LibraryCOT_NZLibrary "LibraryCOT_NZ"
This library provides tools to help Pine programmers fetch Commitment of Traders (COT) data for futures.
rootToCFTCCode(root)
Accepts a futures root and returns the relevant CFTC code.
Parameters:
root (simple string) : Root prefix of the future's symbol, e.g. "ZC" for "ZC1!"" or "ZCU2021".
Returns: The part of a COT ticker corresponding to `root`, or "" if no CFTC code exists for the `root`.
currencyToCFTCCode(currency)
Converts a currency string to its corresponding CFTC code.
Parameters:
currency (simple string)
Returns: The corresponding to the currency, if one exists.
optionsToTicker(includeOptions)
Returns the part of a COT ticker using the `includeOptions` value supplied, which determines whether options data is to be included.
Parameters:
includeOptions (simple bool) : A "bool" value: 'true' if the symbol should include options and 'false' otherwise.
Returns: The part of a COT ticker: "FO" for data that includes options and "F" for data that doesn't.
metricNameAndDirectionToTicker(metricName, metricDirection)
Returns a string corresponding to a metric name and direction, which is one component required to build a valid COT ticker ID.
Parameters:
metricName (simple string) : One of the metric names listed in this library's chart. Invalid values will cause a runtime error.
metricDirection (simple string) : Metric direction. Possible values are: "Long", "Short", "Spreading", and "No direction". Valid values vary with metrics. Invalid values will cause a runtime error.
Returns: The part of a COT ticker ID string, e.g., "OI_OLD" for "Open Interest" and "No direction", or "TC_L" for "Traders Commercial" and "Long".
typeToTicker(metricType)
Converts a metric type into one component required to build a valid COT ticker ID. See the "Old and Other Futures" section of the CFTC's Explanatory Notes for details on types.
Parameters:
metricType (simple string) : Metric type. Accepted values are: "All", "Old", "Other".
Returns: The part of a COT ticker.
convertRootToCOTCode(mode, convertToCOT)
Depending on the `mode`, returns a CFTC code using the chart's symbol or its currency information when `convertToCOT = true`. Otherwise, returns the symbol's root or currency information. If no COT data exists, a runtime error is generated.
Parameters:
mode (simple string) : A string determining how the function will work. Valid values are:
"Root": the function extracts the futures symbol root (e.g. "ES" in "ESH2020") and looks for its CFTC code.
"Base currency": the function extracts the first currency in a pair (e.g. "EUR" in "EURUSD") and looks for its CFTC code.
"Currency": the function extracts the quote currency ("JPY" for "TSE:9984" or "USDJPY") and looks for its CFTC code.
"Auto": the function tries the first three modes (Root -> Base Currency -> Currency) until a match is found.
convertToCOT (simple bool) : "bool" value that, when `true`, causes the function to return a CFTC code. Otherwise, the root or currency information is returned. Optional. The default is `true`.
Returns: If `convertToCOT` is `true`, the part of a COT ticker ID string. If `convertToCOT` is `false`, the root or currency extracted from the current symbol.
COTTickerid(COTType, CFTCCode, includeOptions, metricName, metricDirection, metricType)
Returns a valid TradingView ticker for the COT symbol with specified parameters.
Parameters:
COTType (simple string) : A string with the type of the report requested with the ticker, one of the following: "Legacy", "Disaggregated", "Financial".
CFTCCode (simple string)
includeOptions (simple bool) : A boolean value. 'true' if the symbol should include options and 'false' otherwise.
metricName (simple string) : One of the metric names listed in this library's chart.
metricDirection (simple string) : Direction of the metric, one of the following: "Long", "Short", "Spreading", "No direction".
metricType (simple string) : Type of the metric. Possible values: "All", "Old", and "Other".
Returns: A ticker ID string usable with `request.security()` to fetch the specified Commitment of Traders data.
In den Scripts nach "one一季度财报" suchen
footprint_typeLibrary "footprint_type"
Contains all types for calculating and rendering footprints
Inputs
Inputs objects
Fields:
inbalance_percent (series int) : percentage coefficient to determine the Imbalance of price levels
stacked_input (series int) : minimum number of consecutive Imbalance levels required to draw extended lines
show_summary_footprint (series bool) : bool input for show summary footprint
procent_volume_area (series int) : definition size Value area
show_vah (series bool) : bool input for show VAH
show_poc (series bool) : bool input for show POC
show_val (series bool) : bool input for show VAL
color_vah (series color) : color VAH line
color_poc (series color) : color POC line
color_val (series color) : color VAL line
show_volume_profile (series bool)
new_imbalance_cond (series bool) : bool input for setup alert on new imbalance buy and sell
new_imbalance_line_cond (series bool) : bool input for setup alert on new imbalance line buy and sell
stop_past_imbalance_line_cond (series bool) : bool input for setup alert on stop past imbalance line buy and sell
Constants
Constants all Constants objects
Fields:
imbalance_high_char (series string) : char for printing buy imbalance
imbalance_low_char (series string) : char for printing sell imbalance
color_title_sell (series color) : color for footprint sell
color_title_buy (series color) : color for footprint buy
color_line_sell (series color) : color for sell line
color_line_buy (series color) : color for buy line
color_title_none (series color) : color None
Calculation_data
Calculation_data data for calculating
Fields:
detail_open (array) : array open from calculation timeframe
detail_high (array) : array high from calculation timeframe
detail_low (array) : array low from calculation timeframe
detail_close (array) : array close from calculation timeframe
detail_vol (array) : array volume from calculation timeframe
previos_detail_close (array) : array close from calculation timeframe
isBuyVolume (series bool) : attribute previosly bar buy or sell
Footprint_row
Footprint_row objects one footprint row
Fields:
price (series float) : row price
buy_vol (series float) : buy volume
sell_vol (series float) : sell volume
imbalance_buy (series bool) : attribute buy inbalance
imbalance_sell (series bool) : attribute sell imbalance
buy_vol_box (series box) : for ptinting buy volume
sell_vol_box (series box) : for printing sell volume
buy_vp_box (series box) : for ptinting volume profile buy
sell_vp_box (series box) : for ptinting volume profile sell
row_line (series label) : for ptinting row price
empty (series bool) : = true attribute row with zero volume buy and zero volume sell
Value_area
Value_area objects for calculating and printing Value area
Fields:
vah_price (series float) : VAH price
poc_price (series float) : POC price
val_price (series float) : VAL price
vah_label (series label) : label for VAH
poc_label (series label) : label for POC
val_label (series label) : label for VAL
vah_line (series line) : line for VAH
poc_level (series line) : line for POC
val_line (series line) : line for VAL
Imbalance_line_var_object
Imbalance_line_var_object var objects printing and calculation imbalance line
Fields:
cum_buy_line (array) : line array for saving all history buy imbalance line
cum_sell_line (array) : line array for saving all history sell imbalance line
Imbalance_line
Imbalance_line objects printing and calculation imbalance line
Fields:
buy_price_line (array) : float array for saving buy imbalance price level
sell_price_line (array) : float array for saving sell imbalance price level
var_imba_line (Imbalance_line_var_object) : var objects this type
Footprint_info_var_object
Footprint_info_var_object var objects for info printing
Fields:
cum_delta (series float) : var delta volume
cum_total (series float) : var total volume
cum_buy_vol (series float) : var buy volume
cum_sell_vol (series float) : var sell volume
cum_info (series table) : table for ptinting
Footprint_info
Footprint_info objects for info printing
Fields:
var_info (Footprint_info_var_object) : var objects this type
total (series label) : total volume
delta (series label) : delta volume
summary_label (series label) : label for ptinting
Footprint_bar
Footprint_bar all objects one bar with footprint
Fields:
foot_rows (array) : objects one row footprint
val_area (Value_area) : objects Value area
imba_line (Imbalance_line) : objects imbalance line
info (Footprint_info) : objects info - table,label and their variable
row_size (series float) : size rows
total_vol (series float) : total volume one footprint bar
foot_buy_vol (series float) : buy volume one footprint bar
foot_sell_vol (series float) : sell volume one footprint bar
foot_max_price_vol (map) : map with one value - price row with max volume buy + sell
calc_data (Calculation_data) : objects with detail data from calculation resolution
Support_objects
Support_objects support object for footprint calculation
Fields:
consts (Constants) : all consts objects
inp (Inputs) : all input objects
bar_index_show_condition (series bool) : calculation bool value for show all objects footprint
row_line_color (series color) : calculation value - color for row price

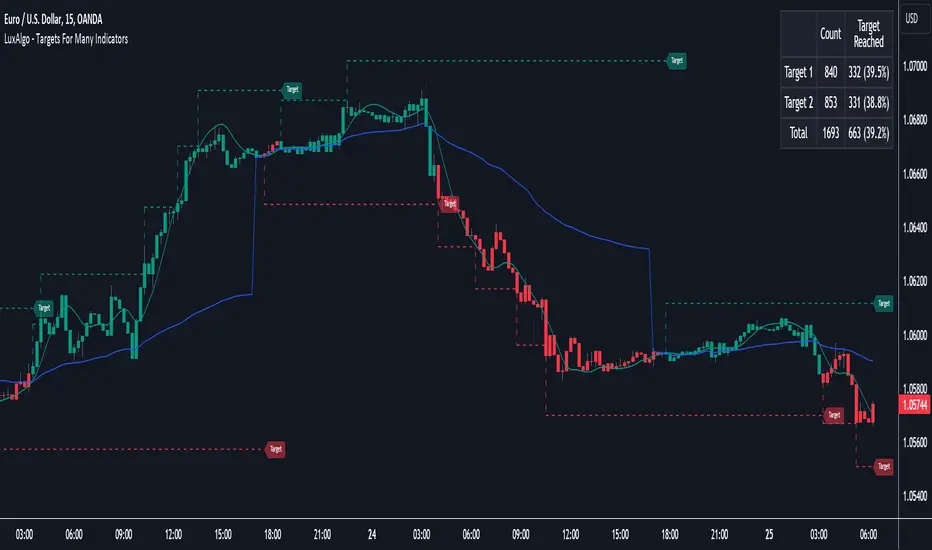
Targets For Many Indicators [LuxAlgo]The Targets For Many Indicators is a useful utility tool able to display targets for many built-in indicators as well as external indicators. Targets can be set for specific user-set conditions between two series of values, with the script being able to display targets for two different user-set conditions.
Alerts are included for the occurrence of a new target as well as for reached targets.
🔶 USAGE
Targets can help users determine the price limit where the price might start deviating from an indication given by one or multiple indicators. In the context of trading, targets can help secure profits/reduce losses of a trade, as such this tool can be useful to evaluate/determine user take profits/stop losses.
Due to these essentially being horizontal levels, they can also serve as potential support/resistances, with breakouts potentially confirming new trends.
In the above example, we set targets 3 ATR's away from the closing price when the price crosses over the script built-in SuperTrend indicator using ATR period 10 and factor 3. Using "Long Position Target" allows setting a target above the price, disabling this setting will place targets below the price.
Users might be interested in obtaining new targets once one is reached, this can be done by enabling "New Target When Reached" in the target logic setting section, resulting in more frequent targets.
Lastly, users can restrict new target creation until current ones are reached. This can result in fewer and longer-term targets, with a higher reach rate.
🔹 Dashboard
A dashboard is displayed on the top right of the chart, displaying the amount, reach rate of targets 1/2, and total amount.
This dashboard can be useful to evaluate the selected target distances relative to the selected conditions, with a higher reach rate suggesting the distance of the targets from the price allows them to be reached.
🔶 DETAILS
🔹 Indicators
Besides 'External' sources, each source can be set at 1 of the following Build-In Indicators :
ACCDIST : Accumulation/distribution index
ATR : Average True Range
BB (Middle, Upper or Lower): Bollinger Bands
CCI : Commodity Channel Index
CMO : Chande Momentum Oscillator
COG : Center Of Gravity
DC (High, Mid or Low): Donchian Channels
DEMA : Double Exponential Moving Average
EMA : Exponentially weighted Moving Average
HMA : Hull Moving Average
III : Intraday Intensity Index
KC (Middle, Upper or Lower): Keltner Channels
LINREG : Linear regression curve
MACD (macd, signal or histogram): Moving Average Convergence/Divergence
MEDIAN : median of the series
MFI : Money Flow Index
MODE : the mode of the series
MOM : Momentum
NVI : Negative Volume Index
OBV : On Balance Volume
PVI : Positive Volume Index
PVT : Price-Volume Trend
RMA : Relative Moving Average
ROC : Rate Of Change
RSI : Relative Strength Index
SMA : Simple Moving Average
STOCH : Stochastic
Supertrend
TEMA : Triple EMA or Triple Exponential Moving Average
VWAP : Volume Weighted Average Price
VWMA : Volume-Weighted Moving Average
WAD : Williams Accumulation/Distribution
WMA : Weighted Moving Average
WVAD : Williams Variable Accumulation/Distribution
%R : Williams %R
Each indicator is provided with a link to the Reference Manual or to the Build-In Indicators page.
The latter contains more information about each indicator.
Note that when "Show Source Values" is enabled, only values that can be logically found around the price will be shown. For example, Supertrend , SMA , EMA , BB , ... will be made visible. Values like RSI , OBV , %R , ... will not be visible since they will deviate too much from the price.
🔹 Interaction with settings
This publication contains input fields, where you can enter the necessary inputs per indicator.
Some indicators need only 1 value, others 2 or 3.
When several input values are needed, you need to separate them with a comma.
You can use 0 to 4 spaces between without a problem. Even an extra comma doesn't give issues.
The red colored help text will guide you further along (Only when Target is enabled)
Some examples that work without issues:
Some examples that work with issues:
As mentioned, the errors won't be visible when the concerning target is disabled
🔶 SETTINGS
Show Target Labels: Display target labels on the chart.
Candle Coloring: Apply candle coloring based on the most recent active target.
Target 1 and Target 2 use the same settings below:
Enable Target: Display the targets on the chart.
Long Position Target: Display targets above the price a user selected condition is true. If disabled will display the targets below the price.
New Target Condition: Conditional operator used to compare "Source A" and "Source B", options include CrossOver, CrossUnder, Cross, and Equal.
🔹 Sources
Source A: Source A input series, can be an indicator or external source.
External: External source if 'External" is selected in "Source A".
Settings: Settings of the selected indicator in "Source A", entered settings of indicators requiring multiple ones must be comma separated, for example, "10, 3".
Source B: Source B input series, can be an indicator or external source.
External: External source if 'External" is selected in "Source B".
Settings: Settings of the selected indicator in "Source B", entered settings of indicators requiring multiple ones must be comma separated, for example, "10, 3".
Source B Value: User-defined numerical value if "value" is selected in "Source B".
Show Source Values: Display "Source A" and "Source B" on the chart.
🔹 Logic
Wait Until Reached: When enabled will not create a new target until an existing one is reached.
New Target When Reached: Will create a new target when an existing one is reached.
Evaluate Wicks: Will use high/low prices to determine if a target is reached. Unselecting this setting will use the closing price.
Target Distance From Price: Controls the distance of a target from the price. Can be determined in currencies/points, percentages, ATR multiples, ticks, or using multiple of external values.
External Distance Value: External distance value when "External Value" is selected in "Target Distance From Price".
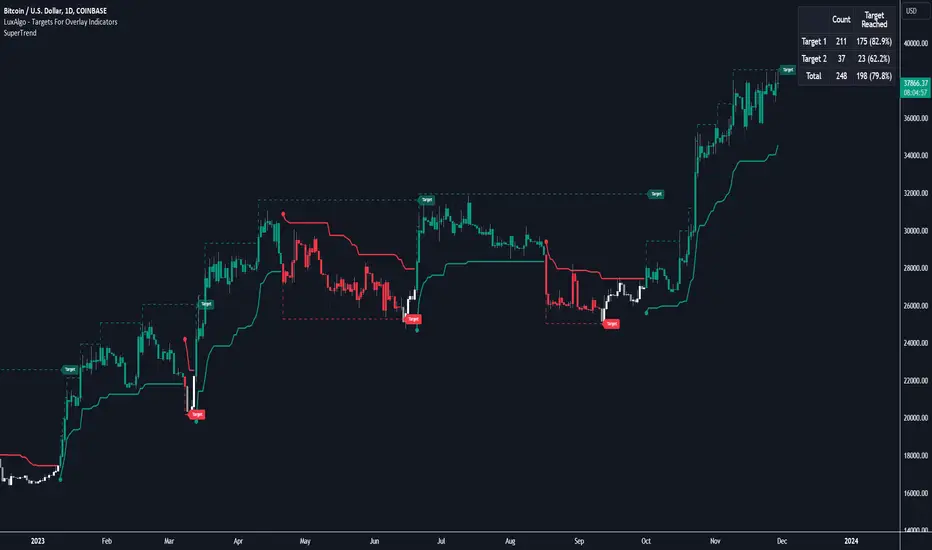
Targets For Overlay Indicators [LuxAlgo]The Targets For Overlay Indicators is a useful utility tool able to display targets during crossings made between the price and external indicators on the user chart. Users can display a series of two targets, one for crossover events and another one for crossunder event.
Alerts are included for the occurrence of a new target as well as for reached targets.
🔶 USAGE
In order for targets to be displayed users need to select an appropriate input source from the "Source" drop-down input setting. In the example above we apply the indicator to a volatility stop.
This can also easily be done by adding the "Targets For Overlay Indicators" script on the VStop indicator directly.
Targets can help users determine the price limit where the price might start deviating from an indication given by one or multiple indicators. In the context of trading, targets can help secure profits/reduce losses of a trade, as such this tool can be useful to evaluate/determine user take profits/stop losses.
Due to these essentially being horizontal levels, they can also serve as potential support/resistances, with breakouts potentially confirming new trends.
Users might be interested in obtaining new targets once one is reached, this can be done by enabling "New Target When Reached" in the target logic setting section, resulting in more frequent targets.
Lastly, users can restrict new target creation until current ones are reached. This can result in fewer and longer-term targets, with a higher reach rate.
🔹 Examples
The indicator can be applied to many overlay indicators that naturally produce crosses with the price, such as moving average, trailing stops, bands...etc.
Users can use trailing stops such as the SuperTrend or VStop to more easily create clean targets. Do note that certain SuperTrend scripts separate the upper and lower extremities of the SuperTrend into two different plot, which cannot be used with this tool, you may use the provided SuperTrend script below to have a compatible version with our tool:
//@version=5
indicator("SuperTrend", overlay = true)
factor = input.float(3, 'Factor', minval = 0)
atrLen = input.int(10, 'ATR Length', minval = 1)
= ta.supertrend(factor, atrLen)
plot(spt, 'SuperTrend', dir != dir ? na : dir < 0 ? #089981 : #f23645, 2)
plot(spt, 'Circles', dir > dir ? #f23645 : dir < dir ? #089981 : na, 3, plot.style_circles)
Using moving averages can produce more targets than other overlay indicators.
Users can apply the tool twice when using bands or any overlay indicator returning two outputs, using crossover targets for obtaining targets using the upper band as source and crossunder targets for targets using the lower band. We can also use the Trendlines with breaks indicator as example:
🔹 Dashboard
A dashboard is displayed on the top right of the chart, displaying the amount, reach rate of targets 1/2, and total amount.
This dashboard can be useful to evaluate the selected target distances relative to the selected conditions, with a higher reach rate suggesting the distance of the targets from the price allows them to be reached.
🔶 SETTINGS
Source: Indicator source used to create targets. Targets are created when the closing price crosses the specified source.
Show Target Labels: Display target labels on the chart.
Candle Coloring: Apply candle coloring based on the most recent active target.
🔹 Target
Crossover and Crossunder targets use the same settings below:
Show Target: Determines if the target is displayed or not.
Above Price Target: If selected, will create targets above the closing price.
Wait Until Reached: When enabled will not create a new target until an existing one is reached.
New Target When Reached: Will create a new target when an existing one is reached.
Evaluate Wicks: Will use high/low prices to determine if a target is reached. Unselecting this setting will use the closing price.
Target Distance From Price: Controls the distance of a target from the price. Can be determined in currencies/points, percentages, ATR multiples, or ticks.
Dual_MACD_trendingINFO:
This indicator is useful for trending assets, as my preference is for low-frequency trading, thus using BTCUSD on 1D/1W chart
In the current implementation I find two possible use cases for the indicator:
- as a stand-alone indicator on the chart which can also fire alerts that can help to determine if we want to manually enter/exit trades based on the signals from it (1D/1W is good for non-automated trading)
- can be used to connect to the Signal input of the TTS (TempalteTradingStrategy) by jason5480 in order to backtest it, thus effectively turning it into a strategy (instructions below in TTS CONNECTIVITY section)
Trading period can be selected from the indicator itself to limit to more interesting periods.
Arrow indications are drawn on the chart to indicate the trading conditions met in the script - light green for HTF crossover, dark green for LTF crossover and orange for LTF crossunder.
Note that the indicator performs best in trending assets and markets, and it is advisable to use additional indicators to filter the trading conditions when market/asset is expected to move sideways.
DETAILS:
It uses a couple of MACD indicators - one from the current timeframe and one from a higher timeframe, as the crossover/crossunder cases of the MACD line and the signal line indicate the potential entry/exit points.
The strategy has the following flow:
- If the weekly MACD is positive (MACD line is over the signal line) we have a trading window.
- If we have a trading window, we buy when the daily macd line crosses AND closes above the signal line.
- If we are in a position, we await the daily MACD to cross AND close under the signal line, and only then place a stop loss under the wick of that closing candle.
The user can select both the higher (HTF) and lower (LTF) timeframes. Preferably the lower timeframe should be the one that the Chart is on for better visualization.
If one to decide to use the indicator as a strategy, it implements the following buy and sell criterias, which are feed to the TTS, but can be also manually managed via adding alerts from this indicator.
Since usually the LTF is preceeding the crossover compared to the HTF, then my interpretation of the strategy and flow that it follows is allowing two different ways to enter a trade:
- crossover (and bar close) of the macd over the signal line in the HIGH TIMEFRAME (no need to look at the LOWER TIMEFRMAE)
- crossover (and bar close) of the macd over the signal line in the LOW TIMEFRAME, as in this case we need to check also that the macd line is over the signal line for the HIGH TIMEFRAME as well (like a regime filter)
The exit of the trade is based on the lower timeframe MACD only, as we create a stop loss equal to the lower wick of the bar, once the macd line crosses below the signal line on that timeframe
SETTINGS:
All of the indicator's settings are for the vanilla/general case.
User can set all of the MACD parameters for both the higher and lower (current) timeframes, currently left to default of the MACD stand-alone indicator itself.
The start-end date is a time filter that can be extermely usefull when backtesting different time periods.
TTS SETTINGS (NEEDED IF USED TO BACKTEST WITH TTS)
The TempalteTradingStrategy is a strategy script developed in Pine by jason5480, which I recommend for quick turn-around of testing different ideas on a proven and tested framework
I cannot give enough credit to the developer for the efforts put in building of the infrastructure, so I advice everyone that wants to use it first to get familiar with the concept and by checking
by checking jason5480's profile www.tradingview.com
The TTS itself is extremely functional and have a lot of properties, so its functionality is beyond the scope of the current script -
Again, I strongly recommend to be thoroughly epxlored by everyone that plans on using it.
In the nutshell it is a script that can be feed with buy/sell signals from an external indicator script and based on many configuration options it can determine how to execute the trades.
The TTS has many settings that can be applied, so below I will cover only the ones that differ from the default ones, at least according to my testing - do your own research, you may find something even better :)
The current/latest version that I've been using as of writing and testing this script is TTSv48
Settings which differ from the default ones:
- from - False (time filter is from the indicator script itself)
- Deal Conditions Mode - External (take enter/exit conditions from an external script)
- 🔌Signal 🛈➡ - Dual_MACD: 🔌Signal to TTSv48 (this is the output from the indicator script, according to the TTS convention)
- Sat/Sun - true (for crypto, in order to trade 24/7)
- Order Type - STOP (perform stop order)
- Distance Method - HHLL (HigherHighLowerLow - in order to set the SL according to the strategy definition from above)
The next are just personal preferenes, you can feel free to experiment according to your trading style
- Take Profit Targets - 0 (either 100% in or out, no incremental stepping in or out of positions)
- Dist Mul|Len Long/Short- 10 (make sure that we don't close on profitable trades by any reason)
- Quantity Method - EQUITY (personal backtesting preference is to consider each backtest as a separate portfolio, so determine the position size by 100% of the allocated equity size)
- Equity % - 100 (note above)
EXAMPLES:
If used as a stand-alone indicator, the green arrows on the bottom will represent:
- light green - MACD line crossover signal line in the HTF
- darker green - MACD line crossover signal line in the LTF
- orange - MACD line crossunder signal line in the LTF
I recommend enabling the alerts from the script to cover those cases.
If used as an input to the TTS, we'll get more decorations on the chart from the TTS itself.
In the example below we open a trade on the next day of LTF crossover, then a few days later a crossunder in the LTF occurs, so we set a SL at the low of the wick of this day. Few days later the price doesn't recover and hits that SL, so the position is closed.

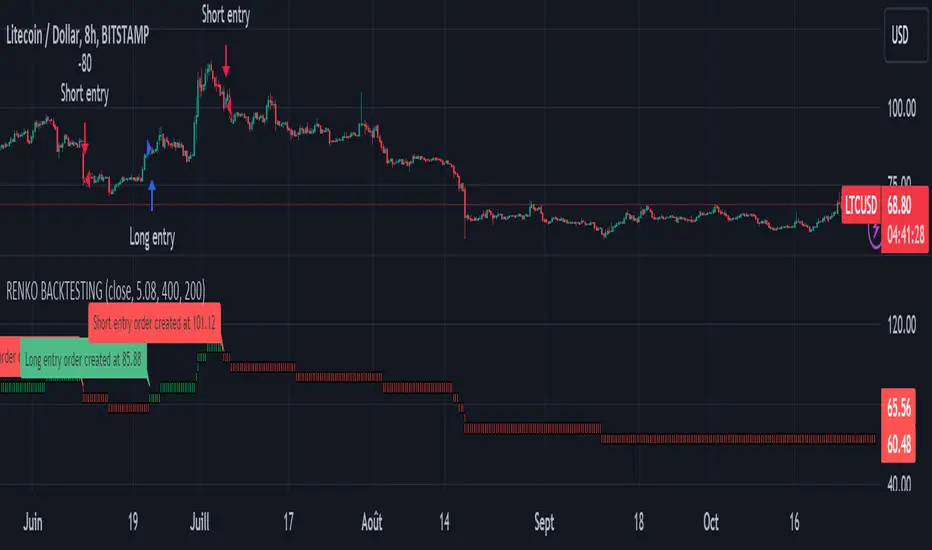
Renko StrategyRENKO STRATEGY
CAUTION : This strategy must be applied to a candlestick chart (not a Renko chart).
INTRODUCTION :
The Traditional Renko chart has been reproduced and is plotted according to the evolution of the price. It will enable us to receive buy or sell signals and follow major trends. This is a medium/long term strategy and depends a lot on the box size chosen in the parameters. There's also a money management method allowing us to reinvest part of the profits or reduce the size of orders in the event of substantial losses.
RENKO CHART :
Renko chart construction methodology :
The user must first choose the box size. The minimum is 0.00001 and there is no maximum. The default is 10. The user must then choose the source that will define the data on which the calculations will be based (high, low, open, close). By default, close is selected. The first candle on the chart is used to draw the first box with its high and low.
Each time the price changes by the amount of the box size relative to the high or low of the last box, a new box is added above or below the previous one. If price variations are less than the box size, the same box is added next to the previous one. If price variations are N (integer number) times greater than box size, N boxes are added above or below the previous one. Each box added above the previous one is a green box, while each box added below the previous one is a red box.
Conditions for drawing a green box above the previous one :
(source - high_of_the_last_box) / box_size > 1
Condition for drawing a red box below the previous one :
(low_of_the_last_box - source) / box_size > 1
If neither condition is triggered, the same box is drawn next to the previous one.
Example :
The last candle has drawn a box with low 12 and high 14. The box size is therefore 2. The strategy will look at the value of the close each time a candle ends. The current candle closes with a close equal to 15.5. As the variation from the previous high is only 1.5 (which is less than the box size), the same box is added next to the previous one. The next candle closes at 16.2. The price variation is therefore 2.2 compared with the previous high. We can now add a new green box just above the previous one, with a low of 14 and a high of 16. The same process applies if the candle's close is at least one box size below the low of the last box. In this case, a new red box is placed below the previous one.
PARAMETERS :
Source : Allows you to specify which data will be taken into account by the strategy when performing calculations. The default is close.
Box size : Size of Renko graph boxes. This is a very important parameter to choose carefully, as it has a strong impact on the strategy's performance. Defaults to 10.
Fixed Ratio : This is the amount of gain or loss at which the order quantity is changed. The default is 400, meaning that for each $400 gain or loss, the order size is increased or decreased by a user-selected amount.
Increasing Order Amount : This is the amount to be added to or subtracted from orders when the fixed ratio is reached. The default is $200, which means that for every $400 gain, $200 is reinvested in the strategy. On the other hand, for every $400 loss, the order size is reduced by $200.
Initial capital : $1000
Fees : Interactive Broker fees apply to this strategy. They are set at 0.18% of the trade value.
Slippage : 3 ticks or $0.03 per trade. Corresponds to the latency time between the moment the signal is received and the moment the order is executed by the broker.
Important : A bot has been used to test all possible box sizes to find out which one generates the highest return on BITSTAMP:LTCUSD while limiting the drawdown. This strategy is the most optimal with a box size equal to 5.08 in 8h timeframe.
BUY AND SHORT SIGNALS :
As the aim of this strategy is to follow major trends based on price movements, we need to be on the right side of price fluctuation. We trade every box reversal, i.e. we are LONG when the boxes are green indicating an uptrend and SHORT when they are red indicating a downtrend.
RISK MANAGEMENT :
This strategy can incur losses. The size of the box is decisive, as it is used to plot the RENKO chart and thus trigger buy or sell signals. It's also what allows us to manage risk. For every trade, we risk a maximum amount equal to 2 times the size of the box, i.e. :(5.08*2*nb_contract)/trade_value.
MONEY MANAGEMENT :
The fixed ratio method has been used to manage our gains and losses. For each gain of an amount equal to the value of the fixed ratio, we increase the order size by a value defined by the user in the "Increasing order amount" parameter. Similarly, each time we lose an amount equal to the value of the fixed ratio, we decrease the order size by the same user-defined value. This strategy not only increases our performance, but also our drawdown.
Enjoy the strategy and don't forget to take the trade :)
Supertrend x4 w/ Cloud FillSuperTrend is one of the most common ATR based trailing stop indicators.
The average true range (ATR) plays an important role in 'Supertrend' as the indicator uses ATR to calculate its value. The ATR indicator signals the degree of price volatility. In this version you can change the ATR calculation method from the settings. Default method is RMA, when the alternative method is SMA.
The indicator is easy to use and gives an accurate reading about an ongoing trend. It is constructed with two parameters, namely period and multiplier.
The implementation of 4 supertrends and cloud fills allows for a better overall picture of the higher and lower timeframe trend one is trading a particular security in.
The default values used while constructing a supertrend indicator is 10 for average true range or trading period.
The key aspect what differentiates this indicator is the Multiplier. The multiplier is based on how much bigger of a range you want to capture. In our case by default, it starts with 2.636 and 3.336 for Set 1 & Set 2 respectively giving a narrow band range or Short Term (ST) timeframe visual. On the other hand, the multipliers for Set 3 & Set 4 goes up to 9.736 and 8.536 for the multiplier respectively giving a large band range or Long Term (LT) timeframe visual.
A ‘Supertrend’ indicator can be used on equities, futures or forex, or even crypto markets and also on minutes, hourly, daily, and weekly charts as well, but generally, it fails in a sideways-moving market. That's why with this implementation it enables one to stay out of the market if they choose to do so when the market is ranging.
This Supertrend indicator is modelled around trends and areas of interest versus buy and sell signals. Therefore, to better understand this indicator, one must calibrate it to one's need first, which means day trader (shorter timeframe) vs swing trader (longer time frame), and then understand how it can be utilized to improve your entries, exits, risk and position sizing.
Example:
In this chart shown above using SPX500:OANDA, 15R Time Frame, we can see that there is at any give time 1 to 4 clouds/bands of Supertrends. These four are called Set 1, Set 2, Set 3 and Set 4 in the indicator. Set's 1 & 2 are considered short term, whereas Set's 3 & 4 are considered long term. The term short and long are subjective based on one's trading style. For instance, if a person is a 1min chart trader, which would be short term, to get an idea of the trend you would have to look at a longer time frame like a 5min for instance. Similarly, in this cases the timeframes = Multiplier value that you set.
Optional Ideas:
+ Apply some basic EMA/SMA indicator script of your choice for easier understanding of the trend or to allow smooth transition to using this indicator.
+ Split the chart into two vertical layouts and applying this same script coupled with xdecow's 2 WWV candle painting script on both the layouts. Now you can use the left side of the chart to show all bearish move candles only (make the bullish candles transparent) and do the opposite for the right side of the chart. This way you enhance focus to just stick to one side at a given time.
Credits:
This indicator is a derivative of the fine work done originally by KivancOzbilgic
Here is the source to his original indicator: ).
Disclaimer:
This indicator and tip is for educational and entertainment purposes only. This not does constitute to financial advice of any sort.

Strategy Myth-Busting #12 - OSGFC+SuperTrend - [MYN]This is part of a new series we are calling "Strategy Myth-Busting" where we take open public manual trading strategies and automate them. The goal is to not only validate the authenticity of the claims but to provide an automated version for traders who wish to trade autonomously.
Our 12th one is an automated version of the "The Most Powerful Tradingview Buy Sell Signal Indicator " strategy from "Power of Trading" who doesn't make any official claims but watching how he trades with this, it on the surface looked promising. The strategy author uses this on the 15 min strategy on mostly FOREX. Unfortunately as indicated by the backtest results below, we were not able to substantiate any good positive trading metrics from this, be it Profit, Markdown, Num Of Trades etc. This does seem to do okay with some entries but perhaps adding another indicator to this to filter out more noise might make it better. At least how this strategy is presented now, this is not something I recommend anyone use.
This strategy uses a combination of 2 open-source public indicators:
SuperTrend by TradingView Internal
One-Sided Gaussian Filter w/ Channels By Loxx
The SuperTrend indicator and the One-Sided Gaussian Filter complement each other by providing a more complete and accurate picture of market trends. The SuperTrend indicator is used to identify trends. It does this by calculating a moving average of the underlying securities price and then comparing the current price to the moving average. When the current price is above the moving average, the trend is considered bullish, and when it is below, the trend is considered bearish.
The One-Sided Gaussian Filter is a mathematical tool that is used to smooth out fluctuations in financial data. It does this by removing random noise from the data, making it easier to identify patterns and trends.
When the SuperTrend indicator is used in conjunction with the One-Sided Gaussian Filter, the smoothed price data generated by the filter is used as the input for the SuperTrend calculation. This provides a more accurate representation of market trends and helps to eliminate false signals generated by short-term price movements. As a result, the SuperTrend indicator is able to more accurately identify the underlying trend in the market and provide traders with a cleaner and more reliable signal to act upon.
In summary, the SuperTrend indicator and the One-Sided Gaussian Filter complement each other by providing a more accurate and reliable representation of market trends, resulting in improved performance for traders.
If you know of or have a strategy you want to see myth-busted or just have an idea for one, please feel free to message me.
Trading Rules
15 min candles
FOREX or Crypto
Stop loss at swing high/low | 1.5 risk/ratio
Long Condition
SuperTrend and OSGFC generate buy signal
Close Buy on Gaussian generating a sell signal
Short Condition
SuperTrend and OSGFC generate sell signal
Close Buy on Gaussian generating a buy signal

theme_presetsStyle Made Easy with 175 Reversable light/dark themes
Built on to of my theme engine, so any tools built with one
will work with the other.
getTheme(_input)
Get a theme by name. (see lib for copy/paste list)
Parameters:
_input : string Name of Theme to use.
apathy()
Theme preset -> "Apathy"
Returns: Theme object
apprentice()
Theme preset -> "Apprentice"
Returns: Theme object
ashes()
Theme preset -> "Ashes"
Returns: Theme object
atelier_cave()
Theme preset -> "Atelier Cave"
Returns: Theme object
atelier_dune()
Theme preset -> "Atelier Dune"
Returns: Theme object
atelier_estuary()
Theme preset -> "Atelier Estuary"
Returns: Theme object
atelier_forest()
Theme preset -> "Atelier Forest"
Returns: Theme object
atelier_heath()
Theme preset -> "Atelier Heath"
Returns: Theme object
atelier_lakeside()
Theme preset -> "Atelier Lakeside"
Returns: Theme object
atelier_plateau()
Theme preset -> "Atelier Plateau"
Returns: Theme object
atelier_savanna()
Theme preset -> "Atelier Savanna"
Returns: Theme object
atelier_seaside()
Theme preset -> "Atelier Seaside"
Returns: Theme object
atelier_sulphurpool()
Theme preset -> "Atelier Sulphurpool"
Returns: Theme object
atlas()
Theme preset -> "Atlas"
Returns: Theme object
ayu()
Theme preset -> "Ayu"
Returns: Theme object
ayu_mirage()
Theme preset -> "Ayu Mirage"
Returns: Theme object
bespin()
Theme preset -> "Bespin"
Returns: Theme object
black_metal()
Theme preset -> "Black Metal"
Returns: Theme object
black_metal_bathory()
Theme preset -> "Black Metal (bathory)"
Returns: Theme object
black_metal_burzum()
Theme preset -> "Black Metal (burzum)"
Returns: Theme object
black_metal_funeral()
Theme preset -> "Black Metal (dark Funeral)"
Returns: Theme object
black_metal_gorgoroth()
Theme preset -> "Black Metal (gorgoroth)"
Returns: Theme object
black_metal_immortal()
Theme preset -> "Black Metal (immortal)"
Returns: Theme object
black_metal_khold()
Theme preset -> "Black Metal (khold)"
Returns: Theme object
black_metal_marduk()
Theme preset -> "Black Metal (marduk)"
Returns: Theme object
black_metal_mayhem()
Theme preset -> "Black Metal (mayhem)"
Returns: Theme object
black_metal_nile()
Theme preset -> "Black Metal (nile)"
Returns: Theme object
black_metal_venom()
Theme preset -> "Black Metal (venom)"
Returns: Theme object
blue_forest()
Theme preset -> "Blue Forest"
Returns: Theme object
blueish()
Theme preset -> "Blueish"
Returns: Theme object
brewer()
Theme preset -> "Brewer"
Returns: Theme object
bright()
Theme preset -> "Bright"
Returns: Theme object
brogrammer()
Theme preset -> "Brogrammer"
Returns: Theme object
brush_trees()
Theme preset -> "Brush Trees"
Returns: Theme object
catppuccin()
Theme preset -> "Catppuccin"
Returns: Theme object
chalk()
Theme preset -> "Chalk"
Returns: Theme object
circus()
Theme preset -> "Circus"
Returns: Theme object
classic()
Theme preset -> "Classic"
Returns: Theme object
clrs()
Theme preset -> "Colors"
Returns: Theme object
codeschool()
Theme preset -> "Codeschool"
Returns: Theme object
cupcake()
Theme preset -> "Cupcake"
Returns: Theme object
cupertino()
Theme preset -> "Cupertino"
Returns: Theme object
da_one_black()
Theme preset -> "Da One Black"
Returns: Theme object
da_one_gray()
Theme preset -> "Da One Gray"
Returns: Theme object
da_one_ocean()
Theme preset -> "Da One Ocean"
Returns: Theme object
da_one_paper()
Theme preset -> "Da One Paper"
Returns: Theme object
da_one_sea()
Theme preset -> "Da One Sea"
Returns: Theme object
da_one_white()
Theme preset -> "Da One White"
Returns: Theme object
danqing()
Theme preset -> "Danqing"
Returns: Theme object
darcula()
Theme preset -> "Darcula"
Returns: Theme object
dark_violet()
Theme preset -> "Dark Violet"
Returns: Theme object
darkmoss()
Theme preset -> "Darkmoss"
Returns: Theme object
darktooth()
Theme preset -> "Darktooth"
Returns: Theme object
decaf()
Theme preset -> "Decaf"
Returns: Theme object
dirtysea()
Theme preset -> "Dirtysea"
Returns: Theme object
dracula()
Theme preset -> "Dracula"
Returns: Theme object
edge()
Theme preset -> "Edge"
Returns: Theme object
eighties()
Theme preset -> "Eighties"
Returns: Theme object
embers()
Theme preset -> "Embers"
Returns: Theme object
emil()
Theme preset -> "Emil"
Returns: Theme object
equilibrium()
Theme preset -> "Equilibrium"
Returns: Theme object
equilibrium_gray()
Theme preset -> "Equilibrium Gray"
Returns: Theme object
espresso()
Theme preset -> "Espresso"
Returns: Theme object
eva()
Theme preset -> "Eva"
Returns: Theme object
everforest()
Theme preset -> "Everforest"
Returns: Theme object
flat()
Theme preset -> "Flat"
Returns: Theme object
framer()
Theme preset -> "Framer"
Returns: Theme object
fruit_soda()
Theme preset -> "Fruit Soda"
Returns: Theme object
gigavolt()
Theme preset -> "Gigavolt"
Returns: Theme object
github()
Theme preset -> "Github"
Returns: Theme object
google()
Theme preset -> "Google"
Returns: Theme object
gotham()
Theme preset -> "Gotham"
Returns: Theme object
grayscale()
Theme preset -> "Grayscale"
Returns: Theme object
green_screen()
Theme preset -> "Green Screen"
Returns: Theme object
gruber()
Theme preset -> "Gruber"
Returns: Theme object
gruvbox_hard()
Theme preset -> "Gruvbox Dark, Hard"
Returns: Theme object
gruvbox_medium()
Theme preset -> "Gruvbox Dark, Medium"
Returns: Theme object
gruvbox_pale()
Theme preset -> "Gruvbox Dark, Pale"
Returns: Theme object
gruvbox_soft()
Theme preset -> "Gruvbox Dark, Soft"
Returns: Theme object
gruvbox_material_hard()
Theme preset -> "Gruvbox Material Dark, Hard"
Returns: Theme object
gruvbox_material_medium()
Theme preset -> "Gruvbox Material Dark, Medium"
Returns: Theme object
gruvbox_material_soft()
Theme preset -> "Gruvbox Material Dark, Soft"
Returns: Theme object
hardcore()
Theme preset -> "Hardcore"
Returns: Theme object
harmonic16()
Theme preset -> "Harmonic16"
Returns: Theme object
heetch()
Theme preset -> "Heetch"
Returns: Theme object
helios()
Theme preset -> "Helios"
Returns: Theme object
hopscotch()
Theme preset -> "Hopscotch"
Returns: Theme object
horizon()
Theme preset -> "Horizon"
Returns: Theme object
horizon_terminal()
Theme preset -> "Horizon Terminal"
Returns: Theme object
humanoid()
Theme preset -> "Humanoid"
Returns: Theme object
ia()
Theme preset -> "Ia"
Returns: Theme object
icy()
Theme preset -> "Icy"
Returns: Theme object
ir_black()
Theme preset -> "Ir Black"
Returns: Theme object
isotope()
Theme preset -> "Isotope"
Returns: Theme object
kanagawa()
Theme preset -> "Kanagawa"
Returns: Theme object
katy()
Theme preset -> "Katy"
Returns: Theme object
kimber()
Theme preset -> "Kimber"
Returns: Theme object
lime()
Theme preset -> "Lime"
Returns: Theme object
london_tube()
Theme preset -> "London Tube"
Returns: Theme object
macintosh()
Theme preset -> "Macintosh"
Returns: Theme object
marrakesh()
Theme preset -> "Marrakesh"
Returns: Theme object
materia()
Theme preset -> "Materia"
Returns: Theme object
material()
Theme preset -> "Material"
Returns: Theme object
materialdarker()
Theme preset -> "Material Darker"
Returns: Theme object
material_palenight()
Theme preset -> "Material Palenight"
Returns: Theme object
material_vivid()
Theme preset -> "Material Vivid"
Returns: Theme object
mellow_purple()
Theme preset -> "Mellow Purple"
Returns: Theme object
mocha()
Theme preset -> "Mocha"
Returns: Theme object
monokai()
Theme preset -> "Monokai"
Returns: Theme object
Nebula()
Theme preset -> "Nebula"
Returns: Theme object
nord()
Theme preset -> "Nord"
Returns: Theme object
nova()
Theme preset -> "Nova"
Returns: Theme object
ocean()
Theme preset -> "Ocean"
Returns: Theme object
oceanicnext()
Theme preset -> "Oceanicnext"
Returns: Theme object
onedark()
Theme preset -> "Onedark"
Returns: Theme object
outrun()
Theme preset -> "Outrun"
Returns: Theme object
pandora()
Theme preset -> "Pandora"
Returns: Theme object
papercolor()
Theme preset -> "Papercolor"
Returns: Theme object
paraiso()
Theme preset -> "Paraiso"
Returns: Theme object
pasque()
Theme preset -> "Pasque"
Returns: Theme object
phd()
Theme preset -> "Phd"
Returns: Theme object
pico()
Theme preset -> "Pico"
Returns: Theme object
pinky()
Theme preset -> "Pinky"
Returns: Theme object
pop()
Theme preset -> "Pop"
Returns: Theme object
porple()
Theme preset -> "Porple"
Returns: Theme object
primer()
Theme preset -> "Primer"
Returns: Theme object
purpledream()
Theme preset -> "Purpledream"
Returns: Theme object
qualia()
Theme preset -> "Qualia"
Returns: Theme object
railscasts()
Theme preset -> "Railscasts"
Returns: Theme object
rebecca()
Theme preset -> "Rebecca"
Returns: Theme object
rose_pine()
Theme preset -> "Rosé Pine"
Returns: Theme object
rose_pine_dawn()
Theme preset -> "Rosé Pine Dawn"
Returns: Theme object
rose_pine_moon()
Theme preset -> "Rosé Pine Moon"
Returns: Theme object
sagelight()
Theme preset -> "Sagelight"
Returns: Theme object
sakura()
Theme preset -> "Sakura"
Returns: Theme object
sandcastle()
Theme preset -> "Sandcastle"
Returns: Theme object
seti_ui()
Theme preset -> "Seti Ui"
Returns: Theme object
shades_of_purple()
Theme preset -> "Shades Of Purple"
Returns: Theme object
shadesmear()
Theme preset -> "Shadesmear"
Returns: Theme object
shapeshifter()
Theme preset -> "Shapeshifter"
Returns: Theme object
silk()
Theme preset -> "Silk"
Returns: Theme object
snazzy()
Theme preset -> "Snazzy"
Returns: Theme object
solar_flare()
Theme preset -> "Solar Flare"
Returns: Theme object
solarized()
Theme preset -> "Solarized"
Returns: Theme object
spaceduck()
Theme preset -> "Spaceduck"
Returns: Theme object
spacemacs()
Theme preset -> "Spacemacs"
Returns: Theme object
stella()
Theme preset -> "Stella"
Returns: Theme object
still_alive()
Theme preset -> "Still Alive"
Returns: Theme object
summercamp()
Theme preset -> "Summercamp"
Returns: Theme object
summerfruit()
Theme preset -> "Summerfruit"
Returns: Theme object
synth_midnight_terminal()
Theme preset -> "Synth Midnight Terminal"
Returns: Theme object
tango()
Theme preset -> "Tango"
Returns: Theme object
tender()
Theme preset -> "Tender"
Returns: Theme object
tokyo_city()
Theme preset -> "Tokyo City"
Returns: Theme object
tokyo_city_terminal()
Theme preset -> "Tokyo City Terminal"
Returns: Theme object
tokyo_night()
Theme preset -> "Tokyo Night"
Returns: Theme object
tokyo_night_storm()
Theme preset -> "Tokyo Night Storm"
Returns: Theme object
tokyo_night_terminal()
Theme preset -> "Tokyo Night Terminal"
Returns: Theme object
tokyo_night_terminal_storm()
Theme preset -> "Tokyo Night Terminal Storm"
Returns: Theme object
tokyodark()
Theme preset -> "Tokyodark"
Returns: Theme object
tokyodark_terminal()
Theme preset -> "Tokyodark Terminal"
Returns: Theme object
tomorrow()
Theme preset -> "Tomorrow"
Returns: Theme object
tomorrow_night()
Theme preset -> "Tomorrow Night"
Returns: Theme object
tomorrow_night_eighties()
Theme preset -> "Tomorrow Night Eighties"
Returns: Theme object
twilight()
Theme preset -> "Twilight"
Returns: Theme object
unikitty()
Theme preset -> "Unikitty"
Returns: Theme object
unikitty_reversible()
Theme preset -> "Unikitty Reversible"
Returns: Theme object
uwunicorn()
Theme preset -> "Uwunicorn"
Returns: Theme object
vice()
Theme preset -> "Vice"
Returns: Theme object
vulcan()
Theme preset -> "Vulcan"
Returns: Theme object
windows_10()
Theme preset -> "Windows 10"
Returns: Theme object
windows_95()
Theme preset -> "Windows 95"
Returns: Theme object
windows_high_contrast()
Theme preset -> "Windows High Contrast"
Returns: Theme object
windows_nt()
Theme preset -> "Windows Nt"
Returns: Theme object
woodland()
Theme preset -> "Woodland"
Returns: Theme object
xcode_dusk()
Theme preset -> "Xcode Dusk"
Returns: Theme object

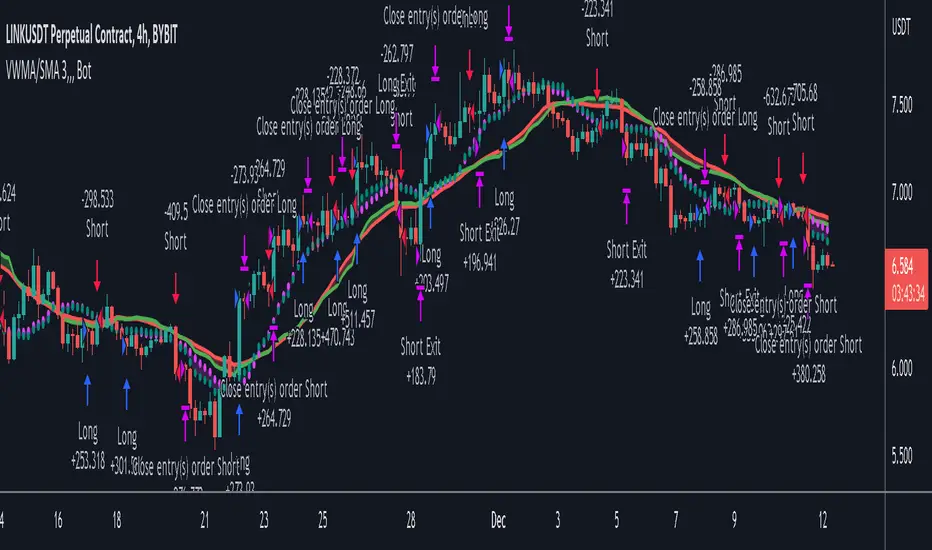
VWMA/SMA 3Commas BotThis strategy utilizes two pairs of different Moving Averages, two Volume-Weighted Moving Averages (VWMA) and two Simple Moving Averages (SMA).
There is a FAST and SLOW version of each VWMA and SMA.
The concept behind this strategy is that volume is not taken into account when calculating a Simple Moving Average.
Simple Moving Averages are often used to determine the dominant direction of price movement and to help a trader look past any short-term volatility or 'noise' from price movement, and instead determine the OVERALL direction of price movement so that one can trade in that direction (trend-following) or look for opportunities to trade AGAINST that direction (fading).
By comparing the different movements of a Volume-Weighted Moving Average against a Simple Moving Average of the same length, a trader can get a better picture of what price movements are actually significant, helping to reduce false signals that might occur from only using Simple Moving Averages.
The practical applications of this strategy are identifying dominant directional trends. These can be found when the Volume Weighted Moving Average is moving in the same direction as the Simple Moving Average, and ideally, tracking above it.
This would indicate that there is sufficient volume supporting an uptrend or downtrend, and thus gives traders additional confirmation to potentially look for a trade in that direction.
One can initially look for the Fast VWMA to track above the Fast SMA as your initial sign of bullish confirmation (reversed for downtrending markets). Then, when the Fast VWMA crosses over the Slow SMA, one can determine additional trend strength. Finally, when the Slow VWMA crosses over the Slow SMA, one can determine that the trend is truly strong.
Traders can choose to look for trade entries at either of those triggers, depending on risk tolerance and risk appetite.
Furthermore, this strategy can be used to identify divergence or weakness in trending movements. This is very helpful for identifying potential areas to exit one's trade or even look for counter-trend trades (reversals).
These moments occur when the Volume-Weighted Moving Average, either fast or slow, begins to trade in the opposite direction as their Simple Moving Average counterpart.
For instance, if price has been trending upwards for awhile, and the Fast VWMA begins to trade underneath the Fast SMA, this is an indication that volume is beginning to falter. Uptrends need appropriate volume to continue moving with momentum, so when we see volume begin to falter, it can be a potential sign of an upcoming reversal in trend.
Depending on how quickly one wants to enter into a movement, one could look for crosses of the Fast VWMA under/over the Fast SMA, crosses of the Fast VWMA over/under the Slow SMA, or crosses over/under of the Slow VWMA and the Slow SMA.
This concept was originally published here on TradingView by ProfitProgrammers.
Here is a link to his original indicator script:
I have added onto this concept by:
converting the original indicator into a strategy tester for backtesting
adding the ability to conveniently test long or short strategies, or both
adding the ability to calculate dynamic position sizes
adding the ability to calculate dynamic stop losses and take profit levels using the Average True Range
adding the ability to exit trades based on overbought/oversold crosses of the Stochastic RSI
conveniently switch between different thresholds or speeds of the Moving Average crosses to test different strategies on different asset classes
easily hook this strategy up to 3Commas for automation via their DCA bot feature
Full credit to ProfitProgrammers for the original concept and idea.
Any feedback or suggestions are greatly appreciated.
Signs of the Times [LucF]█ OVERVIEW
This oscillator calculates the directional strength of bars using a primitive weighing mechanism based on a small number of what I consider to be fundamental properties of a bar. It does not consider the amplitude of price movements, so can be used as a complement to momentum-based oscillators. It thus belongs to the same family of indicators as my Bar Balance , Volume Ticks , Efficient work , Volume Buoyancy or my Delta Volume indicators.
█ CONCEPTS
The calculations underlying Signs of the Times (SOTT) use a simple, oft-explored concept: measure bar attributes, assign a weight to them, and aggregate results to provide an evaluation of a bar's directional strength. Bull and bear weights are added independently, then subtracted and divided by the maximum possible weight, so the final calculation looks like this:
(up - dn) / weightRange
SOTT has a zero centerline and oscillates between +1 and -1. Ten elementary properties are evaluated. Most carry a weight of one, a few are doubly weighted. All properties are evaluated using only the current bar's values or by comparing its values to those of the preceding bar. The bull conditions follow; their inverse applies to bear conditions:
Weight of 1
• Bar's close is greater than the bar's open (bar is considered to be of "up" polarity)
• Rising open
• Rising high
• Rising low
• Rising close
• Bar is up and its body size is greater than that of the previous bar
• Bar is up and its body size is greater than the combined size of wicks
Weight of 2
• Gap to the upside
• Efficient Work when it is positive
• Bar is up and volume is greater than that of the previous bar (this only kicks in if volume is actually available on the chart's data feed)
Except for the Efficient Work weight, which is a +1 to -1 float value multiplied by 2, all weights are discrete; either zero or the full weight of 1 or 2 is generated. This will cause any gap, for example, to generate a weight of +2 or -2, regardless of the gap's size. That is the reason why the oscillator is oblivious to the amplitude of price movements.
You can see the code used to calculate SOTT in my ta library 's `sott()` function.
█ HOW TO USE THE INDICATOR
No videos explain this indicator and none are planned; reading this description or the script's code is the only way to understand what Signs of the Times does.
Load the indicator on an active chart (see here if you don't know how).
The default configuration displays:
• An Arnaud-Legoux moving average of length 20 of the instant SOTT value. This is the signal line.
• A fill between the MA and the centerline.
• Levels at arbitrary values of +0.3 and -0.3.
• A channel between the signal line and its MA (a simple MA of length 20), which can be one of four colors:
• Bull (green): The signal line is above its MA.
• Strong bull (lime): The bull condition is fulfilled and the signal line is above the centerline.
• Bear (red): The signal line is below its MA.
• Strong bear (pink): The bear condition is fulfilled and the signal line is below the centerline.
The script's "Inputs" tab allows you to:
• Choose a higher timeframe to calculate the indicator's values. This can be useful to get a wider perspective of the indicator's values.
If you elect to use a higher timeframe, make sure that your chart's timeframe is always lower than the higher timeframe you specified,
as calculating on a timeframe lower than the chart's does not make much sense because the indicator is then displaying only the value of the last intrabar in the chart bar.
• Specify the type of MA used to produce the signal line. Use a length of 1 or the Data Window to see the instant value of SOTT. It is quite noisy, thus the need to average it.
• Specify the type of MA applied to the signal line. The idea here is to provide context to the signal.
• Control the display and colors of the lines and fills.
The first pane of this publication's chart shows the default setup. The second one shows only a monochrome signal line.
Using the "Style" tab of the indicator's settings, you can change the type and width of the lines, and the level values.
█ INTERPRETATION
Remember that Signs of the Times evaluates directional bar strength — not price movement. Its highs and lows do not reflect price, but the strength of chart bars. The fact that SOTT knows nothing of how far price moves or of trends is easy to forget. As such, I think SOTT is best used as a confirmation tool. Chart movements may appear to be easy to read when looking at historical bars, but when you have to make go-no-go decisions on the last bar, the landscape often becomes murkier. By providing a quantitative evaluation of the strength of the last few bars, which is not always easily discernible by simply looking at them, SOTT aims to help you decide if the short-term past favors the bets you are considering. Can SOTT predict the future? Of course not.
While SOTT uses completely different calculations than classical momentum oscillators, its profile shares many of their characteristics. This could lead one to infer that directional bar strength correlates with price movement, which could in turn lead one to conclude that indicators such as this one are useless, or that they can be useful tools to confirm momentum oscillators or other models of price movement. The call is, of course, up to you. You can try, for example, to compare a Wilder MA of SOTT to an RSI of the same length.
One key difference with momentum oscillators is that SOTT is much less sensitive to large price movements. The default Arnaud-Legoux MA used for the signal line makes it quite active; you can use a more quiet SMA or EMA if you prefer to tone it down.
In systems where it can be useful to only enter or exit on short-term strength, an average of SOTT values over the last 3 to 5 bars can be used as a more quiet filter than a momentum oscillator would.
█ NOTES
My publications often go through a long gestation period where I use them on my charts or in systems before deciding if they are worth a publication. With an incubation period of more than three years, Signs of the Times holds the record. The properties SOTT currently evaluates result from the systematic elimination of contaminants over that lengthy period of time. It was long because of my usual, slow gear, but also because I had to try countless combinations of conditions before realizing that, contrary to my intuition, best results were achieved by:
• Keeping the number of evaluated properties to the absolute minimum.
• Limiting the evaluation's scope to the current and preceding bar.
• Choosing properties that, in my view, were unmistakably indicative of bullish/bearish conditions.
Repainting
As most oscillators, the indicator provides live realtime values that will recalculate with chart updates. It will thus repaint in real time, but not on historical values. To learn more about repainting, see the Pine Script™ User Manual's page on the subject .
LibraryCOTLibrary "LibraryCOT"
This library provides tools to help Pine programmers fetch Commitment of Traders (COT) data for futures.
rootToCFTCCode(root)
Accepts a futures root and returns the relevant CFTC code.
Parameters:
root : Root prefix of the future's symbol, e.g. "ZC" for "ZC1!"" or "ZCU2021".
Returns: The part of a COT ticker corresponding to `root`, or "" if no CFTC code exists for the `root`.
currencyToCFTCCode(curr)
Converts a currency string to its corresponding CFTC code.
Parameters:
curr : Currency code, e.g., "USD" for US Dollar.
Returns: The corresponding to the currency, if one exists.
optionsToTicker(includeOptions)
Returns the part of a COT ticker using the `includeOptions` value supplied, which determines whether options data is to be included.
Parameters:
includeOptions : A "bool" value: 'true' if the symbol should include options and 'false' otherwise.
Returns: The part of a COT ticker: "FO" for data that includes options and "F" for data that doesn't.
metricNameAndDirectionToTicker(metricName, metricDirection)
Returns a string corresponding to a metric name and direction, which is one component required to build a valid COT ticker ID.
Parameters:
metricName : One of the metric names listed in this library's chart. Invalid values will cause a runtime error.
metricDirection : Metric direction. Possible values are: "Long", "Short", "Spreading", and "No direction". Valid values vary with metrics. Invalid values will cause a runtime error.
Returns: The part of a COT ticker ID string, e.g., "OI_OLD" for "Open Interest" and "No direction", or "TC_L" for "Traders Commercial" and "Long".
typeToTicker(metricType)
Converts a metric type into one component required to build a valid COT ticker ID. See the "Old and Other Futures" section of the CFTC's Explanatory Notes for details on types.
Parameters:
metricType : Metric type. Accepted values are: "All", "Old", "Other".
Returns: The part of a COT ticker.
convertRootToCOTCode(mode, convertToCOT)
Depending on the `mode`, returns a CFTC code using the chart's symbol or its currency information when `convertToCOT = true`. Otherwise, returns the symbol's root or currency information. If no COT data exists, a runtime error is generated.
Parameters:
mode : A string determining how the function will work. Valid values are:
"Root": the function extracts the futures symbol root (e.g. "ES" in "ESH2020") and looks for its CFTC code.
"Base currency": the function extracts the first currency in a pair (e.g. "EUR" in "EURUSD") and looks for its CFTC code.
"Currency": the function extracts the quote currency ("JPY" for "TSE:9984" or "USDJPY") and looks for its CFTC code.
"Auto": the function tries the first three modes (Root -> Base Currency -> Currency) until a match is found.
convertToCOT : "bool" value that, when `true`, causes the function to return a CFTC code. Otherwise, the root or currency information is returned. Optional. The default is `true`.
Returns: If `convertToCOT` is `true`, the part of a COT ticker ID string. If `convertToCOT` is `false`, the root or currency extracted from the current symbol.
COTTickerid(COTType, CTFCCode, includeOptions, metricName, metricDirection, metricType)
Returns a valid TradingView ticker for the COT symbol with specified parameters.
Parameters:
COTType : A string with the type of the report requested with the ticker, one of the following: "Legacy", "Disaggregated", "Financial".
CTFCCode : The for the asset, e.g., wheat futures (root "ZW") have the code "001602".
includeOptions : A boolean value. 'true' if the symbol should include options and 'false' otherwise.
metricName : One of the metric names listed in this library's chart.
metricDirection : Direction of the metric, one of the following: "Long", "Short", "Spreading", "No direction".
metricType : Type of the metric. Possible values: "All", "Old", and "Other".
Returns: A ticker ID string usable with `request.security()` to fetch the specified Commitment of Traders data.

R-squared Adaptive T3 Ribbon Filled Simple [Loxx]R-squared Adaptive T3 Ribbon Filled Simple is a T3 ribbons indicator that uses a special implementation of T3 that is R-squared adaptive.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Alerts
Signals
Loxx's Expanded Source Types
T3 Volatility Quality Index (VQI) w/ DSL & Pips Filtering [Loxx]T3 Volatility Quality Index (VQI) w/ DSL & Pips Filtering is a VQI indicator that uses T3 smoothing and discontinued signal lines to determine breakouts and breakdowns. This also allows filtering by pips.***
What is the Volatility Quality Index ( VQI )?
The idea behind the volatility quality index is to point out the difference between bad and good volatility in order to identify better trade opportunities in the market. This forex indicator works using the True Range algorithm in combination with the open, close, high and low prices.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Signals
Alerts
Related indicators
Zero-line Volatility Quality Index (VQI)
Volatility Quality Index w/ Pips Filtering
Variety Moving Average Waddah Attar Explosion (WAE)
***This indicator is tuned to Forex. If you want to make it useful for other tickers, you must change the pip filtering value to match the asset. This means that for BTC, for example, you likely need to use a value of 10,000 or more for pips filter.

R-squared Adaptive T3 w/ DSL [Loxx]R-squared Adaptive T3 w/ DSL is the following T3 indicator but with Discontinued Signal Lines added to reduce noise and thereby increase signal accuracy. This adaptation makes this indicator lower TF scalp friendly.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
EMA and FEMA Signla/DSL smoothing
Loxx's Expanded Source Types
Pips-Stepped, R-squared Adaptive T3 [Loxx]Pips-Stepped, R-squared Adaptive T3 is a a T3 moving average with optional adaptivity, trend following, and pip-stepping. This indicator also uses optional flat coloring to determine chops zones. This indicator is R-squared adaptive. This is also an experimental indicator.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination (R-squared), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average.
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Bar coloring
Signals
Alerts
Flat coloring
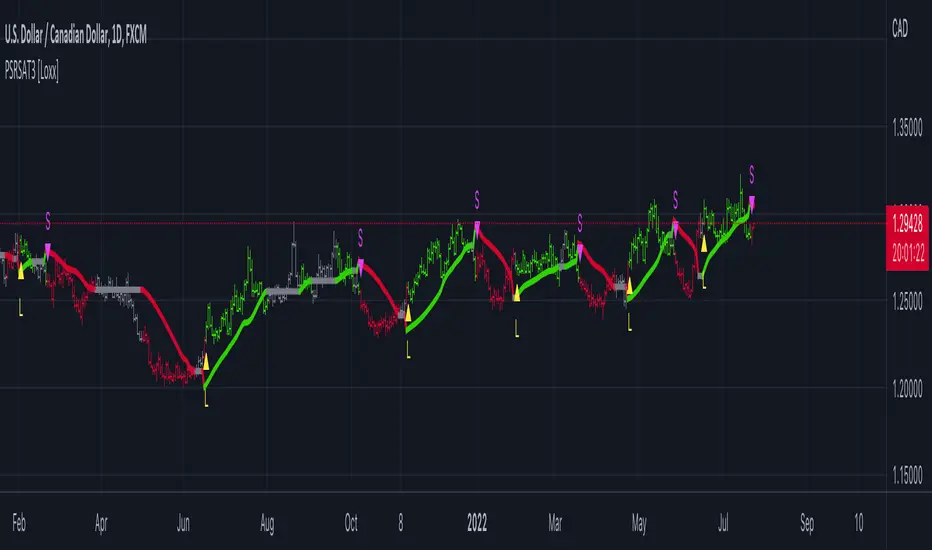
Weight Gain 4000 - (Adjustable Volume Weighted MA) - [mutantdog]Short Version:
This is a fairly self-contained system based upon a moving average crossover with several unique features. The most significant of these is the adjustable volume weighting system, allowing for transformations between standard and weighted versions of each included MA. With this feature it is possible to apply partial weighting which can help to improve responsiveness without dramatically altering shape. Included types are SMA, EMA, WMA, RMA, hSMA, DEMA and TEMA. Potentially more will be added in future (check updates below).
In addition there are a selection of alternative 'weighted' inputs, a pair of Bollinger-style deviation bands, a separate price tracker and a bunch of alert presets.
This can be used out-of-the-box or tweaked in multiple ways for unusual results. Default settings are a basic 8/21 EMA cross with partial volume weighting. Dev bands apply to MA2 and are based upon the type and the volume weighting. For standard Bollinger bands use SMA with length 20 and try adding a small amount of volume weighting.
A more detailed breakdown of the functionality follows.
Long Version:
ADJUSTABLE VOLUME WEIGHTING
In principle any moving average should have a volume weighted analogue, the standard VWMA is just an SMA with volume weighting for example. Actually, we can consider the SMA to be a special case where volume is a constant 1 per bar (the value is somewhat arbitrary, the important part is that it's constant). Similar principles apply to the 'elastic' EVWMA which is the volume weighted analogue of an RMA. In any case though, where we have standard and weighted variants it is possible to transform one into the other by gradually increasing or decreasing the weighting, which forms the basis of this system. This is not just a simple multiplier however, that would not work due to the relative proportions being the same when set at any non zero value. In order to create a meaningful transformation we need to use an exponent instead, eg: volume^x , where x is a variable determined in this case by the 'volume' parameter. When x=1, the full volume weighting applies and when x=0, the volume will be reduced to a constant 1. Values in between will result in the respective partial weighting, for example 0.5 will give the square root of the volume.
The obvious question here though is why would you want to do this? To answer that really it is best to actually try it. The advantages that volume weighting can bring to a moving average can sometimes come at the cost of unwanted or erratic behaviour. While it can tend towards much closer price tracking which may be desirable, sometimes it needs moderating especially in markets with lower liquidity. Here the adjustability can be useful, in many cases i have found that adding a small amount of volume weighting to a chosen MA can help to improve its responsiveness without overpowering it. Another possible use case would be to have two instances of the same MA with the same length but different weightings, the extent to which these diverge from each other can be a useful indicator of trend strength. Other uses will become apparent with experimentation and can vary from one market to another.
THE INCLUDED MODES
At the time of publication, there are 7 included moving average types with plans to add more in future. For now here is a brief explainer of what's on offer (continuing to use x as shorthand for the volume parameter), starting with the two most common types.
SMA: As mentioned above this is essentially a standard VWMA, calculated here as sma(source*volume^x,length)/sma(volume^x,length). In this case when x=0 then volume=1 and it reduces to a standard SMA.
RMA: Again mentioned above, this is an EVWMA (where E stands for elastic) with constant weighting. Without going into detail, this method takes the 1/length factor of an RMA and replaces it with volume^x/sum(volume^x,length). In this case again we can see that when x=0 then volume=1 and the original 1/length factor is restored.
EMA: This follows the same principle as the RMA where the standard 2/(length+1) factor is replaced with (2*volume^x)/(sum(volume^x,length)+volume^x). As with an RMA, when x=0 then volume=1 and this reduces back to the standard 2/(length+1).
DEMA: Just a standard Double EMA using the above.
TEMA: Likewise, a standard Triple EMA using the above.
hSMA: This is the same as the SMA except it uses harmonic mean calculations instead of arithmetic. In most cases the differences are negligible however they can become more pronounced when volume weighting is introduced. Furthermore, an argument can be made that harmonic mean calculations are better suited to downtrends or bear markets, in principle at least.
WMA: Probably the most contentious one included. Follows the same basic calculations as for the SMA except uses a WMA instead. Honestly, it makes little sense to combine both linear and volume weighting in this manner, included only for completeness and because it can easily be done. It may be the case that a superior composite could be created with some more complex calculations, in which case i may add that later. For now though this will do.
An additional 'volume filter' option is included, which applies a basic filter to the volume prior to calculation. For types based around the SMA/VWMA system, the volume filter is a WMA-4, for types based around the RMA/EVWMA system the filter is a RMA-2.
As and when i add more they will be listed in the updates at the bottom.
WEIGHTED INPUTS
The ohlc method of source calculations is really a leftover from a time when data was far more limited. Nevertheless it is still the method used in charting and for the most part is sufficient. Often the only important value is 'close' although sometimes 'high' and 'low' can be relevant also. Since we are volume weighting however, it can be useful to incorporate as much information as possible. To that end either 'hlc3' or 'hlcc4' tend to be the best of the defaults (in the case of 24/7 charting like crypto or intraday trading, 'ohlc4' should be avoided as it is effectively the same as a lagging version of 'hlcc4'). There are many other (infinitely many, in fact) possible combinations that can be created, i have included a few here.
The premise is fairly straightforward, by subtracting one value from another, the remaining difference can act as a kind of weight. In a simple case consider 'hl2' as simply the midrange ((high+low)/2), instead of this using 'high+low-open' would give more weight to the value furthest from the open, providing a good estimate of the median. An even better estimate can be achieved by combining that with 'high+low-close' to give the included result 'hl-oc2'. Similarly, 'hlc3' can be considered the basic mean of the three significant values, an included weighted version 'hlc2-o2' combines a sum with subtraction of open to give an estimated mean that may be more accurate. Finally we can apply a similar principle to the close, by subtracting the other values, this one potentially gets more complex so the included 'cc-ohlc4' is really the simplest. The result here is an overbias of the close in relation to the open and the midrange, while in most cases not as useful it can provide an estimate for the next bar assuming that the trend continues.
Of the three i've included, hlc2-o2 is in my opinion the most useful especially in this context, although it is perhaps best considered to be experimental in nature. For that reason, i've kept 'hlcc4' as the default for both MAs.
Additionally included is an 'aux input' which is the standard TV source menu and, where possible, can be set as outputs of other indicators.
THE SYSTEM
This one is fairly obvious and straightforward. It's just a moving average crossover with additional deviation (bollinger) bands. Not a lot to explain here as it should be apparent how it works.
Of the two, MA1 is considered to be the fast and MA2 is considered to be the slow. Both can be set with independent inputs, types and weighting. When MA1 is above, the colour of both is green and when it's below the colour of both is red. An additional gradient based fill is there and can be adjusted along with everything else in the visuals section at the bottom. Default alerts are available for crossover/crossunder conditions along with optional marker plots.
MA2 has the option for deviation bands, these are calculated based upon the MA type used and volume weighted according to the main parameter. In the case of a unweighted SMA being used they will be standard Bollinger bands.
An additional 'source direct' price tracker is included which can be used as the basis for an alert system for price crossings of bands or MAs, while taking advantage of the available weighted inputs. This is displayed as a stepped line on the chart so is also a good way to visualise the differences between input types.
That just about covers it then. The likelihood is that you've used some sort of moving average cross system before and are probably still using one or more. If so, then perhaps the additional functionality here will be of benefit.
Thanks for looking, I welcome any feedack
Counting Stars Overlay [Market Overview Series]Hi fellow tradeurs,
So it's always been my goal to provide one of my best scripts. This is from what I call my "Market Overview" series. It is a scanner for my second best script to date. Market Overview bc of its origins as a scanner of the Kucoin Margin Coins. I realize that there are more coins that there are more margin coins that Kucoin has but I wanted to have a solid 40 coins on each coin "set". If you are unfamiliar with what I mean by 'sets' then you can view my other scanner scripts on this account for futher elaboration but to sum it up....there are 4 sets of coins I have to choose from in the settings. Each set has 40 coins in them (as there is a cap of 40 security calls that can be made per each iteration of the script on the chart). That being said...if you have the capabilities then add this script 4 times to your chart and select a diff set for each copy of the script. This has the scanner in a way that I've yet to present in my others scripts. When the alert for a coin goes off then the coins name will be printed as a label over the main chart. BTW, this was built for the 1 min timeframe and have used it EXTENSIVELY and this is the best TF for how the settings are set. I will also publish another script that will be a visual aid for this one but will rather show all the plots associated with the code that is in this scanner. Know that for the scanner it'll be best to choose a coin that has at least 1 trade/update/printed candle per minute (to be safe use BTC or ETH chart or else some of the signals will be printed if the signal arrives at a point in time where the coin on the screen does not print a candle bc no new trade or update to trades occur in TradingView. For the visual aid script that I will add right after this, there will be 20 different plots that appear. When the AVG of all of these plots is beyond the OverBought line and then the AVG line is falling for 2 bars...THEN the long signal for that coin is generated (and vise versa for short signals) Lastly regarding the visual aid script, THAT ONE will ONLY show the 20 plots that are associated with the coin that the chart is selected for. So that one is not a scanner and is just a stand alone script (again) to show whats going on in the background of this scanner. Now, once you add it however many time you want to see however many sets of coins you want, I recommend merging the scales so that they are all on one scale. I prefer mine being on the left side but all you have to do is select the 3 dots in the scripts settings in the chart window and select the scale location line and it'll open another set of lines at which point you can select "merge to scale Z" (that will be the left scale) and will put all the scales together on the left. I forgot ****If you want to see a whole diff exchange's coins you much make changes to this original script and it is further described how to do so in one of my first publications**** I REALLY hope it becomes of some benefit to you in your trading as it abundantly has in my own. It is after all one of the best of my best. Ohh, I forgot to add alerts to this but will do so immediately following this. To finish, this script DOES NOT REPAINT as far as I have EVER seen (and I have extensively searched for it bc of how good the signals were, I figured I MUST HAVE made a mistake and it did so...but alas...it does not. If you notice something on the contrary do notify me immediately with the coin, exchange, TF, and time of the occurrence and we can go from there. If anyone has any great ideas for the script then please do also let me know and if I find anyone with some abilities that mingle well with my own then lets talk as I'm always looking for good ol chaps to help me out with other scripts bc if you think this is good....well....you must imagine that I've got better that I have not/am not publishing. Aaaaaanywho, goodluck to you all. I wish you the best. ***I've got good info on how to look out for false signals but I want to see what yall come up with first before I give away all my alpha.
AND if anyone asks questions that Ive already touched on in this description or already in the comments sections then maybe someone there would be willing to waste their time answering them bc I've done quite a bit of work here that I am HAPPY to hand over to the general public but if you are not willing to do the work in reading to possibly answer your inquiries that have already been answered then I am not willing to do that work for you again. Peace and love people...peace and love. Im out.
Better Divergence On Any Indicator [DoctaBot]This is an expansion of the Tradingview built in Divergences indicator (bottom) with 2 MAJOR differences.
First, and most importantly, the built in indicator identifies pivots in your chosen oscillator, but then utilizes the corresponding candle's HIGH or LOW to identify potential divergences. I'm not a fan of this method because oscillator values are typically calculated using the candle CLOSE values, so, in my opinion, divergences should be identified using the candle CLOSE value as well, as they are in this script.
Second, the built in divergence indicator only looks back one oscillator pivot for potential divergences. I coded this to look back one additional pivot as well to identify more valid potential divergences. The script will only identify these types of "multiple pivot divergences" if the oscillator pivot in between the two diverging pivots DOES NOT intersect the line being drawn them.
Notes for chart:
#1: This built in Divergence indicator misses this hidden bearish divergence because of the pivot in between (marked with red vertical line). No divergence exists between the most recent pivots, but it does if we compare it to the next one back.
#2: The RSI14 is making a lower high here, the first criteria for a bearish divergence. The built in Divergence indicator then references the candles' HIGHS. Because the most recent HIGH exceeds the previous one, it is considered a higher high and incorrectly identified as a bearish divergence. If we use the candle CLOSE price to identify divergences, this does not qualify.
#3: Here, we see both of the updates in action. Neither of these bearish divergences are identified with the built in Divergence Indicator. The first divergence s missed due to the use of candle HIGHS rather than closes; the original HIGH is greater than the next HIGH, however, comparison of closes shows that it is, in fact, a higher CLOSE. The second divergence is missed because original indicator can only look back one pivot and, consequently, misses the divergence between the next one back.
Please note, you may notice while using this script that some of the older divergences do not show any lines between the oscillator pivots. THIS IS NOT A BUG! In order to draw divergence lines properly for multiple pivots back, I had to use the line.new functions rather than plot functions. These line functions will delete old lines when a certain number have been drawn on the chart so these old ones are automatically erased as time passes.
WAP Maverick - (Dual EMA Smoothed VWAP) - [mutantdog]Short Version:
This here is my take on the popular VWAP indicator with several novel features including:
Dual EMA smoothing.
Arithmetic and Harmonic Mean plots.
Custom Anchor feat. Intraday Session Sizes.
2 Pairs of Bands.
Side Input for Connection to other Indicator.
This can be used 'out of the box' as a replacement VWAP, benefitting from smoother transitions and easy-to-use custom alerts.
By design however, this is intended to be a highly customisable alternative with many adjustable parameters and a pseudo-modular input system to connect with another indicator. Well suited for the tweakers around here and those who like to get a little more creative.
I made this primarily for crypto although it should work for other markets. Default settings are best suited to 15m timeframe - the anchor of 1 week is ideal for crypto which often follows a cyclical nature from Monday through Sunday. In 15m, the default ema length of 21 means that the wap comes to match a standard vwap towards the end of Monday. If using higher chart timeframes, i recommend decreasing the ema length to closely match this principle (suggested: for 1h chart, try length = 8; for 4h chart, length = 2 or 3 should suffice).
Note: the use of harmonic mean calculations will cause problems on any data source incorporating both positive and negative values, it may also return unusable results on extremely low-value charts (eg: low-sat coins in /btc pairs).
Long version:
The development of this project was one driven more by experimentation than a specific end-goal, however i have tried to fine-tune everything into a coherent usable end-product. With that in mind then, this walkthrough will follow something of a development chronology as i dissect the various functions.
DUAL-EMA SMOOTHING
At its core this is based upon / adapted from the standard vwap indicator provided by TradingView although I have modified and changed most of it. The first mod is the dual ema smoothing. Rather than simply applying an ema to the output of the standard vwap function, instead i have incorporated the ema in a manner analogous to the way smas are used within a standard vwma. Sticking for now with the arithmetic mean, the basic vwap calculation is simply sum(source * volume) / sum(volume) across the anchored period. In this case i have simply applied an ema to each of the numerator and denominator values resulting in ema(sum(source * volume)) / ema(sum(volume)) with the ema length independent of the anchor. This results in smoother (albeit slower) transitions than the aforementioned post-vwap method. Furthermore in the case when anchor period is equal to current timeframe, the result is a basic volume-weighted ema.
The example below shows a standard vwap (1week anchor) in blue, a 21-ema applied to the vwap in purple and a dual-21-ema smoothed wap in gold. Notably both ema types come to effectively resemble the standard vwap after around 24 hours into the new anchor session but how they behave in the meantime is very different. The dual-ema transitions quite gradually while the post-vwap ema immediately sets about trying to catch up. Incidentally. a similar and slower variation of the dual-ema can be achieved with dual-rma although i have not included it in this indicator, attempted analogues using sma or wma were far less useful however.
STANDARD DEVIATION AND BANDS
With this updated calculation, a corresponding update to the standard deviation is also required. The vwap has its own anchored volume-weighted st.dev but this cannot be used in combination with the ema smoothing so instead it has been recalculated appropriately. There are two pairs of bands with separate multipliers (stepped to 0.1x) and in both cases high and low bands can be activated or deactivated individually. An example usage for this would be to create different upper and lower bands for profit and stoploss targets. Alerts can be set easily for different crossing conditions, more on this later.
Alongside the bands, i have also added the option to shift ('Deviate') the entire indicator up or down according to a multiple of the corrected st.dev value. This has many potential uses, for example if we want to bias our analysis in one direction it may be useful to move the wap in the opposite. Or if the asset is trading within a narrow range and we are waiting on a breakout, we could shift to the desired level and set alerts accordingly. The 'Deviate' parameter applies to the entire indicator including the bands which will remain centred on the main WAP.
CUSTOM (W)ANCHOR
Ever thought about using a vwap with anchor periods smaller than a day? Here you can do just that. I've removed the Earnings/Dividends/Splits options from the basic vwap and added an 'Intraday' option instead. When selected, a custom anchor length can be created as a multiple of minutes (default steps of 60 mins but can input any value from 0 - 1440). While this may not seem at first like a useful feature for anyone except hi-speed scalpers, this actually offers more interesting potential than it appears.
When set to 0 minutes the current timeframe is always used, turning this into the basic volume-weighted ema mentioned earlier. When using other low time frames the anchor can act as a pre-ema filter creating a stepped effect akin to an adaptive MA. Used in combination with the bands, the result is a kind of volume-weighted adaptive exponential bollinger band; if such a thing does not already exist then this is where you create it. Alternatively, by combining two instances you may find potential interesting crosses between an intraday wap and a standard timeframe wap. Below is an example set to intraday with 480 mins, 2x st.dev bands and ema length 21. Included for comparison in purple is a standard 21 ema.
I'm sure there are many potential uses to be found here, so be creative and please share anything you come up with in the comments.
ARITHMETIC AND HARMONIC MEAN CALCULATIONS
The standard vwap uses the arithmetic mean in its calculation. Indeed, most mean calculations tend to be arithmetic: sma being the most widely used example. When volume weighting is involved though this can lead to a slight bias in favour of upward moves over downward. While the effect of this is minor, over longer anchor periods it can become increasingly significant. The harmonic mean, on the other hand, has the opposite effect which results in a value that is always lower than the arithmetic mean. By viewing both arithmetic and harmonic waps together, the extent to which they diverge from each other can be used as a visual reference of how much price has changed during the anchored period.
Furthermore, the harmonic mean may actually be the more appropriate one to use during downtrends or bearish periods, in principle at least. Consider that a short trade is functionally the same as a long trade on the inverse of the pair (eg: selling BTC/USD is the same as buying USD/BTC). With the harmonic mean being an inverse of the arithmetic then, it makes sense to use it instead. To illustrate this below is a snapshot of LUNA/USDT on the left with its inverse 1/(LUNA/USDT) = USDT/LUNA on the right. On both charts is a wap with identical settings, note the resistance on the left and its corresponding support on the right. It should be easy from this to see that the lower harmonic wap on the left corresponds to the upper arithmetic wap on the right. Thus, it would appear that the harmonic mean should be used in a downtrend. In principle, at least...
In reality though, it is not quite so black and white. Rarely are these values exact in their predictions and the sort of range one should allow for inaccuracies will likely be greater than the difference between these two means. Furthermore, the ema smoothing has already introduced some lag and thus additional inaccuracies. Nevertheless, the symmetry warrants its inclusion.
SIDE INPUT & ALERTS
Finally we move on to the pseudo-modular component here. While TradingView allows some interoperability between indicators, it is limited to just one connection. Any attempt to use multiple source inputs will remove this functionality completely. The workaround here is to instead use custom 'string' input menus for additional sources, preserving this function in the sole 'source' input. In this case, since the wap itself is dependant only price and volume, i have repurposed the full 'source' into the second 'side' input. This allows for a separate indicator to interact with this one that can be used for triggering alerts. You could even use another instance of this one (there is a hidden wap:mid plot intended for this use which is the midpoint between both means). Note that deleting a connected indicator may result in the deletion of those connected to it.
Preset alertconditions are available for crossings of the side input above and below the main wap, alongside several customisable alerts with corresponding visual markers based upon selectable conditions. Alerts for band crossings apply only to those that are active and only crossings of the type specified within the 'crosses' subsection of the indicator settings. The included options make it easy to create buy alerts specific to certain bands with sell alerts specific to other bands. The chart below shows two instances with differing anchor periods, both are connected with buy and sell alerts enabled for visible bands.
Okay... So that just about covers it here, i think. As mentioned earlier this is the product of various experiments while i have been learning my way around PineScript. Some of those experiments have been branched off from this in order to not over-clutter it with functions. The pseudo-modular design and the 'side' input are the result of an attempt to create a connective framework across various projects. Even on its own though, this should offer plenty of tweaking potential for anyone who likes to venture away from the usual standards, all the while still retaining its core purpose as a traders tool.
Thanks for checking this out. I look forward to any feedback below.
+ Ultimate MAWhat is the "Ultimate MA" exactly, you ask? Simple. It actually takes as its influence the Rex Dog Moving Average (which I have included as an MA in some of my other indicators), an invention by xkavalis that is simply an average of different length moving averages.
It's available for free on his account, so take a look at it.
I've recently become drawn to using fibonacci sequence numbers as lookbacks for moving averages, and they work really well (I'm honestly beginning to think the number doesn't matter).
You can see where this is going. The Ultimate MA is an average of several (eight) moving averages of varying lengths (5 - 144) all of fibonacci numbers. Sounds pretty basic, right? That's not actually the case, however.
If you were to take all these numbers, add them up, then average them by eight you'd get ~46. Now, stick a 46 period moving average on the chart and compare it to this one and see what you get. They track price very differently. Still, this all sort of sounds like I'm copying the RDMA, which isn't a sin in itself but is hardly grounds for releasing a new MA into the wild.
The actual initial problem I wanted to tackle was how to take in to account for the entire range of price action in a candle in a moving average. ohlc4 sort of does this, but it's still just one line that is an average of all these prices, and I thought there might be a better way not claiming that what I came upon is, but I like it).
My solution was to plot two moving averages: one an average of price highs, and the other an average of lows, thus creating a high/low price channel. Perhaps this is not a new thing at all. I don't know. This is just an idea I had that I figured I could implement easily enough.
Originally I had just applied this to a 21 period EMA, but then the idea sort of expanded into what you see here. I kept thinking "is 21 the best?" What about faster or slower? Then I thought about the RDMA and decided on this implimentation.
Further, I take the high and low moving averages and divide them by two in order to get a basis. You can turn all this stuff on or off, though I do like the default settings.
After that I wanted to add bands to it to measure volatility. There is an RDMA version that utilizes ATR bands, but I could never find myself happy with these.
I just wanted something... else. I also, actually made my own version of xkavalis' RDMA bands with some of the extra stuff I included here, but obviously didn't feel comfortable releasing it as an indicator as I hadn't changed it enough significantly in my mind to fairly do so. I eventually settled on Bollinger Bands as an appropriate solution to apply to the situation. I really like them. It took some fiddling because I had to create a standard deviation for both the high and low MAs instead of just one, and then figure out the best combination of moving averages and standard deviations to add and subtract to get the bands right.
Then I decided I wanted to add a few different moving averages to choose from instead of just an EMA even though I think it's the "best." I didn't want to make things too complicated, so I just went with the standards--EMA, SMA, WMA, HMA-- + 1, the ALMA (which gives some adjustability with its offset and sigma).
Also, you can run more than one moving average at a time (try running an HMA with a slower one).
Oh yeah, the bands? You can set them, in a dropdown box, to be based on which ever moving average you want.
Furthermore, this is a multi-timeframe indicator, so if you want to run it on a higher time frame than the one you are trading on, it's great for that.
ALSO, I actually have the basis color setup as multi-timeframe. What this means is that if you are looking at an hourly chart, you can set the color to a 4h (or higher) chart if you want, and if the current candle is above or below the previous close of the basis on that higher timeframe you will know simply by looking at the color of it ((while still being on the hourly chart). It's just a different way of utilizing higher timeframe information, but without the indicator itself plotted as higher timeframe.
I'm nearly finished. Almost last thing is a 233 period moving average. It's plotted as an average of the SMA, EMA, and Kijun-sen.
Lastly, there are alerts for price crossing the inner border of the bands, or the 233 MA.
Below is a zoomed in look at a chart.
Much credit and gratitude to xkavalis for coming up with the idea of an average of moving averages.
Financials on Chart█ OVERVIEW
This indicator displays your choice of up to 9 fundamentals on your chart.
█ FEATURES
You can configure the following attributes of the display:
• Its position on your chart.
• Automatic or custom height and width of rows.
• The size and color of text.
• The default background color (you can override it with a custom color for individual values).
• Conversion of values expressed in USD to one of the major currencies. Financials are normally expressed in quote currency.
Conversion to other currencies is only done when the symbol's quote currency is USD.
• Choose if the currency used for the financials is displayed. Note that some financials are calculated values that are not expressed in currency units.
No currency will be displayed for these values.
• Abbreviate large values.
For each value, you may:
• Pick one of the 222 financials available in Pine, or one of five values calculated from the financials (Market Cap, Earnings Yield, P/B Ratio, P/E Ratio and Price-To-Sales Ratio).
• Choose a period (see the "i" icon near the first value's fields in the script's inputs for a list of exceptions).
• Specify the value's precision.
• Change the legend displayed with the value.
• Adjust the text's size.
• Use a custom background.
█ LIMITATIONS
When changing the indicator's inputs, allow a few seconds for the change to be reflected in the display.
If your chart displays a symbol for which the configured financials cannot be fetched, an error will occur.
Not all periods are available for all fundamentals or for all markets. What financial data is available in Pine? will give you an overview of the available periods for each value. The page also contains the formulas used for the five values we calculate from the financials. This page shows the typical reporting frequency for different countries .
█ FINANCIALS
See What is Financial Data? and Why does Financial Data differ from other sources? for more information on the data used by this indicator.
This lists all the financials. Clicking on one will bring up more information about it:
CALCULATED
Market Capitalization
Earnings Yield
Price Book Ratio
Price Earnings Ratio
Price-To-Sales Ratio
INCOME STATEMENTS
After tax other income/expense
Average basic shares outstanding
Other COGS
Cost of goods
Deprecation and amortization
Diluted net income available to common stockholders
Diluted shares outstanding
Dilution adjustment
Discontinued operations
Basic EPS
Diluted EPS
EBIT
EBITDA
Equity in earnings
Gross profit
Taxes
Interest capitalized
Interest expense on debt
Non-controlling/minority interest
Net income before discontinued operations
Net income
Non-operating income, excl. interest expenses
Interest expense, net of interest capitalized
Non-operating interest income
Operating income
Operating expenses (excl. COGS)
Miscellaneous non-operating expense
Other operating expenses, total
Preferred dividends
Pretax equity in earnings
Pretax income
Research & development
Selling/general/admin expenses, other
Selling/general/admin expenses, total
Non-operating income, total
Total operating expenses
Total revenue
Unusual income/expense
BALANCE SHEET
Accounts payable
Accounts receivable - trade, net
Accrued payroll
Accumulated depreciation, total
Additional paid-in capital/Capital surplus
Tangible book value per share
Book value per share
Capitalized lease obligations
Capital and operating lease obligations
Cash & equivalents
Cash and short term investments
Common equity, total
Common stock par/Carrying value
Current portion of LT debt and capital leases
Deferred income, current
Deferred income, non-current
Deferred tax assets
Deferred tax liabilities
Dividends payable
Goodwill, net
Income tax payable
Net intangible assets
Inventories - finished goods
Inventories - progress payments & other
Inventories - raw materials
Inventories - work in progress
Investments in unconsolidated subsidiaries
Long term debt excl. lease liabilities
Long term debt
Long term investments
Note receivable - long term
Other long term assets, total
Minority interest
Notes payable
Operating lease liabilities
Other common equity
Other current assets, total
Other current liabilities
Other intangibles, net
Other investments
Other liabilities, total
Other receivables
Other short term debt
Paid in capital
Gross property/plant/equipment
Net property/plant/equipment
Preferred stock, carrying value
Prepaid expenses
Provision for risks & charge
Retained earnings
Short term debt excl. current portion of LT debt
Short term debt
Short term investments
Shareholders' equity
Total assets
Total current assets
Total current liabilities
Total debt
Total equity
Total inventory
Total liabilities
Total liabilities & shareholders' equities
Total non-current assets
Total non-current liabilities
Total receivables, net
Treasury stock - common
CASHFLOW
Amortization
Capital expenditures - fixed assets
Capital expenditures
Capital expenditures - other assets
Cash from financing activities
Cash from investing activities
Cash from operating activities
Deferred taxes (cash flow)
Depreciation & amortization (cash flow)
Change in accounts payable
Change in accounts receivable
Change in accrued expenses
Change in inventories
Change in other assets/liabilities
Change in taxes payable
Changes in working capital
Common dividends paid
Depreciation/depletion
Free cash flow
Funds from operations
Issuance/retirement of debt, net
Issuance/retirement of long term debt
Issuance/retirement of other debt
Issuance/retirement of short term debt
Issuance/retirement of stock, net
Net income (cash flow)
Non-cash items
Other financing cash flow items, total
Financing activities - other sources
Financing activities - other uses
Other investing cash flow items, total
Investing activities - other sources
Investing activities - other uses
Preferred dividends paid
Purchase/acquisition of business
Purchase of investments
Repurchase of common & preferred stock
Purchase/sale of business, net
Purchase/sale of investments, net
Reduction of long term debt
Sale of common & preferred stock
Sale of fixed assets & businesses
Sale/maturity of investments
Issuance of long term debt
Total cash dividends paid
STATISTICS
Accruals
Altman Z-score
Asset turnover
Beneish M-score
Buyback yield %
Cash conversion cycle
Cash to debt ratio
COGS to revenue ratio
Current ratio
Days sales outstanding
Days inventory
Days payable
Debt to assets ratio
Debt to EBITDA ratio
Debt to equity ratio
Debt to revenue ratio
Dividend payout ratio %
Dividend yield %
Dividends per share - common stock primary issue
EPS estimates
EPS basic one year growth
EPS diluted one year growth
EBITDA margin %
Effective interest rate on debt %
Enterprise value to EBITDA ratio
Enterprise value
Equity to assets ratio
Enterprise value to EBIT ratio
Enterprise value to revenue ratio
Float shares outstanding
Free cash flow margin %
Fulmer H factor
Goodwill to assets ratio
Graham's number
Gross margin %
Gross profit to assets ratio
Interest coverage
Inventory to revenue ratio
Inventory turnover
KZ index
Long term debt to total assets ratio
Net current asset value per share
Net income per employee
Net margin %
Number of employees
Operating earnings yield %
Operating margin %
PEG ratio
Piotroski F-score
Price earnings ratio forward
Price sales ratio forward
Price to free cash flow ratio
Price to tangible book ratio
Quality ratio
Quick ratio
Research & development to revenue ratio
Return on assets %
Return on equity adjusted to book value %
Return on equity %
Return on invested capital %
Return on tangible assets %
Return on tangible equity %
Revenue one year growth
Revenue per employee
Revenue estimates
Shares buyback ratio %
Sloan ratio %
Springate score
Sustainable growth rate
Tangible common equity ratio
Tobin's Q (approximate)
Total common shares outstanding
Zmijewski score
█ NOTES
This script uses the Pine financial() function to fetch the values it displays.
Look first. Then leap.

Technical Ratings on Multi-frames / Assets█ OVERVIEW
This indicator is a modified version of TECHNICAL RATING v1.0 available in the public library to provide a quick overview of consolidated technical ratings performed on 12 assets in 3 timeframes.The purpose of the indicator is to provide a quick overview of the current status of the custom 12 (24) assets and to help focus on the appropriate asset.
█ MODIFICATIONS
- Markers, visualizations and alerts have been deleted
- Due to the limitation on maximum number of security (40), the results of 12 assets evaluated in 3 different time frames can be shown at the same time.
- An additional 12 assets can be configured in the settings so that you do not have to choose each ticker one by one to facilitate a quick change, but can switch between the 12 -12 assets with a single click on "Second sets?".
- The position, colors and parameters of the table can be widely customized in the settings.
- The 12 assets can be arranged in rows 3, 4, 6 and 12 with Table Rows options, which can also be used to create a simple mobile view.
- The default gradient color setting has been changed to red/yellow/green traffic lights
ORIGINAL DESCRIPTION ABOUT TECHNICAL RATING v1.0
█ OVERVIEW
This indicator calculates TradingView's well-known "Strong Buy", "Buy", "Neutral", "Sell" or "Strong Sell" states using the aggregate biases of 26 different technical indicators.
█ WARNING
This version is similar, but not identical, to our recently published "Technical Ratings" built-in, which reproduces our "Technicals" ratings displayed as a gauge in the right panel of charts, or in the "Rating" indicator available in the TradingView Screener. This is a fork and refactoring of the code base used in the "Technical Ratings" built-in. Its calculations will not always match those of the built-in, but it provides options not available in the built-in. Up to you to decide which one you prefer to use.
█ FEATURES
Differences with the built-in version
• The built-in version produces values matching the states displayed in the "Technicals" ratings gauge; this one does not always.
• A strategy version is also available as a built-in; this script is an indicator—not a strategy.
• This indicator will show a slightly different vertical scale, as it does not use a fixed scale like the built-in.
• This version allows control over repainting of the signal when you do not use a higher timeframe. Higher timeframe (HTF) information from this version does not repaint.
• You can adjust the weight of the Oscillators and MAs components of the rating here.
• You can configure markers on signal breaches of configurable levels, or on advances declines of the signal.
The indicator's settings allow you to:
• Choose the timeframe you want calculations to be made on.
• When not using a HTF, you can select a repainting or non-repainting signal.
• When using both MAs and Oscillators groups to calculate the rating, you can vary the weight of each group in the calculation. The default is 50/50.
Because the MAs group uses longer periods for some of its components, its value is not as jumpy as the Oscillators value.
Increasing the weight of the MAs group will thus have a calming effect on the signal.
• Alerts can be created on the indicator using the conditions configured to control the display of markers.
Display
The calculated rating is displayed as columns, but you can change the style in the inputs. The color of the signal can be one of three colors: bull, bear, or neutral. You can choose from a few presets, or check one and edit its color. The color is determined from the rating's value. Between 0.1 and -0.1 it is in the neutral color. Above/below 0.1/-0.1 it will appear in the bull/bear color. The intensity of the bull/bear color is determined by cumulative advances/declines in the rating. It is capped to 5, so there are five intensities for each of the bull/bear colors.
The "Strong Buy", "Buy", "Neutral", "Sell" or "Strong Sell" state of the last calculated value is displayed to the right of the last bar for each of the three groups: All, MAs and Oscillators. The first value always reflects your selection in the "Rating uses" field and is the one used to display the signal. A "Strong Buy" or "Strong Sell" state appears when the signal is above/below the 0.5/-0.5 level. A "Buy" or "Sell" state appears when the signal is above/below the 0.1/-0.1 level. The "Neutral" state appears when the signal is between 0.1 and -0.1 inclusively.
Five levels are always displayed: 0.5 and 0.1 in the bull color, zero in the neutral color, and -0.1 and - 0.5 in the bull color.
█ CALCULATIONS
The indicator calculates the aggregate value of two groups of indicators: moving averages and oscillators.
The "MAs" group is comprised of 15 different components:
• Six Simple Moving Averages of periods 10, 20, 30, 50, 100 and 200
• Six Exponential Moving Averages of the same periods
• A Hull Moving Average of period 9
• A Volume-weighed Moving Average of period 20
• Ichimoku
The "Oscillators" group includes 11 components:
• RSI
• Stochastic
• CCI
• ADX
• Awesome Oscillator
• Momentum
• MACD
• Stochastic RSI
• Wiliams %R
• Bull Bear Power
• Ultimate Oscillator
