information box in the lower-left corner of the indicator displays the HTF used for resets, the LTF used for intrabars, and the average quantity of intrabars per chart bar. You can hide the box using the script's inputs.
█ INTERPRETATION
The first thing to look at when analyzing CVD candles is the side of the zero line they are on, as this tells you if CVD is generally bullish or bearish. Next, one should consider the relative position of successive candles, just as you would with a price chart. Are successive candles trending up, down, or stagnating? Keep in mind that whatever trend you identify must be considered in the context of where it appears with regards to the zero line; an uptrend in a negative CVD (below the zero line) may not be as powerful as one taking place in positive CVD values, but it may also predate a movement into positive CVD territory. The same goes with stagnation; a trader in a long position will find stagnation in positive CVD territory less worrisome than stagnation under the zero line.
After consideration of the bigger picture, one can drill down into the details. Exactly what you are looking for in markets will, of course, depend on your trading methodology, but you may find it useful to:
• Evaluate volume delta for the bar in relation to price movement for that bar.
• Evaluate the proportion that volume delta represents of total volume.
• Notice divergences and if the chart's candle shape confirms a hesitation point, as a Doji would.
• Evaluate if the progress of CVD candles correlates with that of chart bars.
• Analyze the wicks. As with price candles, long wicks tend to indicate weakness.
Always keep in mind that unless you have chosen not to reset it, your CVD resets for each period, whether it is fixed or automatically stepped. Consequently, any trend from the preceding period must re-establish itself in the next.
█ NOTES
Know your volume
Traders using volume information should understand the volume data they are using: where it originates and what transactions it includes, as this can vary with instruments, sectors, exchanges, timeframes, and between historical and realtime bars. The information used to build a chart's bars and display volume comes from data providers (exchanges, brokers, etc.) who often maintain distinct feeds for intraday and end-of-day (EOD) timeframes. How volume data is assembled for the two feeds depends on how instruments are traded in that sector and/or the volume reporting policy for each feed. Instruments from crypto and forex markets, for example, will often display similar volume on both feeds. Stocks will often display variations because block trades or other types of trades may not be included in their intraday volume data. Futures will also typically display variations.
Note that as intraday vs EOD variations exist for historical bars on some instruments, differences may also exist between the realtime feeds used on intraday vs 1D or greater timeframes for those same assets. Realtime reporting rules will often be different from historical feed reporting rules, so variations between realtime feeds will often be different from the variations between historical feeds for the same instrument. The Volume X-ray indicator can help you analyze differences between intraday and EOD volumes for the instruments you trade.
If every unit of volume is both bought by a buyer and sold by a seller, how can volume delta make sense?
Traders who do not understand the mechanics of matching engines (the exchange software that matches orders from buyers and sellers) sometimes argue that the concept of volume delta is flawed, as every unit of volume is both bought and sold. While they are rigorously correct in stating that every unit of volume is both bought and sold, they overlook the fact that information can be mined by analyzing variations in the price of successive ticks, or in our case, intrabars.
Our calculations model the situation where, in fully automated order handling, market orders are generally matched to limit orders sitting in the order book. Buy market orders are matched to quotes at the ask level and sell market orders are matched to quotes at the bid level. As explained earlier, we use the same logic when comparing intrabar prices. While using intrabar analysis does not produce results as precise as when individual transactions — or ticks — are analyzed, results are much more precise than those of methods using only chart prices.
Not only does the concept underlying volume delta make sense, it provides a window on an oft-overlooked variable which, with price and time, is the only basic information representing market activity. Furthermore, because the calculation of volume delta also uses price and time variations, one could conceivably surmise that it can provide a more complete model than ones using price and time only. Whether or not volume delta can be useful in your trading practice, as usual, is for you to decide, as each trader's methodology is different.
For Pine Script™ coders
As our latest Polarity Divergences publication, this script uses the recently released request.security_lower_tf() Pine Script™ function discussed in this blog post . It works differently from the usual request.security() in that it can only be used at LTFs, and it returns an array containing one value per intrabar. This makes it much easier for programmers to access intrabar information.
Look first. Then leap.

Naked Intrabar POCThis indicator with an unfortunate and very non PC sounding name approximates (!) the intrabar point of control (POC) either from time or volume at price.
Due to pine limitations, bin size and the sample lower time frame selection will have at least some effect on the accuracy of the approximation. The trade off is between accuracy and historical availability, however bar replay can be used to view prior historical states beyond what is visible from the current real time bar.
In order for all intrabar POC circles to be visible, you will need to manually set the visual order of the indicator by bringing it to the front.
Since the POC represents a price point around which the highest market participation occurred, the exposed global variable intrabar_poc may (or may not) be interesting as an alternative to ohlc based source input.

Everything Bitcoin [Kioseff Trading]Hello!
This script retrieves most of the available Bitcoin data published by Quandl; the script utilizes the new request.security_lower_tf() function.
Included statistics,
True price
Volume
Difficulty
My Wallet # Of Users
Average Block Size
api.blockchain size
Median Transaction Confirmation Time
Miners' Revenue
Hash Rate
Cost Per Transaction
Cost % of Transaction Volume
Estimated Transaction Volume USD
Total Output Volume
Number Of Transactions Per Block
# of Unique BTC Addresses
# of BTC Transactions Excluding Popular Addresses
Total Number of Transactions
Daily # of Transactions
Total Transaction Fees USD
Market Cap
Total BTC
Retrieved data can be plotted as line graphs; however, the data is initially split between two tables.
The image above shows how the requested Bitcoin data is displayed.
However, in the user inputs tab, you can modify how the data is displayed.
For instance, you can append the data displayed in the floating statistics box to the stagnant statistics box.
The image above exemplifies the instance.
You can hide any and all data via the user inputs tab.
In addition to data publishing, the script retrieves lower timeframe price/volume/indicator data, to which the values of the requested data are appended to center-right table.
The image above shows the script retrieving one-minute bar data.
Up arrows reflect an increase in the more recent value, relative to the immediately preceding value.
Down arrows reflect a decrease in the more recent value relative to the immediately preceding value.
The ascending minute column reflects the number of minutes/hours (ago) the displayed value occurred.
For instance, 15 minutes means the displayed value occurred 15 minutes prior to the current time (value).
Volume, price, and indicator data can be retrieved on lower timeframe charts ranging from 1 minute to 1440 minutes.
The image above shows retrieved 5-minute volume data.
Several built-in indicators are included, to which lower timeframe values can be retrieved.
The image above shows LTF VWAP data. Also distinguished are increases/decreases for sequential values.
The image above shows a dynamic regression channel. The channel terminates and resets each fiscal quarter. Previous channels remain on the chart.
Lastly, you can plot any of the requested data.
The new request.security_lower_tf() function is immensely advantageous - be sure to try it in your scripts!

Liquidity Heatmap LTF [LuxAlgo]This indicator displays column heatmaps highlighting candle bodies with the highest associated volume from a lower user selected timeframe.
Settings
LTF Timeframe: Lower timeframe used to retrieve the closing/opening price and volume data. Must be lower than the current chart timeframe.
Other settings control the style of the displayed graphical elements.
Usage
It can be of interest to show which candles from a lower timeframe had the highest associated volume, this allows for the highlighting of areas where a candle body was the most traded by market participants.
The area with the highest activity is highlighted in the script with a yellow color (or another user selected color) and additionally by two lines forming an interval.
When the candle body with the highest volume is overlapped by a candle body with lower volume this one will be highlighted instead, hence why certain areas of high activity might not be highlighted by the heatmap.
It is recommended to hide regular candles or use a more discrete graphical presentation of prices when using this tool. Lines are also displayed to highlight the full candle range as well as if a candle was bullish (in green) or bearish (in red). These lines can be hidden if the user is only interested in the heatmap.

TASC 2022.6 Ehlers' Loops - SectorsInspired by the latest TASC article, the crocker graph is expanded to show 5 tickers.
for commodity also draws a side box with current tickers candles so it can be used as standalone.

Wolfe Scanner (Multi - zigzag) [HeWhoMustNotBeNamed]Before getting into the script, I would like to explain bit of history around this project. Wolfe was in the back of my mind for some time and I had several attempts so far.
🎯Initial Attempt
When I first developed harmonic patterns, I got many requests from users to develop script to automatically detect Wolfe formation. I thought it would be easy and started boasting everywhere that I am going to attempt this next. However I miserably failed that time and started realising it is not as simple as I thought it would be. I started with Wolfe in mind. But, ran into issues with loops. Soon figured out that finding and drawing wedge is more trickier. I decided will explore trendline first so that it can help find wedge better. Soon, the project turned into something else and resulted in Auto-TrendLines-HeWhoMustNotBeNamed and Wolfe left forgotten.
🎯Using predefined ratios
Wolfe also has predefined fib ratios which we can use to calculate the formation. But, upon initial development, it did not convince me that it matches visual inspection of Wolfe all the time. Hence, I decided to fall back on finding wedge first.
🎯 Further exploration in finding wedge
This attempt was not too bad. I did not try to jump into Wolfe and nor I bragged anywhere about attempting anything of this sort. My target this time was to find how to derive wedge. I knew then that if I manage to calculate wedge in efficient way, it can help further in finding Wolfe. While doing that, ended up deriving Wedge-and-Flag-Finder-Multi-zigzag - which is not a bad outcome. I got few reminders on Wolfe after this both in comments and in PM.
🎯You never fail until you stop trying!!
After 2 back to back hectic 50hr work weeks + other commitments, I thought I will spend some time on this. Took less than half weekend and here we are. I was surprised how much little time it took in this attempt. But, the plan was running in my subconscious for several weeks or even months. Last two days were just putting these plans into an action.
Now, let's discuss about the script.
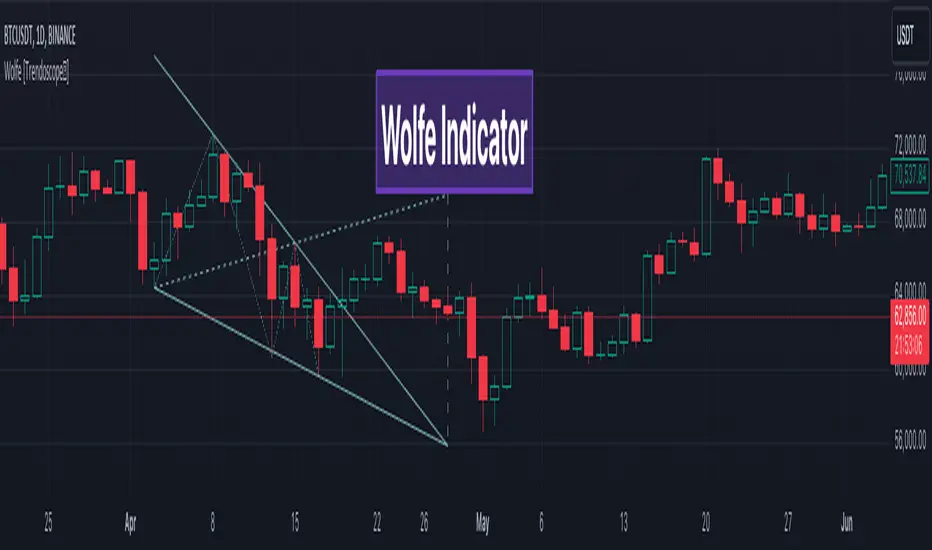
🎲 Wolfe Concept
Wolfe concept is simple. Whenever a wedge is formed, draw a line joining pivot 1 and 4 as shown in the chart below:
Converging trendline forms the stop loss whereas line joining pivots 1 and 4 form the profit taking points.
🎲 Settings
Settings are pretty straightforward. Explained in the chart below.
TASC 2022.06 Ehlers Loops█ OVERVIEW
TASC's June 2022 edition Traders' Tips includes an article by John Ehlers titled "Ehlers Loops. Part 1". This is the code implementing the price-volume Ehlers Loops he introduced in the publication.
█ CONCEPTS
John Ehlers developed Ehlers loops as a tool to visualize the performance of one data stream versus another, both filtered and scaled. In this article, the author applies his concept to exploit and/or dispel the dogmatic principles of reliable price-volume relationships.
The script offers two different ways to visualize Ehlers Loops:
Oscillators (default option)
In this implementation, filtered and scaled volume is plotted along with filtered and scaled price as zero-mean oscillators. Observation of the relative direction of volume and price oscillators can be discretionarily used to interpret and predict market conditions. For example, it is generally assumed that an increase in volume and an increase in price define a bullish condition. Similarly, decreasing volume and increasing price are generally considered bearish. A decrease in volume and a decrease in price is considered a bullish condition. The increase in volume and decrease in price is often thought to be bearish.
Scatterplot
This Crocker-style visualization displays filtered and scaled price against filtered and scaled volume for the selected timespan. Fluctuations in volume are plotted along the x -axis, while price changes along the y -axis. This way of visualizing the Ehlers Loop allows you to analyze the curvature and directional path of the price in relation to volume, offering a different comparative perspective. The boundaries of the price and volume scale on the Ehlers Loop Crocker-chart are presented in standard deviations. Deviations can be used to predict possible future price or volume fluctuations. The expected probability of potential reversals is 68%, 95% and 99.7% at one, two and three standard deviations, respectively.
█ CALCULATIONS
The following steps are used to build an Ehlers Loop:
• Both price and volume are filtered to be band-limited signals. This is done by applying the high-pass Butterworth filter in combination with the low-pass SuperSmooth filter.
The cutoff wavelengths of the high-pass and low-pass filters are defined by the input parameters HPPeriod and LPPeriod , respectively.
These values change the appearance of the Ehlers Loops and can be customized to your trading style.
• The filtered price and volume time series are then scaled in terms of standard deviation by dividing each by their root-mean-square values.
• The resultant price and volume data are plotted as zero-mean oscillators or as a scatterplot.

Lowest / Highest From WidgetRecent events inspired me to create a small widget that allows you to spot from when current value is lowest / highest.
Just add it to chart and script will compute most recent day when price was higher / lower than current and it will display:
Line coming from that value to the current one
A table with previous low/high information
Thanks to @MUQWISHI to help me coding it.
Disclaimer
Please remember that past performance may not be indicative of future results.
Due to various factors, including changing market conditions, the strategy may no longer perform as well as in historical backtesting.
This post and the script don’t provide any financial advice.

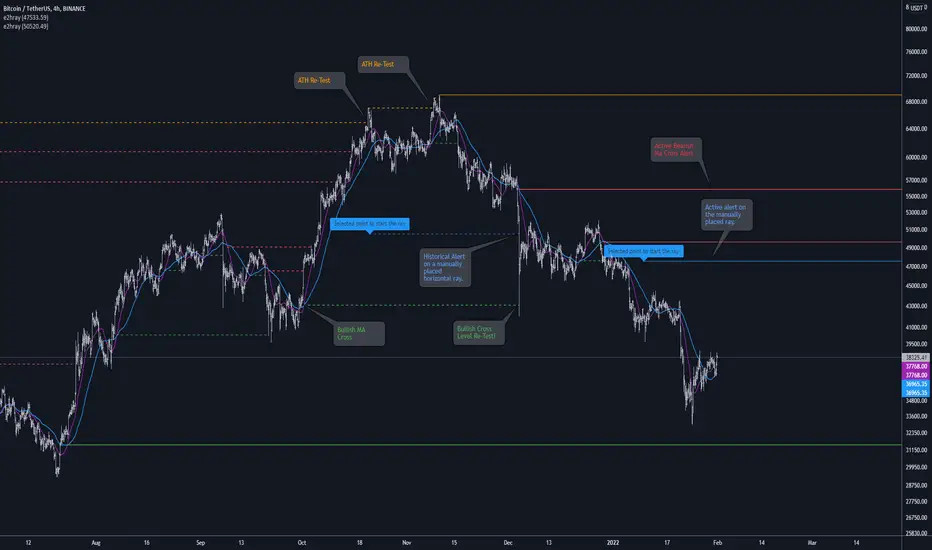
[e2] Drawing Library :: Horizontal Ray█ OVERVIEW
Library "e2hray"
A drawing library that contains the hray() function, which draws a horizontal ray/s with an initial point determined by a specified condition. It plots a ray until it reached the price. The function let you control the visibility of historical levels and setup the alerts.
█ HORIZONTAL RAY FUNCTION
hray(condition, level, color, extend, hist_lines, alert_message, alert_delay, style, hist_style, width, hist_width)
Parameters:
condition : Boolean condition that defines the initial point of a ray
level : Ray price level.
color : Ray color.
extend : (optional) Default value true, current ray levels extend to the right, if false - up to the current bar.
hist_lines : (optional) Default value true, shows historical ray levels that were revisited, default is dashed lines. To avoid alert problems set to 'false' before creating alerts.
alert_message : (optional) Default value string(na), if declared, enables alerts that fire when price revisits a line, using the text specified
alert_delay : (optional) Default value int(0), number of bars to validate the level. Alerts won't trigger if the ray is broken during the 'delay'.
style : (optional) Default value 'line.style_solid'. Ray line style.
hist_style : (optional) Default value 'line.style_dashed'. Historical ray line style.
width : (optional) Default value int(1), ray width in pixels.
hist_width : (optional) Default value int(1), historical ray width in pixels.
Returns: void
█ EXAMPLES
• Example 1. Single horizontal ray from the dynamic input.
//@version=5
indicator("hray() example :: Dynamic input ray", overlay = true)
import e2e4mfck/e2hray/1 as e2draw
inputTime = input.time(timestamp("20 Jul 2021 00:00 +0300"), "Date", confirm = true)
inputPrice = input.price(54, 'Price Level', confirm = true)
e2draw.hray(time == inputTime, inputPrice, color.blue, alert_message = 'Ray level re-test!')
var label mark = label.new(inputTime, inputPrice, 'Selected point to start the ray', xloc.bar_time)
• Example 2. Multiple horizontal rays on the moving averages cross.
//@version=5
indicator("hray() example :: MA Cross", overlay = true)
import e2e4mfck/e2hray/1 as e2draw
float sma1 = ta.sma(close, 20)
float sma2 = ta.sma(close, 50)
bullishCross = ta.crossover( sma1, sma2)
bearishCross = ta.crossunder(sma1, sma2)
plot(sma1, 'sma1', color.purple)
plot(sma2, 'sma2', color.blue)
// 1a. We can use 2 function calls to distinguish long and short sides.
e2draw.hray(bullishCross, sma1, color.green, alert_message = 'Bullish Cross Level Broken!', alert_delay = 10)
e2draw.hray(bearishCross, sma2, color.red, alert_message = 'Bearish Cross Level Broken!', alert_delay = 10)
// 1b. Or a single call for both.
// e2draw.hray(bullishCross or bearishCross, sma1, bullishCross ? color.green : color.red)
• Example 3. Horizontal ray at the all time highs with an alert.
//@version=5
indicator("hray() example :: ATH", overlay = true)
import e2e4mfck/e2hray/1 as e2draw
var float ath = 0, ath := math.max(high, ath)
bool newAth = ta.change(ath)
e2draw.hray(nz(newAth ), high , color.orange, alert_message = 'All Time Highs Tested!', alert_delay = 10)
Numbers RenkoRenko with Volume and Time in the box was developed by David Weis (Authority on Wyckoff method) and his student.
I like this style (I don't know what it is officially called) because it brings out the potential of Wyckoff method and Renko, and looks beautiful.
I can't find this style Indicator anywhere, so I made something like it, then I named "Numbers Renko" (数字 練行足 in Japanese).
Caution : This indicator only works exactly in Renko Chart.
////////// Numbers Renko General Settings //////////
Volume Divisor : To make good looking Volume Number.
ex) You set 100. When Volume is 0.056, 0.05 x 100 = 5.6. 6 is plotted in the box (Decimal are round off).
Show Only Large Renko Volume : show only Renko Volume which is larger than Average Renko Volume (it is calculated by user selected moving average, option below).
Show Renko Time : "Only Large Renko Time" show only Renko Time which is larger than Average Renko Time (it is calculated by user selected moving average, option below).
EMA period for calculation : This is used to calculate Average Renko Time and Average Renko Volume (These are used to decide Numbers colors and Candles colors). Default is EMA, You can choice SMA.
////////// Numbers Renko Coloring //////////
The Numbers in the box are color coded by compared the current Renko Volume with the Average Renko Volume.
If the current Renko Volume is 2 times larger than the ARV, Color2 will be used. If the current Renko Volume is 1.5 times larger than the ARV, Color1.5 will be used. Color1 If the current Renko Volume is larger than the ARV . Color0.5 is larger than half Athe RV and Color0 is less than or equal to half the ARV. Color1, Color1.5 and Color2 are Large Value, so only these colored Numbers are showed when use "Show Only ~ " option.
Default is Renko Volume based Color coding, You can choice Renko Time based Color coding. Therefore you can use two type coloring at the same time. ex) The Numbers Colors are Renko Volume based. Candle body, border and wick Colors are Renko Time based.
////////// Weis Wave Volume //////////
Show Effort vs Result : Weis Wave Volume divided by Wave Length.
ex) If 100 Up WWV is accumulated between 30 Up Renko Box, 100 / 30 = 3.33... will be 3.3 (Second decimal will be rounded off).
No Result Ratio : If current "Effort vs Result" is "No Result Ratio" times larger than Average Effort vs Result, Square Mark will be show. AEvsR is calculated by 5SMA.
ex) You set 1.5. If Current EvsR is 20 and AEvsR is 10, 20 > 10 x 1.5 then Square Mark will be show.
If the left and right arrows are in the same direction, the right arrow is omitted.
Show Comparison Marks : Show left side arrow by compare current value to previous previous value and show right side small arrow by compare current value to previous value.
ex) Current Up WWV is 17 and Previous Up WWV (previous previous value) is 12, left side arrow is Up. Previous Dn WWV is 20, right side small arrow is Dn.
Large Volume Ratio : If current WWV is "Large Volume Ratio" times larger than Average WWV, Large WWV color is used.
Sample layout

3D Sine WaveIt's a 3D sine wave! Cool!
I made a cube follow a sine wave, it doesn't reflect any data on the chart, it just looks pretty. There are some settings to play around with, too.
You could plug the cube into any input you like, just replace the 'wave' variable with whatever you want.
Watch it on the 1 second timeframe!

HTF Liquidity Levels█ OVERVIEW
The indicator introduces a new representation of the previous days, weeks, and months highs & lows ( DWM HL ) with a focus on untapped levels.
█ CONCEPTS
Untapped Levels
It is popularly known that the liquidity is located behind swing points or beyond higher time frames highs/lows (in a sense, an intraday swing point is a day high/low). These key areas are said "liquid" because of the accumulation of resting orders, mainly in the form of stop-loss orders. And this more significantly on higher time frames which have more time for stacking orders. As the result, the indicator aims to keep track of untapped levels that have their liquidity states intact.
Liquidity Pools
Once a liquidity level identified, or better, a cluster of liquidity levels work as magnets for the market. The price is more likely to make its way towards heavier pockets of liquidity, by proximity (the closest liquidity pool), and by difficulty (path with less obstacles). This phenomenon is referred as liquidity run, raid, purge, grab, hunt, sweep, you name it. Consequently, the indicator can help you frame a directional bias during your trading session.
█ NOTES
Drawings
Once a level is tapped, it is highlighted. At the end of each day, all tapped levels are cleared.

Portfolio Laboratory [Kioseff Trading]Hello!
This script looks to experiment with historical portfolio performance. However, a hypothetical cash balance is not used; weighted percentage increases and decreases are used.
You can select up to 10 assets to include in the portfolio. Long and short positions are possible.
Show in the image are the portfolio's weight, the total return of the portfolio and the total return of the asset on the chart over the selected timeframe.
Shown in the image above are the constituents of the portfolio, which can include any asset, the weighted percentage gain/loss of the constituents in addition to 10 major indices and their respective total percentage gain/loss over the timeframe.
Shown in the image above are the dividend yield % of the portfolio and relevant portfolio metrics - ex-post calculations are applied and are predicated on simple returns.
Shown in the image above is a portfolio of all short positions; portfolio calculations adjusted to the modifications.
Also shown is a change in the index the portfolio is calculated against. I have been asked a few times to include NIFTY 50 in my scripts - I made sure this was achieved, lol!
Show in the image is a performance line of performance of percentage increases/decreases for the index calculated against, the asset on the chart, and the portfolio.
All lines start simultaneously on the selected start date at the close price of the session for the asset on your chart.
However, the right-hand scale, whether displaying price or percent, cannot be used to assess the performance of each line - they are useful for visualization only and can extend below zero on a low-priced asset. Calculations will not execute correctly when selecting a start date prior to any asset in the portfolio's first trading session; calculations do not begin on the first bar of the asset on your chart.
I decided to code the script this way so statistics remain fixed when moving from asset to asset!
To compensate for this limitation, I included a label plot and background color change at the first session in which all assets in the portfolio had at least one bar of price data. You can adjust the calculation start date to the date portrayed on the label to test al possible price data!
The statistics table, and the performance lines, can be hidden in the user input section.
I plan on putting a bit more work into this script. I have some ideas on what to include; however, any input is greatly appreciated! If there's something you would like me to include please let me know.
@scheplick mentioned me in a script he recently coded:
My inspiration came from his script! I thank him for that!
