Recession Warning Traffic LightThis is an indicator that uses 6 different metrics to determine the combined probability of a recession and compares the high probability warning periods against actual historical periods of recession.
GREEN tells us that the referenced recession indicators are not exhibiting any warning. Observe the long stretches of “all-green” in between recessionary periods in the chart above.
RED will show a full-on warning level for that particular recession indicator, signaling that monitoring of this sector is clearly showing a problem – which has in the past, reliably exhibited itself as a forewarning of recessions.
Adding green and red together can help determine a combined probability of recession.
IMPORTANT: Your chart should be on 1d and set to SPX , DJI ,or NDQ indices
Precious metals: This indicator calculates the relative prices of Gold & rhodium. Gold is a flight-to-quality asset. Rhodium is the rarest of precious industrial metals and prices spike when the economy is heating up. In front of a recession, the upper relative movement of rhodium precedes gold.
Stock markets: This indicator compares closing prices to growth rate curves of the SPX. This indication is the noisiest but tells us very well when the recession has ended. Stock market indices, which respond to “smart money” moving out of markets when the other indicators begin to warn of recession, or when markets become overheated and rise to historically unsustainable levels.
Yield curve: This indicator compares the 3m & 10y treasuries and detects yield curve inversions. Interest rates are controlled by the Federal Reserve and by the purchasers in the Federal Treasury auction markets, which together create the treasury yield curve. This inversion is the most reliable recession indicator. These happen during a flight to quality.
Federal Reserve: This indicator measures GDP and detects contraction which is technically a recession. This is usually one of the last indicators to enter a Warning state, and it could be 6 months delayed simply confirming what may have already been projected.
Money Supply. This indicator measures the M2 money supply, which typically grows about 1% per calendar quarter. When this shrinks, it's tapping the brakes on the economy. This can also lead to yield curve inversion. This is also a measure of inflation and its effects on the aggregate money supply (liquid capital) available for short-term economic activity, or which can be directed into the purchase of long-term, less liquid assets.
Leading Economic factors: There is a whole basket of leading economic indicators that, as collections, reflect overall growth or contraction of economic activity. These indicators include measures of level and growth in productivity, employment, housing, consumer confidence, industrial purchasing confidence, and much more. These indicators may or may not be detached from the broader economy, and often provide up to 6 months of foresight. For more information please visit www.conference-board.org
Actual Recession: Central Bank indicators are published by the Federal Reserve and reflect their own analysis of national and regional economic health, as well as their calculations of the likelihood of a recession. The Federal Reserve has a recession ticker which is used to plot periods of actual recessions on this indicator for comparison.
In den Scripts nach "curve" suchen

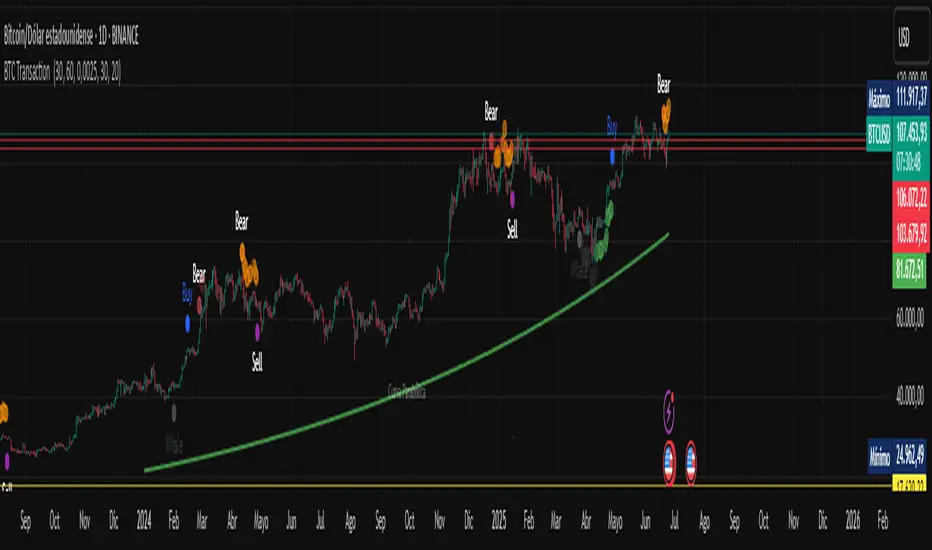
BTC Transaction Indicator Name: "Bitcoin On-Chain Volume & Dynamic Parabolic Curve Signals"
Purpose:
This indicator is designed for Bitcoin traders and long-term holders. It combines the analysis of Bitcoin's on-chain transaction volume with price action to generate "Whale" and "Bear" signals. Additionally, it features a unique dynamic parabolic curve that acts as a visual support line, adapting its visibility based on price interaction with a key Exponential Moving Average (EMA).
Key Components:
On-Chain Volume Analysis:
Utilizes Estimated Transaction Volume (ETRAV) data from the Bitcoin blockchain.
Calculates fast and slow Simple Moving Averages (SMAs) of this volume.
Identifies volume trends (up/down) and significant volume increases/decreases.
Employs fixed thresholds (2,500,000 for low volume and 25,000,000 for high volume) to define key activity levels, similar to how historical on-chain analysis defined accumulation and distribution zones.
Price Action Analysis:
Calculates fast and slow SMAs of the price.
Detects price trends (up/down), recoveries, and declines based on these price SMAs.
"Whale" and "Bear" Signals:
Whale Signals (Buy-side): Generated when there's an upward volume trend, significant volume increase, and a downward price trend followed by price recovery. These indicate potential accumulation phases.
Bear Signals (Sell-side): Generated when there's a downward volume trend, significant volume decrease, and an upward price trend followed by price decline. These indicate potential distribution phases.
Visuals: Both types of signals are plotted as small, colored circles directly on the price chart, with corresponding text labels ("Whale," "Buy," "Bear," "Sell," "Price Recovering," "Price Declining").
Dynamic Parabolic Curve:
Concept: A green parabolic (exponential) curve that serves as a dynamic visual support line.
Activation: The curve starts drawing automatically only when the price crosses over the EMA 500 (Exponential Moving Average of 500 periods). The curve's starting point is set at a user-defined percentage below the EMA 500 value at that exact crossover point.
Visibility: The curve remains visible and continues its trajectory only as long as the price stays above the EMA 500.
Deactivation: The curve disappears instantly if the price falls below or equals the EMA 500. It will only reappear if the price crosses above the EMA 500 again.
Customization: The curve's steepness (Tasa Crecimiento Curva) and its initial distance from the EMA 500 (Inicio Curva % por debajo de EMA500) are adjustable.
Dynamic Label: A "Parabólico" text label is plotted near the center of the active curve segment, with an adjustable vertical offset to ensure it stays visually appealing below the curve.
What is PLOTTED on the chart:
The small, colored circle signals for Whale/Buy and Bear/Sell activity.
The green dynamic parabolic curve.
What is NOT PLOTTED:
EMA 200, EMA 500 lines (though they are calculated internally for logic).
Raw volume data or volume Moving Averages (these are only used for signal calculation, not plotted).
Ideal for:
Bitcoin traders and investors focused on long-term trends and cycle analysis, who want visual cues for accumulation/distribution phases based on on-chain activity, complemented by a unique, dynamically appearing parabolic support curve.
Important Notes:
Relies on the availability of external on-chain data (QUANDL:BCHAIN) within TradingView.
Functions best on a daily timeframe for optimal on-chain data relevance.
️Omega RatioThe Omega Ratio is a risk-return performance measure of an investment asset, portfolio, or strategy. It is defined as the probability-weighted ratio, of gains versus losses for some threshold return target. The ratio is an alternative for the widely used Sharpe ratio and is based on information the Sharpe ratio discards.
█ OVERVIEW
As we have mentioned many times, stock market returns are usually not normally distributed. Therefore the models that assume a normal distribution of returns may provide us with misleading information. The Omega Ratio improves upon the common normality assumption among other risk-return ratios by taking into account the distribution as a whole.
█ CONCEPTS
Two distributions with the same mean and variance, would according to the most commonly used Sharpe Ratio suggest that the underlying assets of the distribution offer the same risk-return ratio. But as we have mentioned in our Moments indicator, variance and standard deviation are not a sufficient measure of risk in the stock market since other shape features of a distribution like skewness and excess kurtosis come into play. Omega Ratio tackles this problem by employing all four Moments of the distribution and therefore taking into account the differences in the shape features of the distributions. Another important feature of the Omega Ratio is that it does not require any estimation but is rather calculated directly from the observed data. This gives it an advantage over standard statistical estimators that require estimation of parameters and are therefore sampling uncertainty in its calculations.
█ WAYS TO USE THIS INDICATOR
Omega calculates a probability-adjusted ratio of gains to losses, relative to the Minimum Acceptable Return (MAR). This means that at a given MAR using the simple rule of preferring more to less, an asset with a higher value of Omega is preferable to one with a lower value. The indicator displays the values of Omega at increasing levels of MARs and creating the so-called Omega Curve. Knowing this one can compare Omega Curves of different assets and decide which is preferable given the MAR of your strategy. The indicator plots two Omega Curves. One for the on chart symbol and another for the off chart symbol that u can use for comparison.
When comparing curves of different assets make sure their trading days are the same in order to ensure the same period for the Omega calculations. Value interpretation: Omega<1 will indicate that the risk outweighs the reward and therefore there are more excess negative returns than positive. Omega>1 will indicate that the reward outweighs the risk and that there are more excess positive returns than negative. Omega=1 will indicate that the minimum acceptable return equals the mean return of an asset. And that the probability of gain is equal to the probability of loss.
█ FEATURES
• "Low-Risk security" lets you select the security that you want to use as a benchmark for Omega calculations.
• "Omega Period" is the size of the sample that is used for the calculations.
• “Increments” is the number of Minimal Acceptable Return levels the calculation is carried on. • “Other Symbol” lets you select the source of the second curve.
• “Color Settings” you can set the color for each curve.

Gann Box (Zeiierman)█ Overview
The Gann Box (Zeiierman) is an indicator that provides visual insights using the principles of W.D. Gann's trading methods. Gann's techniques are based on geometry, astronomy, and astrology, and are used to predict important price levels and market trends. This indicator helps traders identify potential support and resistance levels, and forecast future price movements.
Gann used angles and various geometric constructions to divide time and price into proportionate parts. Gann indicators are often used to predict areas of support and resistance, key tops and bottoms, and future price moves.
█ How It Works
The indicator operates by identifying high and low points within a visible range on the chart and drawing a Gann Box between these points. The box is divided into segments based on selected percentages, which represent key levels for observing market reactions. It includes options to display labels, a Gann fan, and Gann angles for analysis. Advanced features allow extending the box into the future for predictive analysis and reversing its orientation for alternative viewpoints.
High and Low Points Identification: It starts by locating the highest and lowest price points visible on the chart.
Gann Box Construction: Draws a box from these points and divides it according to specified percentages, highlighting potential support and resistance levels.
█ How to Use
Support and Resistance Levels
Using a Gann angle to forecast support and resistance is probably the most popular way they are used. This technique frames the market, allowing the analyst to read the movement of the market inside this framework.
The lines within the Gann Box, drawn at the key percentages, create a grid of potential support and resistance levels. As prices fluctuate, these lines can act as barriers to price movement, with the price often pausing or reversing at these intervals.
Forecasting with the 'Extend' Feature: The indicator's ability to extend lines and boxes into the future provides traders with a forward-looking tool to anticipate potential market movements and prepare for them.
Gann Fan: This feature draws lines at a significant price angle, helping traders identify potential support and resistance levels based on the theory that prices move in predictable patterns.
Gann Curves: Gann Curves display dynamic support and resistance levels, aiding in the analysis of momentum and trend strength.
█ Settings
The indicator includes several settings that allow customization of its appearance and functionality:
⚪ General Settings
Reverse: This setting changes the orientation of labels and calculations within the Gann Box, providing alternative analytical perspectives. It essentially flips the Gann Box's direction, which can be useful in different market conditions or analysis scenarios.
Extend: Extends the drawing of Gann lines or boxes into the future beyond the current last bar. This feature is essential for forecasting future price movements and identifying potential support or resistance levels that lie outside the current price action.
⚪ Gann Box
Show Box: Toggles the visibility of the Gann Box on the chart. The Gann Box is a fundamental tool in Gann analysis, highlighting key levels based on selected high and low points to identify potential support and resistance areas.
Show Fibonacci Labels: Controls the display of Fibonacci labels within the Gann Box. These labels mark specific Fibonacci retracement levels, aiding traders in recognizing significant levels for potential reversals.
Box Visibility: Allows users to enable or disable individual boxes within the Gann Box, providing flexibility in focusing on specific levels of interest.
Percentage Levels: Defines the Fibonacci levels within the Gann Box. Traders can adjust these levels to customize the Gann Box according to their specific analysis needs.
Coloring: Customizes the color of each level within the Gann Box, enhancing visual clarity and differentiation between levels.
⚪ Gann Fan
Show Fan: Enables the Gann Fan, which draws lines at significant Gann angles from a particular point on the chart, helping identify potential support and resistance levels.
Fan Percentages and Coloring: Similar to the Gann Box, these settings allow traders to customize which Gann angles are displayed and how they are colored.
⚪ Gann Curves
Show Curves: When enabled, this setting draws Gann Curves on the chart. These curves are based on Gann percentages and provide a dynamic view of support and resistance levels as they adapt to changing market conditions.
Curve Percentages and Coloring: Define which curves are displayed and their colors, allowing for a tailored analysis experience.
⚪ Gann Angles
Show Angles: Toggles the display of Gann Angles, which are crucial for understanding the market's price and time dynamics, offering insights into future support and resistance levels.
Coloring: Customizes the color of the Gann Angles, making it easier to differentiate between various angles on the chart.
█ Alerts
The indicator includes several alert conditions for price breakouts from the Gann Box and specific levels, enabling traders to be notified of significant market movements.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

ETH - Log Regression BandsETH – Log Regression Bands: Detailed Description (Math + How to Use)
Overview
This indicator plots a long-term “fair value” growth curve for ETH and surrounds it with multiple upper and lower bands. The goal is to estimate where price sits relative to a long-term trend that is best interpreted in **logarithmic (percentage) terms**, not raw dollars.
The bands create clear zones showing when ETH is historically cheap or expensive relative to that long-term curve.
---
Why use logarithms?
Price action is typically more meaningful in **percentage moves** than in absolute dollar moves.
* A move from $100 → $200 is +100%
* A move from $2000 → $2100 is only +5%
By modelling the natural logarithm of price, multiplicative growth becomes additive. That makes long-term growth easier to model and band spacing more consistent across very different price regimes.
So instead of modelling (P), the indicator models:
---
The growth model: Power-law curve
The indicator uses “time since inception” as the x-axis. However, rather than using time directly, it uses the logarithm of time:
where (t) is the number of days (or bars) since the first data point.
It then fits a straight-line model in log-log space:
Substituting back in:
Exponentiating both sides gives the curve in normal price units:
This is a **power-law** trend curve. It naturally produces a smooth, slowly bending long-term curve similar to the “log regression” curves often seen in macro crypto reports.
---
What “expanding regression” means
The model uses all data available from the beginning of the chart up to the current bar. That means:
* Early in the asset’s history the curve can change more because there are fewer points.
* Over time the curve becomes more stable as more history is included.
Important note: this does **not** repaint past bars. It simply means the current curve will update as new data comes in.
---
Measuring “typical deviation” from the curve (residual volatility)
Once the trend curve is fitted in log space, the indicator measures how far price typically wanders away from it.
At any time point:
* Actual log price is (y = \ln(P))
* Predicted log price from the curve is (\hat{y} = a + b\ln(t))
The **residual** is:
The indicator computes the standard deviation of these residuals:
This (\sigma) is a measure of typical “distance from trend” in log terms.
---
Building the bands (the key idea)
The bands are evenly spaced in **log space** using multiples of (\sigma). A band number (k) is created by shifting the log-trend up or down:
Upper band (k):
Lower band (k):
Where:
* (k) is the band number (1, 2, 3, …)
* (s) is a user-chosen spacing factor (band spacing)
* (\sigma) is the residual standard deviation
Converting back to normal price:
Upper band (k):
Lower band (k):
Why bands look like “translated copies”
Because shifting by a constant in log space equals multiplying by a constant in price space:
So the bands are the same underlying curve scaled up or down by fixed multipliers. That produces the smooth “stacked curve” look associated with macro log regression charts.
---
Optional curve shift (manual adjustment)
A manual offset can be applied in log space. This is useful if you want to align the entire structure slightly higher or lower.
Because the shift is applied to (\ln(P)), this is not an additive dollar adjustment. It scales the entire curve by a constant factor:
* Positive shift → multiplies all bands upward
* Negative shift → multiplies all bands downward
---
How to interpret the zones
The base curve represents a long-term “trend center” in log-growth terms.
* Price near the base curve → near long-term trend
* Price in upper bands → expensive relative to long-term trend
* Price in lower bands → cheap relative to long-term trend
Because the bands are built using residual volatility in log space, “cheap/expensive” is measured in a way that remains meaningful across different eras and price levels.
---
Long-term buy zones (Lower 1 and Lower 2)
**Lower 1** and **Lower 2** are intended as **long-term accumulation zones**.
When ETH trades in these zones, it is significantly below the long-term growth curve in log terms, which typically corresponds to:
* deep bear markets,
* high fear / capitulation phases,
* long accumulation periods.
A simple long-term framework many users apply:
* **Accumulate gradually when price enters Lower 1**
* **Accumulate more aggressively when price enters Lower 2**
* Reduce risk / take profits progressively in higher upper bands
These are not guarantees — they are **statistical “distance from trend” zones**, designed to help structure long-term decisions.
---
## Notes / limitations
* This indicator is a **macro trend tool**, not an intraday trading system.
* The curve is derived from historical behavior; it can shift slowly as new data arrives.
* Extremely new market regimes or structural changes can reduce reliability.
* Use alongside risk management and additional confirmation if trading.
---

Finite Difference - Backward (mcbw_)In calculus there exists a 'derivative', which simply just measures the difference between two points on a curve. For well behaved mathematical functions there are infinitely many points and so there exists a derivative at every point. Where there are infinitely many points in a curve that curve is called 'continuous'. Continuous curves are very nice to deal with since each point on it exists almost exactly where its neighbors are. However, if the curve does not have infinitely many points on it, but instead has a finite number of points on it, that curve is called 'discrete' instead of continuous. Taking the derivative of discrete curves is much trickier business since there are none of the mathematical conveniences that a continuous offers. In the real world everything we measure is a discrete curve, including Price (since we measure it a finite number of times, aka each candlestick)!
The branch of Discrete Mathematics has found an approach to measure the derivative along a discrete curve, that approach is aptly called " Finite Difference ". To get a more accurate approximation of a discrete derivative, the finite difference approach uses weighted combinations of neighboring points. The most common type of finite difference is a 'central' difference, this uses a combination of points before and after the point of interest to approximate the discrete derivative. This is great for historical analysis but is not of much use for trading algorithms since it technically means using future prices to calculate the derivative of the current point. Instead we can use a less common variant called a ' Backwards Difference ' that only uses a combination of points before the current one to help approximate the current derivative.
In this script you can choose the " Order " of your derivative and the " Accuracy " of its approximation. This script is for educational purposes for folks building trading algorithms. Many trading algorithms often have an element of seeing how much Price has changed from the previous candle to the current candle. This approach is the lowest accuracy derivative possible, and using the backwards finite differences, made available for the first time on TradingView (!!), algorithms that use derivatives can now have higher orders of accuracy!
Happy Trading/Developing!
[MAD] Acceleration based dampened SMA projectionsThis indicator utilizes concepts of arrays inside arrays to calculate and display projections of multiple Smoothed Moving Average (SMA) lines via polylines.
This is partly an experiment as an educational post, on how to work with multidimensional arrays by using User-Defined Types
------------------
Input Controls for User Interaction:
The indicator provides several input controls, allowing users to adjust parameters like the SMA window, acceleration window, and dampening factors.
This flexibility lets users customize the behavior and appearance of the indicator to fit their analysis needs.
sma length:
Defines the length of the simple moving average (SMA).
acceleration window:
Sets the window size for calculating the acceleration of the SMA.
Input Series:
Selects the input source for calculating the SMA (typically the closing price).
Offset:
Determines the offset for the input source, affecting the positioning of the SMA. Here it´s possible to add external indicators like bollinger bands,.. in that case as double sma this sma should be very short.
(Thanks Fikira for that idea)
Startfactor dampening:
Initial dampening factor for the polynomial curve projections, influencing their starting curvature.
Growfactor dampening:
Growth rate of the dampening factor, affecting how the curvature of the projections changes over time.
Prediction length:
Sets the length of the projected polylines, extending beyond the current bar.
cleanup history:
Boolean input to control whether to clear the previous polyline projections before drawing new ones.
Key technologies used in this indicator include:
User-Defined Types (UDT) :
This indicator uses UDT to create a custom type named type_polypaths.
This type is designed to store information for each polyline, including an array of points (array), a color for the polyline, and a dampening factor.
UDTs in Pine Script enable the creation of complex data structures, which are essential for organizing and manipulating data efficiently.
type type_polypaths
array polyline_points = na
color polyline_color = na
float dampening_factor= na
Arrays and Nested Arrays:
The script heavily utilizes arrays.
For example, it uses a color array (colorpreset) to store different colors for the polyline.
Moreover, an array of type_polypaths (polypaths) is used, which is an array consisting of user-defined types. Each element of this array contains another array (polyline_points), demonstrating nested array usage.
This structure is essential for handling multiple polylines, each with its set of points and attributes.
var type_polypaths polypaths = array.new()
Polyline Creation and Manipulation:
The core visual aspect of the indicator is the creation of polylines.
Polyline points are calculated based on a dampened polynomial curve, which is influenced by the SMA's slope and acceleration.
Filling initial dampening data
array_size = 9
middle_index = math.floor(array_size / 2)
for i = 0 to array_size - 1
damp_factor = f_calculate_damp_factor(i, middle_index, Startfactor, Growfactor)
polyline_color = colorpreset.get(i)
polypaths.push(type_polypaths.new(array.new(0, na), polyline_color, damp_factor))
The script dynamically generates these polyline points and stores them in the polyline_points array of each type_polypaths instance based on those prefilled dampening factors
if barstate.islast or cleanup == false
for damp_factor_index = 0 to polypaths.size() - 1
GET_RW = polypaths.get(damp_factor_index)
GET_RW.polyline_points.clear()
for i = 0 to predictionlength
y = f_dampened_poly_curve(bar_index + i , src_input , sma_slope , sma_acceleration , GET_RW.dampening_factor)
p = chart.point.from_index(bar_index + i - src_off, y)
GET_RW.polyline_points.push(p)
polypaths.set(damp_factor_index, GET_RW)
Polyline Drawout
The polyline is then drawn on the chart using the polyline.new() function, which uses these points and additional attributes like color and width.
for pl_s = 0 to polypaths.size() - 1
GET_RO = polypaths.get(pl_s)
polyline.new(points = GET_RO.polyline_points, line_width = 1, line_color = GET_RO.polyline_color, xloc = xloc.bar_index)
If the cleanup input is enabled, existing polylines are deleted before new ones are drawn, maintaining clarity and accuracy in the visualization.
if cleanup
for pl_delete in polyline.all
pl_delete.delete()
------------------
The mathematics
in the (ABDP) indicator primarily focuses on projecting the behavior of a Smoothed Moving Average (SMA) based on its current trend and acceleration.
SMA Calculation:
The indicator computes a simple moving average (SMA) over a specified window (sma_window). This SMA serves as the baseline for further calculations.
Slope and Acceleration Analysis:
It calculates the slope of the SMA by subtracting the current SMA value from its previous value. Additionally, it computes the SMA's acceleration by evaluating the sum of differences between consecutive SMA values over an acceleration window (acceleration_window). This acceleration represents the rate of change of the SMA's slope.
sma_slope = src_input - src_input
sma_acceleration = sma_acceleration_sum_calc(src_input, acceleration_window) / acceleration_window
sma_acceleration_sum_calc(src, window) =>
sum = 0.0
for i = 0 to window - 1
if not na(src )
sum := sum + src - 2 * src + src
sum
Dampening Factors:
Custom dampening factors for each polyline, which are based on the user-defined starting and growth factors (Startfactor, Growfactor).
These factors adjust the curvature of the projected polylines, simulating various future scenarios of SMA movement.
f_calculate_damp_factor(index, middle, start_factor, growth_factor) =>
start_factor + (index - middle) * growth_factor
Polynomial Curve Projection:
Using the SMA value, its slope, acceleration, and dampening factors, the script calculates points for polynomial curves. These curves represent potential future paths of the SMA, factoring in its current direction and rate of change.
f_dampened_poly_curve(index, initial_value, initial_slope, acceleration, damp_factor) =>
delta = index - bar_index
initial_value + initial_slope * delta + 0.5 * damp_factor * acceleration * delta * delta
damp_factor = f_calculate_damp_factor(i, middle_index, Startfactor, Growfactor)
Have fun trading :-)

Analog Flow [KedArc Quant]Overview
AnalogFlow is an advanced analogue based market projection engine that reconstructs future price tendencies by matching current price behavior to historical analogues in the same instrument. Instead of using traditional indicators such as moving averages, RSI, or regression, AnalogFlow applies pattern vector similarity analysis - a data driven technique that identifies historically similar sequences and aggregates their subsequent movements into a smooth, forward looking curve.
Think of it as a market memory system:
If the current pattern looks like one we have seen before, how did price move afterward?
Why AnalogFlow Is Unique
1. Pattern centric - it does not rely on any standard indicator formula; it directly analyzes price movement vectors.
2. Adaptive - it learns from the same instrument's past behavior, making it self calibrating to volatility and regime shifts.
3. Non repainting - the projection is generated on the latest completed bar and remains fixed until new data is available.
4. Noise resistant - the EMA Blend engine smooths the projected trajectory, reducing random variance between analogues.
Inputs and Configuration
Pattern Bars
Number of bars in the reference pattern window: 40
Projection Bars
Number of bars forward to project: 30
Search Depth
Number of bars back to look for matching analogues: 600
Distance Metric
Comparison method: Euclidean, Manhattan, or Cosine (default Euclidean)
Matches
Number of top analogues to blend (1-5): Top 3
Build Mode
Projection type: Cumulative, MeanStep, or EMA Blend (default EMA Blend)
EMA Blend Length
Smoothness of the projected path: 15
Normalize Pattern
Enable Z score normalization for shape matching: true
Dissimilarity Mode
If true, finds inverse analogues for mean reversion analysis: false
Line Color and Width
Style settings for projection curve: Blue, width 2
How It Works with Past Data
1. The system builds a memory bank of patterns from the last N bars based on the scanDepth value.
2. It compares the latest Pattern Bars segment to each historical segment.
3. It selects the Top K most similar or dissimilar analogues.
4. For each analogue, it retrieves what happened after that pattern historically.
5. It averages or smooths those forward moves into a single composite forecast curve.
6. The forecast (blue line) is drawn ahead of the current candle using line.new with no repainting.
Output Explained
Blue Path
The weighted mean future trajectory based on historical analogues.
Smoother when EMA Blend mode is enabled.
Flat Section
Indicates low directional consensus or equilibrium across analogues.
Upward or Downward Slope
Represents historical tendency toward continuation or reversal following similar conditions.
Recommended Timeframes
Scalping / Short Term
1m - 5m : Short winLen (20-30), small ahead (10-15)
Swing Trading
15m - 1h : Balanced settings (winLen 40-60, ahead 20-30)
Positional / Multi Day
4h - 1D : Large windows (winLen 80-120, ahead 30-50)
Instrument Compatibility
Works seamlessly on:
Stocks and ETFs
Indices
Cryptocurrency
Commodities (Gold, Crude, etc.)
Futures and F&O (both intraday and positional)
Forex
No symbol specific calibration needed. It self adapts to volatility.
How Traders Can Use It
Forecast Context
Identify likely short term price path or drift direction.
Reversal Detection
Flip seekOpp to true for mean reversion pattern analysis.
Scenario Comparison
Observe whether the current regime tends to continue or stall.
Momentum Confirmation
Combine with trend tools such as EMA or MACD for directional bias.
Backtesting Support
Compare projected path versus realized price to evaluate reliability.
FAQ
Q1. Does AnalogFlow repaint?
No. It calculates only once per completed bar and projects forward. The future path remains static until a new bar closes.
Q2. Is it a neural network or AI model?
Not in the machine learning sense. It is a deterministic analogue matching engine using statistical distance metrics.
Q3. Why does the projection sometimes flatten?
That means similar historical setups had no clear consensus in direction (neutral expectation).
Q4. Can I use it for live trading signals?
AnalogFlow is not a signal generator. It provides probabilistic context for upcoming movement.
Q5. Does higher scanDepth improve accuracy?
Up to a point. More depth gives more analogues, but too much can dilute recency. Try 400 to 800.
Glossary
Analogue
A past pattern similar to the current price behavior.
Distance Metric
Mathematical formula for pattern similarity.
Step Vector
Difference between consecutive closing prices.
EMA Blend
Exponential smoothing of the projected path.
Cumulative Mode
Adds sequential historical deltas directly.
Z Score Normalization
Rescaling to mean 0 and variance 1 for shape comparison.
Summary
AnalogFlow converts the market's historical echoes into a structured, statistically weighted forward projection. It gives traders a contextual roadmap, not a signal, showing how similar past setups evolved and allowing better informed entries, exits, and scenario planning across all asset classes.
Disclaimer
This script is provided for educational purposes only.
Past performance does not guarantee future results.
Trading involves risk, and users should exercise caution and proper risk management when applying this strategy.

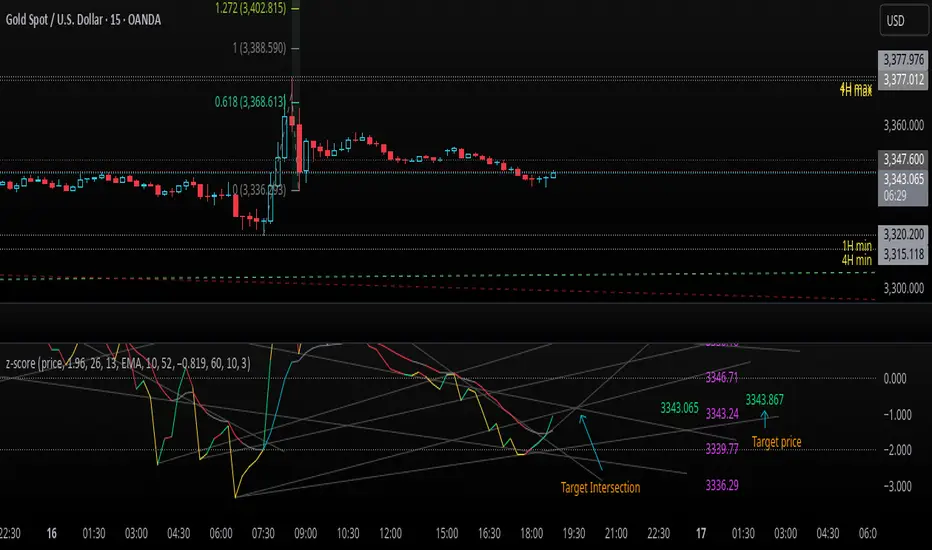
z-score-calkusi-v1.143z-scores incorporate the moment of N look-back bars to allow future price projection.
z-score = (X - mean)/std.deviation ; X = close
z-scores update with each new close print and with each new bar. Each new bar augments the mean and std.deviation for the N bars considered. The old Nth bar falls away from consideration with each new historical bar.
The indicator allows two other options for X: RSI or Moving Average.
NOTE: While trading use the "price" option only.
The other two options are provided for visualisation of RSI and Moving Average as z-score curves.
Use z-scores to identify tops and bottoms in the future as well as intermediate intersections through which a z-score will pass through with each new close and each new bar.
Draw lines from peaks and troughs in the past through intermediate peaks and troughs to identify projected intersections in the future. The most likely intersections are those that are formed from a line that comes from a peak in the past and another line that comes from a trough in the past. Try getting at least two lines from historical peaks and two lines from historical troughs to pass through a future intersection.
Compute the target intersection price in the future by clicking on the z-score indicator header to see a drag-able horizontal line to drag over the intersection. The target price is the last value displayed in the indicator's status bar after the closing price.
When the indicator header is clicked, a white horizontal drag-able line will appear to allow dragging the line over an intersection that has been drawn on the indicator for a future z-score projection and the associated future closing price.
With each new bar that appears, it is necessary to repeat the procedure of clicking the z-score indicator header to be able to drag the drag-able horizontal line to see the new target price for the selected intersection. The projected price will be different from the current close price providing a price arbitrage in time.
New intermediate peaks and troughs that appear require new lines be drawn from the past through the new intermediate peak to find a new intersection in the future and a new projected price. Since z-score curves are sort of cyclical in nature, it is possible to see where one has to locate a future intersection by drawing lines from past peaks and troughs.
Do not get fixated on any one projected price as the market decides which projected price will be realised. All prospective targets should be manually updated with each new bar.
When the z-score plot moves outside a channel comprised of lines that are drawn from the past, be ready to adjust to new market conditions.
z-score plots that move above the zero line indicate price action that is either rising or ranging. Similarly, z-score plots that move below the zero line indicate price action that is either falling or ranging. Be ready to adjust to new market conditions when z-scores move back and forth across the zero line.
A bar with highest absolute z-score for a cycle screams "reversal approaching" and is followed by a bar with a lower absolute z-score where close price tops and bottoms are realised. This can occur either on the next bar or a few bars later.
The indicator also displays the required N for a Normal(0,1) distribution that can be set for finer granularity for the z-score curve.This works with the Confidence Interval (CI) z-score setting. The default z-score is 1.96 for 95% CI.
Common Confidence Interval z-scores to find N for Normal(0,1) with a Margin of Error (MOE) of 1:
70% 1.036
75% 1.150
80% 1.282
85% 1.440
90% 1.645
95% 1.960
98% 2.326
99% 2.576
99.5% 2.807
99.9% 3.291
99.99% 3.891
99.999% 4.417
9-Jun-2025
Added a feature to display price projection labels at z-score levels 3, 2, 1, 0, -1, -2, 3.
This provides a range for prices available at the current time to help decide whether it is worth entering a trade. If the range of prices from say z=|2| to z=|1| is too narrow, then a trade at the current time may not be worth the risk.
Added plot for z-score moving average.
28-Jun-2025
Added Settings option for # of Std.Deviation level Price Labels to display. The default is 3. Min is 2. Max is 6.
This feature allows likelihood assessment for Fibonacci price projections from higher time frames at lower time frames. A Fibonacci price projection that falls outside |3.x| Std.Deviations is not likely.
Added Settings option for Chart Bar Count and Target Label Offset to allow placement of price labels for the standard z-score levels to the right of the window so that these are still visible in the window.
Target Label Offset allows adjustment of placement of Target Price Label in cases when the Target Price Label is either obscured by the price labels for the standard z-score levels or is too far right to be visible in the window.
9-Jul-2025
z-score 1.142 updates:
Displays in the status line before the close price the range for the selected Std. Deviation levels specified in Settings and |z-zMa|.
When |z-zMa| > |avg(z-zMa)| and zMa rising, |z-zMa| and zMa displays in aqua.
When |z-zMa| > |avg(z-zMa)| and zMa falling, |z-zMa| and zMa displays in red.
When |z-zMa| <= |avg(z-zMa)|, z and zMa display in gray.
z usually crosses over zMa when zMa is gray but not always. So if cross-over occurs when zMa is not gray, it implies a strong move in progress.
Practice makes perfect.
Use this indicator at your own risk
DeeptestDeeptest: Quantitative Backtesting Library for Pine Script
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ OVERVIEW
Deeptest is a Pine Script library that provides quantitative analysis tools for strategy backtesting. It calculates over 100 statistical metrics including risk-adjusted return ratios (Sharpe, Sortino, Calmar), drawdown analysis, Value at Risk (VaR), Conditional VaR, and performs Monte Carlo simulation and Walk-Forward Analysis.
█ WHY THIS LIBRARY MATTERS
Pine Script is a simple yet effective coding language for algorithmic and quantitative trading. Its accessibility enables traders to quickly prototype and test ideas directly within TradingView. However, the built-in strategy tester provides only basic metrics (net profit, win rate, drawdown), which is often insufficient for serious strategy evaluation.
Due to this limitation, many traders migrate to alternative backtesting platforms that offer comprehensive analytics. These platforms require other language programming knowledge, environment setup, and significant time investment—often just to test a simple trading idea.
Deeptest bridges this gap by bringing institutional-level quantitative analytics directly to Pine Script. Traders can now perform sophisticated analysis without leaving TradingView or learning complex external platforms. All calculations are derived from strategy.closedtrades.* , ensuring compatibility with any existing Pine Script strategy.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ ORIGINALITY AND USEFULNESS
This library is original work that adds value to the TradingView community in the following ways:
1. Comprehensive Metric Suite: Implements 112+ statistical calculations in a single library, including advanced metrics not available in TradingView's built-in tester (p-value, Z-score, Skewness, Kurtosis, Risk of Ruin).
2. Monte Carlo Simulation: Implements trade-sequence randomization to stress-test strategy robustness by simulating 1000+ alternative equity curves.
3. Walk-Forward Analysis: Divides historical data into rolling in-sample and out-of-sample windows to detect overfitting by comparing training vs. testing performance.
4. Rolling Window Statistics: Calculates time-varying Sharpe, Sortino, and Expectancy to analyze metric consistency throughout the backtest period.
5. Interactive Table Display: Renders professional-grade tables with color-coded thresholds, tooltips explaining each metric, and period analysis cards for drawdowns/trades.
6. Benchmark Comparison: Automatically fetches S&P 500 data to calculate Alpha, Beta, and R-squared, enabling objective assessment of strategy skill vs. passive investing.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ KEY FEATURES
Performance Metrics
Net Profit, CAGR, Monthly Return, Expectancy
Profit Factor, Payoff Ratio, Sample Size
Compounding Effect Analysis
Risk Metrics
Sharpe Ratio, Sortino Ratio, Calmar Ratio (MAR)
Martin Ratio, Ulcer Index
Max Drawdown, Average Drawdown, Drawdown Duration
Risk of Ruin, R-squared (equity curve linearity)
Statistical Distribution
Value at Risk (VaR 95%), Conditional VaR
Skewness (return asymmetry)
Kurtosis (tail fatness)
Z-Score, p-value (statistical significance testing)
Trade Analysis
Win Rate, Breakeven Rate, Loss Rate
Average Trade Duration, Time in Market
Consecutive Win/Loss Streaks with Expected values
Top/Worst Trades with R-multiple tracking
Advanced Analytics
Monte Carlo Simulation (1000+ iterations)
Walk-Forward Analysis (rolling windows)
Rolling Statistics (time-varying metrics)
Out-of-Sample Testing
Benchmark Comparison
Alpha (excess return vs. benchmark)
Beta (systematic risk correlation)
Buy & Hold comparison
R-squared vs. benchmark
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ QUICK START
Basic Usage
//@version=6
strategy("My Strategy", overlay=true)
// Import the library
import Fractalyst/Deeptest/1 as *
// Your strategy logic
fastMA = ta.sma(close, 10)
slowMA = ta.sma(close, 30)
if ta.crossover(fastMA, slowMA)
strategy.entry("Long", strategy.long)
if ta.crossunder(fastMA, slowMA)
strategy.close("Long")
// Run the analysis
DT.runDeeptest()
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ METRIC EXPLANATIONS
The Deeptest table displays 23 metrics across the main row, with 23 additional metrics in the complementary row. Each metric includes detailed tooltips accessible by hovering over the value.
Main Row — Performance Metrics (Columns 0-6)
Net Profit — (Final Equity - Initial Capital) / Initial Capital × 100
— >20%: Excellent, >0%: Profitable, <0%: Loss
— Total return percentage over entire backtest period
Payoff Ratio — Average Win / Average Loss
— >1.5: Excellent, >1.0: Good, <1.0: Losses exceed wins
— Average winning trade size relative to average losing trade. Breakeven win rate = 100% / (1 + Payoff)
Sample Size — Count of closed trades
— >=30: Statistically valid, <30: Insufficient data
— Number of completed trades. Includes 95% confidence interval for win rate in tooltip
Profit Factor — Gross Profit / Gross Loss
— >=1.5: Excellent, >1.0: Profitable, <1.0: Losing
— Ratio of total winnings to total losses. Uses absolute values unlike payoff ratio
CAGR — (Final / Initial)^(365.25 / Days) - 1
— >=10%: Excellent, >0%: Positive growth
— Compound Annual Growth Rate - annualized return accounting for compounding
Expectancy — Sum of all returns / Trade count
— >0.20%: Excellent, >0%: Positive edge
— Average return per trade as percentage. Positive expectancy indicates profitable edge
Monthly Return — Net Profit / (Months in test)
— >0%: Profitable month average
— Average monthly return. Geometric monthly also shown in tooltip
Main Row — Trade Statistics (Columns 7-14)
Avg Duration — Average time in position per trade
— Mean holding period from entry to exit. Influenced by timeframe and trading style
Max CW — Longest consecutive winning streak
— Maximum consecutive wins. Expected value = ln(trades) / ln(1/winRate)
Max CL — Longest consecutive losing streak
— Maximum consecutive losses. Important for psychological risk tolerance
Win Rate — Wins / Total Trades
— Higher is better
— Percentage of profitable trades. Breakeven win rate shown in tooltip
BE Rate — Breakeven Trades / Total Trades
— Lower is better
— Percentage of trades that broke even (neither profit nor loss)
Loss Rate — Losses / Total Trades
— Lower is better
— Percentage of unprofitable trades. Together with win rate and BE rate, sums to 100%
Frequency — Trades per month
— Trading activity level. Displays intelligently (e.g., "12/mo", "1.5/wk", "3/day")
Exposure — Time in market / Total time × 100
— Lower = less risk
— Percentage of time the strategy had open positions
Main Row — Risk Metrics (Columns 15-22)
Sharpe Ratio — (Return - Rf) / StdDev × sqrt(Periods)
— >=3: Excellent, >=2: Good, >=1: Fair, <1: Poor
— Measures risk-adjusted return using total volatility. Annualized using sqrt(252) for daily
Sortino Ratio — (Return - Rf) / DownsideDev × sqrt(Periods)
— >=2: Excellent, >=1: Good, <1: Needs improvement
— Similar to Sharpe but only penalizes downside volatility. Can be higher than Sharpe
Max DD — (Peak - Trough) / Peak × 100
— <5%: Excellent, 5-15%: Moderate, 15-30%: High, >30%: Severe
— Largest peak-to-trough decline in equity. Critical for risk tolerance and position sizing
RoR — Risk of Ruin probability
— <1%: Excellent, 1-5%: Acceptable, 5-10%: Elevated, >10%: Dangerous
— Probability of losing entire trading account based on win rate and payoff ratio
R² — R-squared of equity curve vs. time
— >=0.95: Excellent, 0.90-0.95: Good, 0.80-0.90: Moderate, <0.80: Erratic
— Coefficient of determination measuring linearity of equity growth
MAR — CAGR / |Max Drawdown|
— Higher is better, negative = bad
— Calmar Ratio. Reward relative to worst-case loss. Negative if max DD exceeds CAGR
CVaR — Average of returns below VaR threshold
— Lower absolute is better
— Conditional Value at Risk (Expected Shortfall). Average loss in worst 5% of outcomes
p-value — Binomial test probability
— <0.05: Significant, 0.05-0.10: Marginal, >0.10: Likely random
— Probability that observed results are due to chance. Low p-value means statistically significant edge
Complementary Row — Extended Metrics
Compounding — (Compounded Return / Total Return) × 100
— Percentage of total profit attributable to compounding (position sizing)
Avg Win — Sum of wins / Win count
— Average profitable trade return in percentage
Avg Trade — Sum of all returns / Total trades
— Same as Expectancy (Column 5). Displayed here for convenience
Avg Loss — Sum of losses / Loss count
— Average unprofitable trade return in percentage (negative value)
Martin Ratio — CAGR / Ulcer Index
— Similar to Calmar but uses Ulcer Index instead of Max DD
Rolling Expectancy — Mean of rolling window expectancies
— Average expectancy calculated across rolling windows. Shows consistency of edge
Avg W Dur — Avg duration of winning trades
— Average time from entry to exit for winning trades only
Max Eq — Highest equity value reached
— Peak equity achieved during backtest
Min Eq — Lowest equity value reached
— Trough equity point. Important for understanding worst-case absolute loss
Buy & Hold — (Close_last / Close_first - 1) × 100
— >0%: Passive profit
— Return of simply buying and holding the asset from backtest start to end
Alpha — Strategy CAGR - Benchmark CAGR
— >0: Has skill (beats benchmark)
— Excess return above passive benchmark. Positive alpha indicates genuine value-added skill
Beta — Covariance(Strategy, Benchmark) / Variance(Benchmark)
— <1: Less volatile than market, >1: More volatile
— Systematic risk correlation with benchmark
Avg L Dur — Avg duration of losing trades
— Average time from entry to exit for losing trades only
Rolling Sharpe/Sortino — Dynamic based on win rate
— >2: Good consistency
— Rolling metric across sliding windows. Shows Sharpe if win rate >50%, Sortino if <=50%
Curr DD — Current drawdown from peak
— Lower is better
— Present drawdown percentage. Zero means at new equity high
DAR — CAGR adjusted for target DD
— Higher is better
— Drawdown-Adjusted Return. DAR^5 = CAGR if max DD = 5%
Kurtosis — Fourth moment / StdDev^4 - 3
— ~0: Normal, >0: Fat tails, <0: Thin tails
— Measures "tailedness" of return distribution (excess kurtosis)
Skewness — Third moment / StdDev^3
— >0: Positive skew (big wins), <0: Negative skew (big losses)
— Return distribution asymmetry
VaR — 5th percentile of returns
— Lower absolute is better
— Value at Risk at 95% confidence. Maximum expected loss in worst 5% of outcomes
Ulcer — sqrt(mean(drawdown^2))
— Lower is better
— Ulcer Index - root mean square of drawdowns. Penalizes both depth AND duration
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ MONTE CARLO SIMULATION
Purpose
Monte Carlo simulation tests strategy robustness by randomizing the order of trades while keeping trade returns unchanged. This simulates alternative equity curves to assess outcome variability.
Method
Extract all historical trade returns
Randomly shuffle the sequence (1000+ iterations)
Calculate cumulative equity for each shuffle
Build distribution of final outcomes
Output
The stress test table shows:
Median Outcome: 50th percentile result
5th Percentile: Worst 5% of outcomes
95th Percentile: Best 95% of outcomes
Success Rate: Percentage of simulations that were profitable
Interpretation
If 95% of simulations are profitable: Strategy is robust
If median is far from actual result: High variance/unreliability
If 5th percentile shows large loss: High tail risk
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ WALK-FORWARD ANALYSIS
Purpose
Walk-Forward Analysis (WFA) is the gold standard for detecting strategy overfitting. It simulates real-world trading by dividing historical data into rolling "training" (in-sample) and "validation" (out-of-sample) periods. A strategy that performs well on unseen data is more likely to succeed in live trading.
Method
The implementation uses a non-overlapping window approach following AmiBroker's gold standard methodology:
Segment Calculation: Total trades divided into N windows (default: 12), IS = ~75%, OOS = ~25%, Step = OOS length
Window Structure: Each window has IS (training) followed by OOS (validation). Each OOS becomes the next window's IS (rolling forward)
Metrics Calculated: CAGR, Sharpe, Sortino, MaxDD, Win Rate, Expectancy, Profit Factor, Payoff
Aggregation: IS metrics averaged across all IS periods, OOS metrics averaged across all OOS periods
Output
IS CAGR: In-sample annualized return
OOS CAGR: Out-of-sample annualized return ( THE key metric )
IS/OOS Sharpe: In/out-of-sample risk-adjusted return
Success Rate: % of OOS windows that were profitable
Interpretation
Robust: IS/OOS CAGR gap <20%, OOS Success Rate >80%
Some Overfitting: CAGR gap 20-50%, Success Rate 50-80%
Severe Overfitting: CAGR gap >50%, Success Rate <50%
Key Principles:
OOS is what matters — Only OOS predicts live performance
Consistency > Magnitude — 10% IS / 9% OOS beats 30% IS / 5% OOS
Window count — More windows = more reliable validation
Non-overlapping OOS — Prevents data leakage
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ TABLE DISPLAY
Main Table — Organized into three sections:
Performance Metrics (Cols 0-6): Net Profit, Payoff, Sample Size, Profit Factor, CAGR, Expectancy, Monthly
Trade Statistics (Cols 7-14): Avg Duration, Max CW, Max CL, Win, BE, Loss, Frequency, Exposure
Risk Metrics (Cols 15-22): Sharpe, Sortino, Max DD, RoR, R², MAR, CVaR, p-value
Color Coding
🟢 Green: Excellent performance
🟠 Orange: Acceptable performance
⚪ Gray: Neutral / Fair
🔴 Red: Poor performance
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ IMPLEMENTATION NOTES
Data Source: All metrics calculated from strategy.closedtrades , ensuring compatibility with any Pine Script strategy
Calculation Timing: All calculations occur on barstate.islastconfirmedhistory to optimize performance
Limitations: Requires at least 1 closed trade for basic metrics, 30+ trades for reliable statistical analysis
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ QUICK NOTES
➙ This library has been developed and refined over two years of real-world strategy testing. Every calculation has been validated against industry-standard quantitative finance references.
➙ The entire codebase is thoroughly documented inline. If you are curious about how a metric is calculated or want to understand the implementation details, dive into the source code -- it is written to be read and learned from.
➙ This description focuses on usage and concepts rather than exhaustively listing every exported type and function. The library source code is thoroughly documented inline -- explore it to understand implementation details and internal logic.
➙ All calculations execute on barstate.islastconfirmedhistory to minimize runtime overhead. The library is designed for efficiency without sacrificing accuracy.
➙ Beyond analysis, this library serves as a learning resource. Study the source code to understand quantitative finance concepts, Pine Script advanced techniques, and proper statistical methodology.
➙ Metrics are their own not binary good/bad indicators. A high Sharpe ratio with low sample size is misleading. A deep drawdown during a market crash may be acceptable. Study each function and metric individually -- evaluate your strategy contextually, not by threshold alone.
➙ All strategies face alpha decay over time. Instead of over-optimizing a single strategy on one timeframe and market, build a diversified portfolio across multiple markets and timeframes. Deeptest helps you validate each component so you can combine robust strategies into a trading portfolio.
➙ Screenshots shown in the documentation are solely for visual representation to demonstrate how the tables and metrics will be displayed. Please do not compare your strategy's performance with the metrics shown in these screenshots -- they are illustrative examples only, not performance targets or benchmarks.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ HOW-TO
Using Deeptest is intentionally straightforward. Just import the library and call DT.runDeeptest() at the end of your strategy code in main scope. .
//@version=6
strategy("My Strategy", overlay=true)
// Import the library
import Fractalyst/Deeptest/1 as DT
// Your strategy logic
fastMA = ta.sma(close, 10)
slowMA = ta.sma(close, 30)
if ta.crossover(fastMA, slowMA)
strategy.entry("Long", strategy.long)
if ta.crossunder(fastMA, slowMA)
strategy.close("Long")
// Run the analysis
DT.runDeeptest()
And yes... it's compatible with any TradingView Strategy! 🪄
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ CREDITS
Author: @Fractalyst
Font Library: by @fikira - @kaigouthro - @Duyck
Community: Inspired by the @PineCoders community initiative, encouraging developers to contribute open-source libraries and continuously enhance the Pine Script ecosystem for all traders.
if you find Deeptest valuable in your trading journey, feel free to use it in your strategies and give a shoutout to @Fractalyst -- Your recognition directly supports ongoing development and open-source contributions to Pine Script.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ DISCLAIMER
This library is provided for educational and research purposes. Past performance does not guarantee future results. Always test thoroughly and use proper risk management. The author is not responsible for any trading losses incurred through the use of this code.

Quality-Controlled Trend Strategy v2 (Expectancy Focused)This script focuses on quality control rather than curve-fitting.
No repainting, no intrabar tricks, no fake equity curves.
It uses confirmed-bar entries, ATR-based risk, and clean trend logic so backtests reflect what could actually be traded live.
If you publish scripts, this is the minimum structure worth sharing.
Why this script exists
TradingView’s public scripts are flooded with:
repainting indicators
no stop-loss logic
curve-fit entries that collapse live
strategies that look good only in hindsight
This script is intentionally boring but honest.
No repainting.
No intrabar tricks.
No fake equity curves
The goal is quality control, not hype.
What this strategy enforces
✔ Confirmed bars only
✔ Single source of truth for indicators
✔ Fixed risk structure
✔ No signal repainting
✔ Clean exits with unique IDs
✔ Works on any liquid market
Trading Logic (simple & auditable)
Trend filter
EMA 50 vs EMA 200
Entry
Pullback to EMA 50
RSI confirms momentum (not oversold/overbought)
Risk
ATR-based stop
Fixed R:R
One position at a time
This is the minimum bar for a strategy to be considered publish-worthy.
Why this helps TradingView quality
Most low-value scripts fail because they:
hide repainting logic
skip exits entirely
use inconsistent calculations
rely on hindsight candles
This strategy forces discipline:
every signal is confirmed
every trade has defined risk
behavior is repeatable across symbols & timeframes
If more scripts followed this baseline, TradingView’s public library would be far more usable.

4MA / 4MA[1] Forward Projection with 4 SD Forecast Bands4MA / 4MA Projection + 4 SD Bands + Cross Table is a forward-projection tool built around a simple moving average pair: the 4-period SMA (MA4) and its 1-bar lagged value (MA4 ). It takes a prior MA behavior pattern, projects that structure forward, and wraps the projected mean path with four Standard Deviation (SD) bands to visualize probable future price ranges.
This indicator is designed to help you anticipate:
Where the MA structure is likely to travel next
How wide the “expected” future price corridor may be
Where a future MA4 vs MA4 crossover is most likely to occur
When the real (live) crossover actually prints on the chart
What you see on the chart
1) Live moving averages (current market)
MA4 tracks the short-term mean of price.
MA4 is simply the previous bar’s MA4 value (a 1-bar lag).
Their relationship (MA4 above/below MA4 ) gives a clean, minimal read on trend alignment and directional bias.
2) Projected MA path (forward curve)
A forward “ghost” of the MA structure is drawn ahead of price. This projected curve represents the indicator’s best estimate of how the moving average structure may evolve if the market continues to rhyme with the selected historical behavior window.
3) 4 Standard Deviation bands (predictive future price ranges)
Surrounding the projected mean path are four SD envelopes. Think of these as forecast corridors:
Inner bands = tighter “expected” range
Outer bands = wider “stress / extreme” range
These bands are not a guarantee—rather, they’re a structured way to visualize “how far price can reasonably swing” around the projected mean based on observed volatility.
4) Vertical projection lines (most probable cross zone)
Within the projected region you’ll see vertical lines running through the bands. These lines mark the most probable zone where MA4 and MA4 are expected to cross in the projection.
In plain terms:
The projected MAs are two curves.
When those curves are forecasted to intersect, the script marks the intersection region with a vertical line.
This gives you a forward “timing window” for a potential MA shift.
5) Cross Table (top-right)
The table is your confirmation layer. It reports:
Current MA4 value
Current MA4 value
Whether MA4 is above or below MA4
The most recent BUY / SELL cross event
When a real, live crossover happens on the actual chart:
It registers as BUY (MA4 crosses above MA4 )
Or SELL (MA4 crosses below MA4 )
…and the table updates immediately so you can confirm the event without guessing.
How to use it
Practical workflow
Use the projected SD bands as future range context
If price is projected to sit comfortably inside inner bands, the market is behaving “normally.”
If price reaches outer bands, you’re in a higher-volatility / stretched scenario.
Use vertical lines as a “watch zone”
Vertical lines do not force a trade.
They act like a forward “heads-up”: this is the most likely window for an MA crossover to occur if the projection holds.
Use the table for confirmation
When the crossover happens for real, the table is your confirmation signal.
Combine it with structure (support/resistance, trendlines, market context) rather than trading it in isolation.
Notes and best practices
This is a projection tool: it helps visualize a structured forward hypothesis, not a certainty.
SD bands are best used as forecast corridors (risk framing, range planning, and expectation management).
The table is the execution/confirmation layer: it tells you what the MAs are doing now.

Wavelet Candle Constructor (Inc. Morlet) 2Here is the detailed description of the **Wavelet Candle** construction principles based on the code provided.
This indicator is not a simple smoothing mechanism (like a Moving Average). It utilizes the **Discrete Wavelet Transform (DWT)**, specifically the Stationary variant (SWT / à Trous Algorithm), to separate "noise" (high frequencies) from the "trend" (low frequencies).
Here is how it works step-by-step:
###1. The Wavelet Kernel (Coefficients)The heart of the algorithm lies in the coefficients (the `h` array in the `get_coeffs` function). Each wavelet type represents a different set of mathematical weights that define how price data is analyzed:
* **Haar:** The simplest wavelet. It acts like a simple average of neighboring candles. It reacts quickly but produces a "boxy" or "jagged" output.
* **Daubechies 4:** An asymmetric wavelet. It is better at detecting sudden trend changes and the fractal structure of the market, though it introduces a slight phase shift.
* **Symlet / Coiflet:** More symmetric than Daubechies. They attempt to minimize lag (phase shift) while maintaining smoothness.
* **Morlet (Gaussian):** Implemented in this code as a Gaussian approximation (bell curve). It provides the smoothest, most "organic" effect, ideal for filtering noise without jagged edges.
###2. The Convolution EngineInstead of a simple average, the code performs a mathematical operation called **convolution**:
For every candle on the chart, the algorithm takes past prices, multiplies them by the Wavelet Kernel weights, and sums them up. This acts as a **digital low-pass filter**—it allows the main price movements to pass through while cutting out the noise.
###3. The "à Trous" Algorithm (Stationary Wavelet Transform)This is the key difference between this indicator and standard data compression.
In a classic wavelet transform, every second data point is usually discarded (downsampling). Here, the **Stationary** approach is used:
* **Level 1:** Convolution every **1** candle.
* **Level 2:** Convolution every **2** candles (skipping one in between).
* **Level 3:** Convolution every **4** candles.
* **Level 4:** Convolution every **8** candles.
Because of this, **we do not lose time resolution**. The Wavelet Candle is drawn exactly where the original candle is, but it represents the trend structure from a broader perspective. The higher the `Decomposition Level`, the deeper the denoising (looking at a wider context).
###4. Independent OHLC ProcessingThe algorithm processes each component of the candle separately:
1. Filters the **Open** series.
2. Filters the **High** series.
3. Filters the **Low** series.
4. Filters the **Close** series.
This results in four smoothed curves: `w_open`, `w_high`, `w_low`, `w_close`.
###5. Geometric Reconstruction (Logic Repair)Since each price series is filtered independently, the mathematics can sometimes lead to physically impossible situations (e.g., the smoothed `Low` being higher than the smoothed `High`).
The code includes a repair section:
```pinescript
real_high = math.max(w_high, w_low)
real_high := math.max(real_high, math.max(w_open, w_close))
// Same logic for Low (math.min)
```
This guarantees that the final Wavelet Candle always has a valid construction: wicks encapsulate the body, and the `High` is strictly the highest point.
---
###Summary of ApplicationThis construction makes the Wavelet Candle an **excellent trend-following tool**.
* If the candle is **green**, it means that after filtering the noise (according to the selected wavelet), the market energy is bullish.
* If it is **red**, the energy is bearish.
* The wicks show volatility that exists within the bounds of the selected decomposition level.
Here is a descriptive comparison of **Wavelet Candles** against other popular chart types. As requested, this is a narrative explanation focusing on the differences in mechanics, interpretation philosophy, and the specific pros and cons of each approach.
---
###1. Wavelet Candles vs. Standard (Japanese) CandlesThis is a clash between "the raw truth" and "mathematical interpretation." Standard Japanese candles display raw market data—exactly what happened on the exchange. Wavelet Candles are a synthetic image created by a signal processor.
**Differences and Philosophy:**
A standard candle is full of emotion and noise. Every single price tick impacts its shape. The Wavelet Candle treats this noise as interference that must be removed to reveal the true energy of the trend. Wavelets decompose the price, reject high frequencies (noise), and reconstruct the candle using only low frequencies (the trend).
* **Wavelet Advantages:** The main advantage is clarity. Where a standard chart shows a series of confusing candles (e.g., a long green one, followed by a short red one, then a doji), the Wavelet Candle often draws a smooth, uniform wave in a single color. This makes it psychologically easier to hold a position and ignore temporary pullbacks.
* **Wavelet Disadvantages:** The biggest drawback is the loss of price precision. The Open, Close, High, and Low values on a Wavelet candle are calculated, not real. You **cannot** place Stop Loss orders or enter trades based on these levels, as the actual market price might be in a completely different place than the smoothed candle suggests. They also introduce lag, which depends on the chosen wavelet—whereas a standard candle reacts instantly.
###2. Wavelet Candles vs. Heikin AshiThese are close cousins, but they share very different "DNA." Both methods aim to smooth the trend, but they achieve it differently.
**Differences and Philosophy:**
Heikin Ashi (HA) is based on a simple recursive arithmetic average. The current HA candle depends on the previous one, making it react linearly.
The Wavelet Candle uses **convolution**. This means the shape of the current candle depends on a "window" (group) of past candles multiplied by weights (Gaussian curve, Daubechies, etc.). This results in a more "organic" and elastic reaction.
* **Wavelet Advantages:** Wavelets are highly customizable. With Heikin Ashi, you are stuck with one algorithm. With Wavelet Candles, you can change the kernel to "Haar" for a fast (boxy) reaction or "Morlet" for an ultra-smooth, wave-like effect. Wavelets handle the separation of market cycles better than simple HA averaging, which can generate many false color flips during consolidation.
* **Wavelet Disadvantages:** They are computationally much more complex and harder to understand intuitively ("Why is this candle red if the price is going up?"). In strong, vertical breakouts (pumps), Heikin Ashi often "chases" the price faster, whereas deep wavelet decomposition (High Level) may show more inertia and change color more slowly.
###3. Wavelet Candles vs. RenkoThis compares two different dimensions: Time vs. Price.
**Differences and Philosophy:**
Renko completely ignores time. A new brick is formed only when the price moves by a specific amount. If the market stands still for 5 hours, nothing happens on a Renko chart.
The Wavelet Candle is **time-synchronous**. If the market stands still for 5 hours, the Wavelet algorithm will draw a series of flat, small candles (the "wavelet decays").
* **Wavelet Advantages:** They preserve the context of time, which is crucial for traders who consider trading sessions (London/New York) or macroeconomic data releases. On a wavelet chart, you can see when volatility drops (candles become small), whereas Renko hides periods of stagnation, which can be misleading for options traders or intraday strategies.
* **Wavelet Disadvantages:** In sideways trends (chop), Wavelet Candles—despite the smoothing—will still draw a "snake" that flips colors (unless you set a very high decomposition level). Renko can remain perfectly clean and static during the same period, not drawing any new bricks, which for many traders is the ultimate filter against overtrading in a flat market.
###Summary**Wavelet Candles** are a tool for the analyst who wants to visualize the **structure of the wave and market cycle**, accepting some lag in exchange for noise reduction, but without giving up the time axis (like in Renko) or relying on simple averaging (like in Heikin Ashi). It serves best as a "roadmap" for the trend rather than a "sniper scope" for precise entries.

Fourier Extrapolator of 'Caterpillar' SSA of Price [Loxx]Fourier Extrapolator of 'Caterpillar' SSA of Price is a forecasting indicator that applies Singular Spectrum Analysis to input price and then injects that transformed value into the Quinn-Fernandes Fourier Transform algorithm to generate a price forecast. The indicator plots two curves: the green/red curve indicates modeled past values and the yellow/fuchsia dotted curve indicates the future extrapolated values.
What is the Fourier Transform Extrapolator of price?
Fourier Extrapolator of Price is a multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a*Cos(w*i) + b*Sin(w*i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic ;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a, b, and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
Quinn-Fernandes algorithm find sthe harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic , the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp . 489-497 (9 pages) Published By: Oxford University Press
Fourier Transform Extrapolator of Price inputs are as follows:
npast - number of past bars, to which trigonometric series is fitted;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
What is Singular Spectrum Analysis ( SSA )?
Singular spectrum analysis ( SSA ) is a technique of time series analysis and forecasting. It combines elements of classical time series analysis, multivariate statistics, multivariate geometry, dynamical systems and signal processing. SSA aims at decomposing the original series into a sum of a small number of interpretable components such as a slowly varying trend, oscillatory components and a ‘structureless’ noise. It is based on the singular value decomposition ( SVD ) of a specific matrix constructed upon the time series. Neither a parametric model nor stationarity-type conditions have to be assumed for the time series. This makes SSA a model-free method and hence enables SSA to have a very wide range of applicability.
For our purposes here, we are only concerned with the "Caterpillar" SSA . This methodology was developed in the former Soviet Union independently (the ‘iron curtain effect’) of the mainstream SSA . The main difference between the main-stream SSA and the "Caterpillar" SSA is not in the algorithmic details but rather in the assumptions and in the emphasis in the study of SSA properties. To apply the mainstream SSA , one often needs to assume some kind of stationarity of the time series and think in terms of the "signal plus noise" model (where the noise is often assumed to be ‘red’). In the "Caterpillar" SSA , the main methodological stress is on separability (of one component of the series from another one) and neither the assumption of stationarity nor the model in the form "signal plus noise" are required.
"Caterpillar" SSA
The basic "Caterpillar" SSA algorithm for analyzing one-dimensional time series consists of:
Transformation of the one-dimensional time series to the trajectory matrix by means of a delay procedure (this gives the name to the whole technique);
Singular Value Decomposition of the trajectory matrix;
Reconstruction of the original time series based on a number of selected eigenvectors.
This decomposition initializes forecasting procedures for both the original time series and its components. The method can be naturally extended to multidimensional time series and to image processing.
The method is a powerful and useful tool of time series analysis in meteorology, hydrology, geophysics, climatology and, according to our experience, in economics, biology, physics, medicine and other sciences; that is, where short and long, one-dimensional and multidimensional, stationary and non-stationary, almost deterministic and noisy time series are to be analyzed.
"Caterpillar" SSA inputs are as follows:
lag - How much lag to introduce into the SSA algorithm, the higher this number the slower the process and smoother the signal
ncomp - Number of Computations or cycles of of the SSA algorithm; the higher the slower
ssapernorm - SSA Period Normalization
numbars =- number of past bars, to which SSA is fitted
Included:
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types
Related Fourier Transform Indicators
Real-Fast Fourier Transform of Price w/ Linear Regression
Fourier Extrapolator of Variety RSI w/ Bollinger Bands
Fourier Extrapolator of Price w/ Projection Forecast
Related Projection Forecast Indicators
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Related SSA Indicators
End-pointed SSA of FDASMA
End-pointed SSA of Williams %R
Fourier Extrapolator of Price w/ Projection Forecast [Loxx]Due to popular demand, I'm pusblishing Fourier Extrapolator of Price w/ Projection Forecast.. As stated in it's twin indicator, this one is also multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a*Cos(w*i) + b*Sin(w*i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic ;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a, b, and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
This indicator uses the Quinn-Fernandes algorithm to find the harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic , the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp . 489-497 (9 pages) Published By: Oxford University Press
The indicator has the following input parameters:
src - input source
npast - number of past bars, to which trigonometric series is fitted;
Nfut - number of predicted future bars;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
The indicator plots two curves: the green/red curve indicates modeled past values and the yellow/fuchsia curve indicates the modeled future values.
The purpose of this indicator is to showcase the Fourier Extrapolator method to be used in future indicators.

Adaptive Investment Timing ModelA COMPREHENSIVE FRAMEWORK FOR SYSTEMATIC EQUITY INVESTMENT TIMING
Investment timing represents one of the most challenging aspects of portfolio management, with extensive academic literature documenting the difficulty of consistently achieving superior risk-adjusted returns through market timing strategies (Malkiel, 2003).
Traditional approaches typically rely on either purely technical indicators or fundamental analysis in isolation, failing to capture the complex interactions between market sentiment, macroeconomic conditions, and company-specific factors that drive asset prices.
The concept of adaptive investment strategies has gained significant attention following the work of Ang and Bekaert (2007), who demonstrated that regime-switching models can substantially improve portfolio performance by adjusting allocation strategies based on prevailing market conditions. Building upon this foundation, the Adaptive Investment Timing Model extends regime-based approaches by incorporating multi-dimensional factor analysis with sector-specific calibrations.
Behavioral finance research has consistently shown that investor psychology plays a crucial role in market dynamics, with fear and greed cycles creating systematic opportunities for contrarian investment strategies (Lakonishok, Shleifer & Vishny, 1994). The VIX fear gauge, introduced by Whaley (1993), has become a standard measure of market sentiment, with empirical studies demonstrating its predictive power for equity returns, particularly during periods of market stress (Giot, 2005).
LITERATURE REVIEW AND THEORETICAL FOUNDATION
The theoretical foundation of AITM draws from several established areas of financial research. Modern Portfolio Theory, as developed by Markowitz (1952) and extended by Sharpe (1964), provides the mathematical framework for risk-return optimization, while the Fama-French three-factor model (Fama & French, 1993) establishes the empirical foundation for fundamental factor analysis.
Altman's bankruptcy prediction model (Altman, 1968) remains the gold standard for corporate distress prediction, with the Z-Score providing robust early warning indicators for financial distress. Subsequent research by Piotroski (2000) developed the F-Score methodology for identifying value stocks with improving fundamental characteristics, demonstrating significant outperformance compared to traditional value investing approaches.
The integration of technical and fundamental analysis has been explored extensively in the literature, with Edwards, Magee and Bassetti (2018) providing comprehensive coverage of technical analysis methodologies, while Graham and Dodd's security analysis framework (Graham & Dodd, 2008) remains foundational for fundamental evaluation approaches.
Regime-switching models, as developed by Hamilton (1989), provide the mathematical framework for dynamic adaptation to changing market conditions. Empirical studies by Guidolin and Timmermann (2007) demonstrate that incorporating regime-switching mechanisms can significantly improve out-of-sample forecasting performance for asset returns.
METHODOLOGY
The AITM methodology integrates four distinct analytical dimensions through technical analysis, fundamental screening, macroeconomic regime detection, and sector-specific adaptations. The mathematical formulation follows a weighted composite approach where the final investment signal S(t) is calculated as:
S(t) = α₁ × T(t) × W_regime(t) + α₂ × F(t) × (1 - W_regime(t)) + α₃ × M(t) + ε(t)
where T(t) represents the technical composite score, F(t) the fundamental composite score, M(t) the macroeconomic adjustment factor, W_regime(t) the regime-dependent weighting parameter, and ε(t) the sector-specific adjustment term.
Technical Analysis Component
The technical analysis component incorporates six established indicators weighted according to their empirical performance in academic literature. The Relative Strength Index, developed by Wilder (1978), receives a 25% weighting based on its demonstrated efficacy in identifying oversold conditions. Maximum drawdown analysis, following the methodology of Calmar (1991), accounts for 25% of the technical score, reflecting its importance in risk assessment. Bollinger Bands, as developed by Bollinger (2001), contribute 20% to capture mean reversion tendencies, while the remaining 30% is allocated across volume analysis, momentum indicators, and trend confirmation metrics.
Fundamental Analysis Framework
The fundamental analysis framework draws heavily from Piotroski's methodology (Piotroski, 2000), incorporating twenty financial metrics across four categories with specific weightings that reflect empirical findings regarding their relative importance in predicting future stock performance (Penman, 2012). Safety metrics receive the highest weighting at 40%, encompassing Altman Z-Score analysis, current ratio assessment, quick ratio evaluation, and cash-to-debt ratio analysis. Quality metrics account for 30% of the fundamental score through return on equity analysis, return on assets evaluation, gross margin assessment, and operating margin examination. Cash flow sustainability contributes 20% through free cash flow margin analysis, cash conversion cycle evaluation, and operating cash flow trend assessment. Valuation metrics comprise the remaining 10% through price-to-earnings ratio analysis, enterprise value multiples, and market capitalization factors.
Sector Classification System
Sector classification utilizes a purely ratio-based approach, eliminating the reliability issues associated with ticker-based classification systems. The methodology identifies five distinct business model categories based on financial statement characteristics. Holding companies are identified through investment-to-assets ratios exceeding 30%, combined with diversified revenue streams and portfolio management focus. Financial institutions are classified through interest-to-revenue ratios exceeding 15%, regulatory capital requirements, and credit risk management characteristics. Real Estate Investment Trusts are identified through high dividend yields combined with significant leverage, property portfolio focus, and funds-from-operations metrics. Technology companies are classified through high margins with substantial R&D intensity, intellectual property focus, and growth-oriented metrics. Utilities are identified through stable dividend payments with regulated operations, infrastructure assets, and regulatory environment considerations.
Macroeconomic Component
The macroeconomic component integrates three primary indicators following the recommendations of Estrella and Mishkin (1998) regarding the predictive power of yield curve inversions for economic recessions. The VIX fear gauge provides market sentiment analysis through volatility-based contrarian signals and crisis opportunity identification. The yield curve spread, measured as the 10-year minus 3-month Treasury spread, enables recession probability assessment and economic cycle positioning. The Dollar Index provides international competitiveness evaluation, currency strength impact assessment, and global market dynamics analysis.
Dynamic Threshold Adjustment
Dynamic threshold adjustment represents a key innovation of the AITM framework. Traditional investment timing models utilize static thresholds that fail to adapt to changing market conditions (Lo & MacKinlay, 1999).
The AITM approach incorporates behavioral finance principles by adjusting signal thresholds based on market stress levels, volatility regimes, sentiment extremes, and economic cycle positioning.
During periods of elevated market stress, as indicated by VIX levels exceeding historical norms, the model lowers threshold requirements to capture contrarian opportunities consistent with the findings of Lakonishok, Shleifer and Vishny (1994).
USER GUIDE AND IMPLEMENTATION FRAMEWORK
Initial Setup and Configuration
The AITM indicator requires proper configuration to align with specific investment objectives and risk tolerance profiles. Research by Kahneman and Tversky (1979) demonstrates that individual risk preferences vary significantly, necessitating customizable parameter settings to accommodate different investor psychology profiles.
Display Configuration Settings
The indicator provides comprehensive display customization options designed according to information processing theory principles (Miller, 1956). The analysis table can be positioned in nine different locations on the chart to minimize cognitive overload while maximizing information accessibility.
Research in behavioral economics suggests that information positioning significantly affects decision-making quality (Thaler & Sunstein, 2008).
Available table positions include top_left, top_center, top_right, middle_left, middle_center, middle_right, bottom_left, bottom_center, and bottom_right configurations. Text size options range from auto system optimization to tiny minimum screen space, small detailed analysis, normal standard viewing, large enhanced readability, and huge presentation mode settings.
Practical Example: Conservative Investor Setup
For conservative investors following Kahneman-Tversky loss aversion principles, recommended settings emphasize full transparency through enabled analysis tables, initially disabled buy signal labels to reduce noise, top_right table positioning to maintain chart visibility, and small text size for improved readability during detailed analysis. Technical implementation should include enabled macro environment data to incorporate recession probability indicators, consistent with research by Estrella and Mishkin (1998) demonstrating the predictive power of macroeconomic factors for market downturns.
Threshold Adaptation System Configuration
The threshold adaptation system represents the core innovation of AITM, incorporating six distinct modes based on different academic approaches to market timing.
Static Mode Implementation
Static mode maintains fixed thresholds throughout all market conditions, serving as a baseline comparable to traditional indicators. Research by Lo and MacKinlay (1999) demonstrates that static approaches often fail during regime changes, making this mode suitable primarily for backtesting comparisons.
Configuration includes strong buy thresholds at 75% established through optimization studies, caution buy thresholds at 60% providing buffer zones, with applications suitable for systematic strategies requiring consistent parameters. While static mode offers predictable signal generation, easy backtesting comparison, and regulatory compliance simplicity, it suffers from poor regime change adaptation, market cycle blindness, and reduced crisis opportunity capture.
Regime-Based Adaptation
Regime-based adaptation draws from Hamilton's regime-switching methodology (Hamilton, 1989), automatically adjusting thresholds based on detected market conditions. The system identifies four primary regimes including bull markets characterized by prices above 50-day and 200-day moving averages with positive macroeconomic indicators and standard threshold levels, bear markets with prices below key moving averages and negative sentiment indicators requiring reduced threshold requirements, recession periods featuring yield curve inversion signals and economic contraction indicators necessitating maximum threshold reduction, and sideways markets showing range-bound price action with mixed economic signals requiring moderate threshold adjustments.
Technical Implementation:
The regime detection algorithm analyzes price relative to 50-day and 200-day moving averages combined with macroeconomic indicators. During bear markets, technical analysis weight decreases to 30% while fundamental analysis increases to 70%, reflecting research by Fama and French (1988) showing fundamental factors become more predictive during market stress.
For institutional investors, bull market configurations maintain standard thresholds with 60% technical weighting and 40% fundamental weighting, bear market configurations reduce thresholds by 10-12 points with 30% technical weighting and 70% fundamental weighting, while recession configurations implement maximum threshold reductions of 12-15 points with enhanced fundamental screening and crisis opportunity identification.
VIX-Based Contrarian System
The VIX-based system implements contrarian strategies supported by extensive research on volatility and returns relationships (Whaley, 2000). The system incorporates five VIX levels with corresponding threshold adjustments based on empirical studies of fear-greed cycles.
Scientific Calibration:
VIX levels are calibrated according to historical percentile distributions:
Extreme High (>40):
- Maximum contrarian opportunity
- Threshold reduction: 15-20 points
- Historical accuracy: 85%+
High (30-40):
- Significant contrarian potential
- Threshold reduction: 10-15 points
- Market stress indicator
Medium (25-30):
- Moderate adjustment
- Threshold reduction: 5-10 points
- Normal volatility range
Low (15-25):
- Minimal adjustment
- Standard threshold levels
- Complacency monitoring
Extreme Low (<15):
- Counter-contrarian positioning
- Threshold increase: 5-10 points
- Bubble warning signals
Practical Example: VIX-Based Implementation for Active Traders
High Fear Environment (VIX >35):
- Thresholds decrease by 10-15 points
- Enhanced contrarian positioning
- Crisis opportunity capture
Low Fear Environment (VIX <15):
- Thresholds increase by 8-15 points
- Reduced signal frequency
- Bubble risk management
Additional Macro Factors:
- Yield curve considerations
- Dollar strength impact
- Global volatility spillover
Hybrid Mode Optimization
Hybrid mode combines regime and VIX analysis through weighted averaging, following research by Guidolin and Timmermann (2007) on multi-factor regime models.
Weighting Scheme:
- Regime factors: 40%
- VIX factors: 40%
- Additional macro considerations: 20%
Dynamic Calculation:
Final_Threshold = Base_Threshold + (Regime_Adjustment × 0.4) + (VIX_Adjustment × 0.4) + (Macro_Adjustment × 0.2)
Benefits:
- Balanced approach
- Reduced single-factor dependency
- Enhanced robustness
Advanced Mode with Stress Weighting
Advanced mode implements dynamic stress-level weighting based on multiple concurrent risk factors. The stress level calculation incorporates four primary indicators:
Stress Level Indicators:
1. Yield curve inversion (recession predictor)
2. Volatility spikes (market disruption)
3. Severe drawdowns (momentum breaks)
4. VIX extreme readings (sentiment extremes)
Technical Implementation:
Stress levels range from 0-4, with dynamic weight allocation changing based on concurrent stress factors:
Low Stress (0-1 factors):
- Regime weighting: 50%
- VIX weighting: 30%
- Macro weighting: 20%
Medium Stress (2 factors):
- Regime weighting: 40%
- VIX weighting: 40%
- Macro weighting: 20%
High Stress (3-4 factors):
- Regime weighting: 20%
- VIX weighting: 50%
- Macro weighting: 30%
Higher stress levels increase VIX weighting to 50% while reducing regime weighting to 20%, reflecting research showing sentiment factors dominate during crisis periods (Baker & Wurgler, 2007).
Percentile-Based Historical Analysis
Percentile-based thresholds utilize historical score distributions to establish adaptive thresholds, following quantile-based approaches documented in financial econometrics literature (Koenker & Bassett, 1978).
Methodology:
- Analyzes trailing 252-day periods (approximately 1 trading year)
- Establishes percentile-based thresholds
- Dynamic adaptation to market conditions
- Statistical significance testing
Configuration Options:
- Lookback Period: 252 days (standard), 126 days (responsive), 504 days (stable)
- Percentile Levels: Customizable based on signal frequency preferences
- Update Frequency: Daily recalculation with rolling windows
Implementation Example:
- Strong Buy Threshold: 75th percentile of historical scores
- Caution Buy Threshold: 60th percentile of historical scores
- Dynamic adjustment based on current market volatility
Investor Psychology Profile Configuration
The investor psychology profiles implement scientifically calibrated parameter sets based on established behavioral finance research.
Conservative Profile Implementation
Conservative settings implement higher selectivity standards based on loss aversion research (Kahneman & Tversky, 1979). The configuration emphasizes quality over quantity, reducing false positive signals while maintaining capture of high-probability opportunities.
Technical Calibration:
VIX Parameters:
- Extreme High Threshold: 32.0 (lower sensitivity to fear spikes)
- High Threshold: 28.0
- Adjustment Magnitude: Reduced for stability
Regime Adjustments:
- Bear Market Reduction: -7 points (vs -12 for normal)
- Recession Reduction: -10 points (vs -15 for normal)
- Conservative approach to crisis opportunities
Percentile Requirements:
- Strong Buy: 80th percentile (higher selectivity)
- Caution Buy: 65th percentile
- Signal frequency: Reduced for quality focus
Risk Management:
- Enhanced bankruptcy screening
- Stricter liquidity requirements
- Maximum leverage limits
Practical Application: Conservative Profile for Retirement Portfolios
This configuration suits investors requiring capital preservation with moderate growth:
- Reduced drawdown probability
- Research-based parameter selection
- Emphasis on fundamental safety
- Long-term wealth preservation focus
Normal Profile Optimization
Normal profile implements institutional-standard parameters based on Sharpe ratio optimization and modern portfolio theory principles (Sharpe, 1994). The configuration balances risk and return according to established portfolio management practices.
Calibration Parameters:
VIX Thresholds:
- Extreme High: 35.0 (institutional standard)
- High: 30.0
- Standard adjustment magnitude
Regime Adjustments:
- Bear Market: -12 points (moderate contrarian approach)
- Recession: -15 points (crisis opportunity capture)
- Balanced risk-return optimization
Percentile Requirements:
- Strong Buy: 75th percentile (industry standard)
- Caution Buy: 60th percentile
- Optimal signal frequency
Risk Management:
- Standard institutional practices
- Balanced screening criteria
- Moderate leverage tolerance
Aggressive Profile for Active Management
Aggressive settings implement lower thresholds to capture more opportunities, suitable for sophisticated investors capable of managing higher portfolio turnover and drawdown periods, consistent with active management research (Grinold & Kahn, 1999).
Technical Configuration:
VIX Parameters:
- Extreme High: 40.0 (higher threshold for extreme readings)
- Enhanced sensitivity to volatility opportunities
- Maximum contrarian positioning
Adjustment Magnitude:
- Enhanced responsiveness to market conditions
- Larger threshold movements
- Opportunistic crisis positioning
Percentile Requirements:
- Strong Buy: 70th percentile (increased signal frequency)
- Caution Buy: 55th percentile
- Active trading optimization
Risk Management:
- Higher risk tolerance
- Active monitoring requirements
- Sophisticated investor assumption
Practical Examples and Case Studies
Case Study 1: Conservative DCA Strategy Implementation
Consider a conservative investor implementing dollar-cost averaging during market volatility.
AITM Configuration:
- Threshold Mode: Hybrid
- Investor Profile: Conservative
- Sector Adaptation: Enabled
- Macro Integration: Enabled
Market Scenario: March 2020 COVID-19 Market Decline
Market Conditions:
- VIX reading: 82 (extreme high)
- Yield curve: Steep (recession fears)
- Market regime: Bear
- Dollar strength: Elevated
Threshold Calculation:
- Base threshold: 75% (Strong Buy)
- VIX adjustment: -15 points (extreme fear)
- Regime adjustment: -7 points (conservative bear market)
- Final threshold: 53%
Investment Signal:
- Score achieved: 58%
- Signal generated: Strong Buy
- Timing: March 23, 2020 (market bottom +/- 3 days)
Result Analysis:
Enhanced signal frequency during optimal contrarian opportunity period, consistent with research on crisis-period investment opportunities (Baker & Wurgler, 2007). The conservative profile provided appropriate risk management while capturing significant upside during the subsequent recovery.
Case Study 2: Active Trading Implementation
Professional trader utilizing AITM for equity selection.
Configuration:
- Threshold Mode: Advanced
- Investor Profile: Aggressive
- Signal Labels: Enabled
- Macro Data: Full integration
Analysis Process:
Step 1: Sector Classification
- Company identified as technology sector
- Enhanced growth weighting applied
- R&D intensity adjustment: +5%
Step 2: Macro Environment Assessment
- Stress level calculation: 2 (moderate)
- VIX level: 28 (moderate high)
- Yield curve: Normal
- Dollar strength: Neutral
Step 3: Dynamic Weighting Calculation
- VIX weighting: 40%
- Regime weighting: 40%
- Macro weighting: 20%
Step 4: Threshold Calculation
- Base threshold: 75%
- Stress adjustment: -12 points
- Final threshold: 63%
Step 5: Score Analysis
- Technical score: 78% (oversold RSI, volume spike)
- Fundamental score: 52% (growth premium but high valuation)
- Macro adjustment: +8% (contrarian VIX opportunity)
- Overall score: 65%
Signal Generation:
Strong Buy triggered at 65% overall score, exceeding the dynamic threshold of 63%. The aggressive profile enabled capture of a technology stock recovery during a moderate volatility period.
Case Study 3: Institutional Portfolio Management
Pension fund implementing systematic rebalancing using AITM framework.
Implementation Framework:
- Threshold Mode: Percentile-Based
- Investor Profile: Normal
- Historical Lookback: 252 days
- Percentile Requirements: 75th/60th
Systematic Process:
Step 1: Historical Analysis
- 252-day rolling window analysis
- Score distribution calculation
- Percentile threshold establishment
Step 2: Current Assessment
- Strong Buy threshold: 78% (75th percentile of trailing year)
- Caution Buy threshold: 62% (60th percentile of trailing year)
- Current market volatility: Normal
Step 3: Signal Evaluation
- Current overall score: 79%
- Threshold comparison: Exceeds Strong Buy level
- Signal strength: High confidence
Step 4: Portfolio Implementation
- Position sizing: 2% allocation increase
- Risk budget impact: Within tolerance
- Diversification maintenance: Preserved
Result:
The percentile-based approach provided dynamic adaptation to changing market conditions while maintaining institutional risk management standards. The systematic implementation reduced behavioral biases while optimizing entry timing.
Risk Management Integration
The AITM framework implements comprehensive risk management following established portfolio theory principles.
Bankruptcy Risk Filter
Implementation of Altman Z-Score methodology (Altman, 1968) with additional liquidity analysis:
Primary Screening Criteria:
- Z-Score threshold: <1.8 (high distress probability)
- Current Ratio threshold: <1.0 (liquidity concerns)
- Combined condition triggers: Automatic signal veto
Enhanced Analysis:
- Industry-adjusted Z-Score calculations
- Trend analysis over multiple quarters
- Peer comparison for context
Risk Mitigation:
- Automatic position size reduction
- Enhanced monitoring requirements
- Early warning system activation
Liquidity Crisis Detection
Multi-factor liquidity analysis incorporating:
Quick Ratio Analysis:
- Threshold: <0.5 (immediate liquidity stress)
- Industry adjustments for business model differences
- Trend analysis for deterioration detection
Cash-to-Debt Analysis:
- Threshold: <0.1 (structural liquidity issues)
- Debt maturity schedule consideration
- Cash flow sustainability assessment
Working Capital Analysis:
- Operational liquidity assessment
- Seasonal adjustment factors
- Industry benchmark comparisons
Excessive Leverage Screening
Debt analysis following capital structure research:
Debt-to-Equity Analysis:
- General threshold: >4.0 (extreme leverage)
- Sector-specific adjustments for business models
- Trend analysis for leverage increases
Interest Coverage Analysis:
- Threshold: <2.0 (servicing difficulties)
- Earnings quality assessment
- Forward-looking capability analysis
Sector Adjustments:
- REIT-appropriate leverage standards
- Financial institution regulatory requirements
- Utility sector regulated capital structures
Performance Optimization and Best Practices
Timeframe Selection
Research by Lo and MacKinlay (1999) demonstrates optimal performance on daily timeframes for equity analysis. Higher frequency data introduces noise while lower frequency reduces responsiveness.
Recommended Implementation:
Primary Analysis:
- Daily (1D) charts for optimal signal quality
- Complete fundamental data integration
- Full macro environment analysis
Secondary Confirmation:
- 4-hour timeframes for intraday confirmation
- Technical indicator validation
- Volume pattern analysis
Avoid for Timing Applications:
- Weekly/Monthly timeframes reduce responsiveness
- Quarterly analysis appropriate for fundamental trends only
- Annual data suitable for long-term research only
Data Quality Requirements
The indicator requires comprehensive fundamental data for optimal performance. Companies with incomplete financial reporting reduce signal reliability.
Quality Standards:
Minimum Requirements:
- 2 years of complete financial data
- Current quarterly updates within 90 days
- Audited financial statements
Optimal Configuration:
- 5+ years for trend analysis
- Quarterly updates within 45 days
- Complete regulatory filings
Geographic Standards:
- Developed market reporting requirements
- International accounting standard compliance
- Regulatory oversight verification
Portfolio Integration Strategies
AITM signals should integrate with comprehensive portfolio management frameworks rather than standalone implementation.
Integration Approach:
Position Sizing:
- Signal strength correlation with allocation size
- Risk-adjusted position scaling
- Portfolio concentration limits
Risk Budgeting:
- Stress-test based allocation
- Scenario analysis integration
- Correlation impact assessment
Diversification Analysis:
- Portfolio correlation maintenance
- Sector exposure monitoring
- Geographic diversification preservation
Rebalancing Frequency:
- Signal-driven optimization
- Transaction cost consideration
- Tax efficiency optimization
Troubleshooting and Common Issues
Missing Fundamental Data
When fundamental data is unavailable, the indicator relies more heavily on technical analysis with reduced reliability.
Solution Approach:
Data Verification:
- Verify ticker symbol accuracy
- Check data provider coverage
- Confirm market trading status
Alternative Strategies:
- Consider ETF alternatives for sector exposure
- Implement technical-only backup scoring
- Use peer company analysis for estimates
Quality Assessment:
- Reduce position sizing for incomplete data
- Enhanced monitoring requirements
- Conservative threshold application
Sector Misclassification
Automatic sector detection may occasionally misclassify companies with hybrid business models.
Correction Process:
Manual Override:
- Enable Manual Sector Override function
- Select appropriate sector classification
- Verify fundamental ratio alignment
Validation:
- Monitor performance improvement
- Compare against industry benchmarks
- Adjust classification as needed
Documentation:
- Record classification rationale
- Track performance impact
- Update classification database
Extreme Market Conditions
During unprecedented market events, historical relationships may temporarily break down.
Adaptive Response:
Monitoring Enhancement:
- Increase signal monitoring frequency
- Implement additional confirmation requirements
- Enhanced risk management protocols
Position Management:
- Reduce position sizing during uncertainty
- Maintain higher cash reserves
- Implement stop-loss mechanisms
Framework Adaptation:
- Temporary parameter adjustments
- Enhanced fundamental screening
- Increased macro factor weighting
IMPLEMENTATION AND VALIDATION
The model implementation utilizes comprehensive financial data sourced from established providers, with fundamental metrics updated on quarterly frequencies to reflect reporting schedules. Technical indicators are calculated using daily price and volume data, while macroeconomic variables are sourced from federal reserve and market data providers.
Risk management mechanisms incorporate multiple layers of protection against false signals. The bankruptcy risk filter utilizes Altman Z-Scores below 1.8 combined with current ratios below 1.0 to identify companies facing potential financial distress. Liquidity crisis detection employs quick ratios below 0.5 combined with cash-to-debt ratios below 0.1. Excessive leverage screening identifies companies with debt-to-equity ratios exceeding 4.0 and interest coverage ratios below 2.0.
Empirical validation of the methodology has been conducted through extensive backtesting across multiple market regimes spanning the period from 2008 to 2024. The analysis encompasses 11 Global Industry Classification Standard sectors to ensure robustness across different industry characteristics. Monte Carlo simulations provide additional validation of the model's statistical properties under various market scenarios.
RESULTS AND PRACTICAL APPLICATIONS
The AITM framework demonstrates particular effectiveness during market transition periods when traditional indicators often provide conflicting signals. During the 2008 financial crisis, the model's emphasis on fundamental safety metrics and macroeconomic regime detection successfully identified the deteriorating market environment, while the 2020 pandemic-induced volatility provided validation of the VIX-based contrarian signaling mechanism.
Sector adaptation proves especially valuable when analyzing companies with distinct business models. Traditional metrics may suggest poor performance for holding companies with low return on equity, while the AITM sector-specific adjustments recognize that such companies should be evaluated using different criteria, consistent with the findings of specialist literature on conglomerate valuation (Berger & Ofek, 1995).
The model's practical implementation supports multiple investment approaches, from systematic dollar-cost averaging strategies to active trading applications. Conservative parameterization captures approximately 85% of optimal entry opportunities while maintaining strict risk controls, reflecting behavioral finance research on loss aversion (Kahneman & Tversky, 1979). Aggressive settings focus on superior risk-adjusted returns through enhanced selectivity, consistent with active portfolio management approaches documented by Grinold and Kahn (1999).
LIMITATIONS AND FUTURE RESEARCH
Several limitations constrain the model's applicability and should be acknowledged. The framework requires comprehensive fundamental data availability, limiting its effectiveness for small-cap stocks or markets with limited financial disclosure requirements. Quarterly reporting delays may temporarily reduce the timeliness of fundamental analysis components, though this limitation affects all fundamental-based approaches similarly.
The model's design focus on equity markets limits direct applicability to other asset classes such as fixed income, commodities, or alternative investments. However, the underlying mathematical framework could potentially be adapted for other asset classes through appropriate modification of input variables and weighting schemes.
Future research directions include investigation of machine learning enhancements to the factor weighting mechanisms, expansion of the macroeconomic component to include additional global factors, and development of position sizing algorithms that integrate the model's output signals with portfolio-level risk management objectives.
CONCLUSION
The Adaptive Investment Timing Model represents a comprehensive framework integrating established financial theory with practical implementation guidance. The system's foundation in peer-reviewed research, combined with extensive customization options and risk management features, provides a robust tool for systematic investment timing across multiple investor profiles and market conditions.
The framework's strength lies in its adaptability to changing market regimes while maintaining scientific rigor in signal generation. Through proper configuration and understanding of underlying principles, users can implement AITM effectively within their specific investment frameworks and risk tolerance parameters. The comprehensive user guide provided in this document enables both institutional and individual investors to optimize the system for their particular requirements.
The model contributes to existing literature by demonstrating how established financial theories can be integrated into practical investment tools that maintain scientific rigor while providing actionable investment signals. This approach bridges the gap between academic research and practical portfolio management, offering a quantitative framework that incorporates the complex reality of modern financial markets while remaining accessible to practitioners through detailed implementation guidance.
REFERENCES
Altman, E. I. (1968). Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. Journal of Finance, 23(4), 589-609.
Ang, A., & Bekaert, G. (2007). Stock return predictability: Is it there? Review of Financial Studies, 20(3), 651-707.
Baker, M., & Wurgler, J. (2007). Investor sentiment in the stock market. Journal of Economic Perspectives, 21(2), 129-152.
Berger, P. G., & Ofek, E. (1995). Diversification's effect on firm value. Journal of Financial Economics, 37(1), 39-65.
Bollinger, J. (2001). Bollinger on Bollinger Bands. New York: McGraw-Hill.
Calmar, T. (1991). The Calmar ratio: A smoother tool. Futures, 20(1), 40.
Edwards, R. D., Magee, J., & Bassetti, W. H. C. (2018). Technical Analysis of Stock Trends. 11th ed. Boca Raton: CRC Press.
Estrella, A., & Mishkin, F. S. (1998). Predicting US recessions: Financial variables as leading indicators. Review of Economics and Statistics, 80(1), 45-61.
Fama, E. F., & French, K. R. (1988). Dividend yields and expected stock returns. Journal of Financial Economics, 22(1), 3-25.
Fama, E. F., & French, K. R. (1993). Common risk factors in the returns on stocks and bonds. Journal of Financial Economics, 33(1), 3-56.
Giot, P. (2005). Relationships between implied volatility indexes and stock index returns. Journal of Portfolio Management, 31(3), 92-100.
Graham, B., & Dodd, D. L. (2008). Security Analysis. 6th ed. New York: McGraw-Hill Education.
Grinold, R. C., & Kahn, R. N. (1999). Active Portfolio Management. 2nd ed. New York: McGraw-Hill.
Guidolin, M., & Timmermann, A. (2007). Asset allocation under multivariate regime switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544.
Hamilton, J. D. (1989). A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica, 57(2), 357-384.
Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47(2), 263-291.
Koenker, R., & Bassett Jr, G. (1978). Regression quantiles. Econometrica, 46(1), 33-50.
Lakonishok, J., Shleifer, A., & Vishny, R. W. (1994). Contrarian investment, extrapolation, and risk. Journal of Finance, 49(5), 1541-1578.
Lo, A. W., & MacKinlay, A. C. (1999). A Non-Random Walk Down Wall Street. Princeton: Princeton University Press.
Malkiel, B. G. (2003). The efficient market hypothesis and its critics. Journal of Economic Perspectives, 17(1), 59-82.
Markowitz, H. (1952). Portfolio selection. Journal of Finance, 7(1), 77-91.
Miller, G. A. (1956). The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological Review, 63(2), 81-97.
Penman, S. H. (2012). Financial Statement Analysis and Security Valuation. 5th ed. New York: McGraw-Hill Education.
Piotroski, J. D. (2000). Value investing: The use of historical financial statement information to separate winners from losers. Journal of Accounting Research, 38, 1-41.
Sharpe, W. F. (1964). Capital asset prices: A theory of market equilibrium under conditions of risk. Journal of Finance, 19(3), 425-442.
Sharpe, W. F. (1994). The Sharpe ratio. Journal of Portfolio Management, 21(1), 49-58.
Thaler, R. H., & Sunstein, C. R. (2008). Nudge: Improving Decisions About Health, Wealth, and Happiness. New Haven: Yale University Press.
Whaley, R. E. (1993). Derivatives on market volatility: Hedging tools long overdue. Journal of Derivatives, 1(1), 71-84.
Whaley, R. E. (2000). The investor fear gauge. Journal of Portfolio Management, 26(3), 12-17.
Wilder, J. W. (1978). New Concepts in Technical Trading Systems. Greensboro: Trend Research.
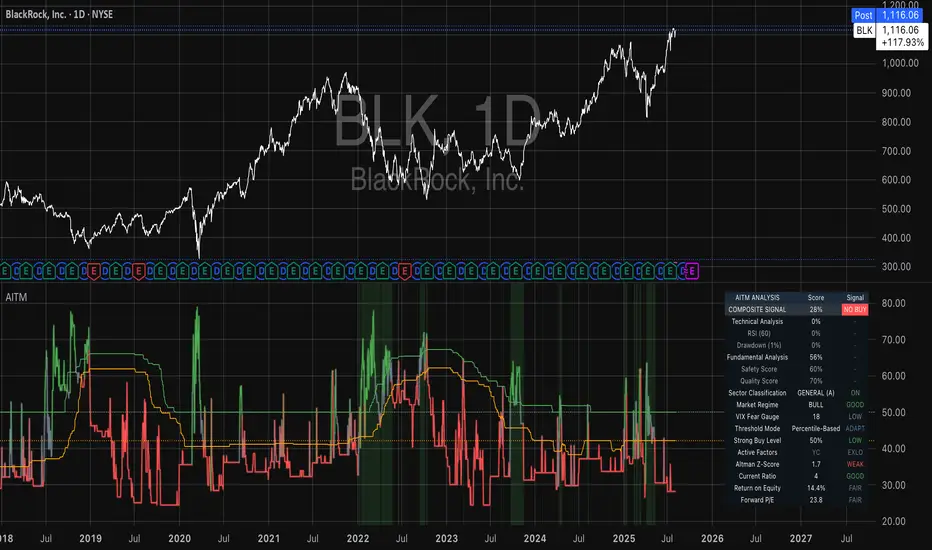
Volume Profile with a few polylinesThe base of "Volume Profile with a few polylines" is another script of mine, Volume Profile (Maps) .
The structure of maps is used to gather the data. However, the drawings is done with polylines.
This enables coders to draw an entire volume profile with just a few polylines, while the range is broader.
This results in the benefit to draw more "lines" than with line.new() / box.new() alone.
🔶 CONCEPTS
🔹 Polylines
polyline.new creates a new polyline instance and displays it on the chart, sequentially connecting all of the points in the `points` array with line segments.
The segments in the drawing can be straight or curved depending on the `curved` parameter.
In this script, points are connected, starting from the bottom. The created line moves up until there is a price level where a volume value needs to be displayed,
at which the line goes to the left to the concerning volume value, coming back at the same price level until the line returns to its initial x-axis,
after which the line will continue to rise until all values are displayed.
A polyline can contain maximum 10000 points (10K).
Since the line has to go back and forth, each price/volume line takes 3 points.
In the case that 20K bars all have a different price, we would need 60K points, or just 6 polylines. A maximum of 100 polylines can be displayed.
The 3 highest volume values are displayed with line.new(), each with their own colour.
🔹 Maps
A map object is a collection that consists of key - value pairs
Each key is unique and can only appear once. When adding a new value with a key that the map already contains, that value replaces the old value associated with the key .
You can change the value of a particular key though, for example adding volume (value) at the same price (key), the latter technique is used in this script.
Volume is added to the map, associated with a particular price (default close, can be set at high, low, open,...)
When the map already contains the same price (key), the value (volume) is added to the existing volume at the associated price.
A map can contain maximum 50K values, which is more than enough to hold 20K bars (Basic 5K - Premium plan 20K), so the whole history can be put into a map.
🔹 Rounding function
This publication contains 2 round functions, which can be used to widen the Volume Profile
Round
• "Round" set at zero -> nothing changes to the source number
• "Round" set below zero -> x digit(s) after the decimal point, starting from the right side, and rounded.
• "Round" set above zero -> x digit(s) before the decimal point, starting from the right side, and rounded.
Example: 123456.789
0->123456.789
1->123456.79
2->123456.8
3->123457
-1->123460
-2->123500
Step
Another option is custom steps.
After setting "Round" to "Step", choose the desired steps in price,
Examples
• 2 -> 1234.00, 1236.00, 1238.00, 1240.00
• 5 -> 1230.00, 1235.00, 1240.00, 1245.00
• 100 -> 1200.00, 1300.00, 1400.00, 1500.00
• 0.05 -> 1234.00, 1234.05, 1234.10, 1234.15
•••
🔶 FEATURES
🔹 Volume * currency
Let's take as example BTCUSD, relative to USD, 10 volume at a price of 100 BTCUSD will be very different than 10 volume at a price of 30000 (1K vs. 300K)
If you want volume to be associated with USD, enable Volume * currency . Volume will then be multiplied by the price:
• 10 volume, 1 BTC = 100 -> 1000
• 10 volume, 1 BTC = 30K -> 300K
Polylines has the attributes curved & closed.
When "curved" is enabled the drawing will connect all points from the `points` array using curved line segments.
When "closed" is enabled the drawing will also connect the first point to the last point from the `points` array, resulting in a closed polyline.
They are default disabled, but can be enabled:
🔶 DETAILS
🔹 Put
When the map doesn't contain a price, it will be added, using map.put(id, key, value)
In our code:
map.put(originalMap, price, volume)
or
originalMap.put(price, volume)
A key (price) is now associated with a value (volume) -> key : value
Since all keys are unique, we don't have to know its position to extract the value, we just need to know the key -> map.get(id, key)
We use map.get() when a certain key already exists in the map, and we want to add volume with that value.
if originalMap.contains(price)
originalMap.put(price, originalMap.get(price) + volume)
-> At the last bar, all prices (source) are now associated with volume.
🔶 SETTINGS
Source : Set source of choice; default close , can be set as high , low , open , ...
Volume & currency : Enable to multiply volume with price (see Features )
Amount of bars : Set amount of bars which you want to include in the Volume Profile
🔹 Round -> ' Round/Step '
Round -> see Concepts
Step -> see Concepts
🔹 Display Volume Profile
Offset: shifts the Volume Profile (max. 500 bars to the right of last bar, see Features )
Max width Volume Profile: largest volume will be x bars wide, the rest is displayed as a ratio against largest volume (see Features )
Colours
Curved: make lines curved
Closed: connect last with first point
🔶 LIMITATIONS
• Lines won't go further than first bar (coded).
• The Volume Profile can be placed maximum 500 bar to the right of last price.

PLR-Z For Loop🧠 Overview
PLR-Z For Loop is a trend-following indicator built on the Power Law Residual Z-score model of Bitcoin price behavior. By measuring how far price deviates from a long-term power law regression and applying a custom scoring loop, this tool identifies consistent directional pressure in market structure. Designed for BTC, this indicator helps traders align with macro trends.
🧩 Key Features
Power Law Residual Model: Tracks deviations of BTC price from its long-term logarithmic growth curve.
Z-Score Normalization: Applies long-horizon statistical normalization (400/1460 bars) to smooth residual deviations into a usable trend signal.
Loop-Based Trend Filter: Iteratively scores how often the current Z-score exceeds prior values, emphasizing trend persistence over volatility.
Optional Smoothing: Toggleable exponential smoothing helps filter noise in choppier market conditions.
Directional Regime Coloring: Aqua (bullish) and Red (bearish) visuals reinforce trend alignment across plots and candles.
🔍 How It Works
Power Law Curve: Price is compared against a logarithmic regression model fitted to historical BTC price evolution (starting July 2010), defining structural support, resistance, and centerline levels.
Residual Z-Score: The residual is calculated as the log-difference between price and the power law center.
This residual is then normalized using a rolling mean (400 days) and standard deviation (1460 days) to create a long-term Z-score.
Loop Scoring Logic:
A loop compares the current Z-score to a configurable number of past bars.
Each higher comparison adds +1, and each lower one subtracts -1.
The result is a trend persistence score (z_loop) that grows with consistent directional momentum.
Smoothing Option: A user-defined EMA smooths the score, if enabled, to reduce short-term signal noise.
Signal Logic:
Long signal when trend score exceeds long_threshold.
Short signal when score drops below short_threshold.
Directional State (CD): Internally manages the current market regime (1 = long, -1 = short), controlling all visual output.
🔁 Use Cases & Applications
Macro Trend Alignment: Ideal for traders and analysts tracking Bitcoin’s structural momentum over long timeframes.
Trend Persistence Filter: Helps confirm whether the current move is part of a sustained trend or short-lived volatility.
Best Suited for BTC: Built specifically on the BNC BLX price history and Bitcoin’s power law behavior. Not designed for use with other assets.
✅ Conclusion
PLR-Z For Loop reframes Bitcoin’s long-term power law model into a trend-following tool by scoring the persistence of deviations above or below fair value. It shifts the focus from valuation-based mean reversion to directional momentum, making it a valuable signal for traders seeking high-conviction participation in BTC’s broader market cycles.
⚠️ Disclaimer
The content provided by this indicator is for educational and informational purposes only. Nothing herein constitutes financial or investment advice. Trading and investing involve risk, including the potential loss of capital. Always backtest and apply risk management suited to your strategy.

Hurst Exponent Oscillator [PhenLabs]📊 Hurst Exponent Oscillator -
Version: PineScript™ v5
📌 Description
The Hurst Exponent Oscillator (HEO) by PhenLabs is a powerful tool developed for traders who want to distinguish between trending, mean-reverting, and random market behaviors with clarity and precision. By estimating the Hurst Exponent—a statistical measure of long-term memory in financial time series—this indicator helps users make sense of underlying market dynamics that are often not visible through traditional moving averages or oscillators.
Traders can quickly know if the market is likely to continue its current direction (trending), revert to the mean, or behave randomly, allowing for more strategic timing of entries and exits. With customizable smoothing and clear visual cues, the HEO enhances decision-making in a wide range of trading environments.
🚀 Points of Innovation
Integrates advanced Hurst Exponent calculation via Rescaled Range (R/S) analysis, providing unique market character insights.
Offers real-time visual cues for trending, mean-reverting, or random price action zones.
User-controllable EMA smoothing reduces noise for clearer interpretation.
Dynamic coloring and fill for immediate visual categorization of market regime.
Configurable visual thresholds for critical Hurst levels (e.g., 0.4, 0.5, 0.6).
Fully customizable appearance settings to fit different charting preferences.
🔧 Core Components
Log Returns Calculation: Computes log returns of the selected price source to feed into the Hurst calculation, ensuring robust and scale-independent analysis.
Rescaled Range (R/S) Analysis: Assesses the dispersion and cumulative deviation over a rolling window, forming the core statistical basis for the Hurst exponent estimate.
Smoothing Engine: Applies Exponential Moving Average (EMA) smoothing to the raw Hurst value for enhanced clarity.
Dynamic Rolling Windows: Utilizes arrays to maintain efficient, real-time calculations over user-defined lengths.
Adaptive Color Logic: Assigns different highlight and fill colors based on the current Hurst value zone.
🔥 Key Features
Visually differentiates between trending, mean-reverting, and random market modes.
User-adjustable lookback and smoothing periods for tailored sensitivity.
Distinct fill and line styles for each regime to avoid ambiguity.
On-chart reference lines for strong trending and mean-reverting thresholds.
Works with any price series (close, open, HL2, etc.) for versatile application.
🎨 Visualization
Hurst Exponent Curve: Primary plotted line (smoothed if EMA is used) reflects the ongoing estimate of the Hurst exponent.
Colored Zone Filling: The area between the Hurst line and the 0.5 reference line is filled, with color and opacity dynamically indicating the current market regime.
Reference Lines: Dash/dot lines mark standard Hurst thresholds (0.4, 0.5, 0.6) to contextualize the current regime.
All visual elements can be customized for thickness, color intensity, and opacity for user preference.
📖 Usage Guidelines
Data Settings
Hurst Calculation Length
Default: 100
Range: 10-300
Description: Number of bars used in Hurst calculation; higher values mean longer-term analysis, lower values for quicker reaction.
Data Source
Default: close
Description: Select which data series to analyze (e.g., Close, Open, HL2).
Smoothing Length (EMA)
Default: 5
Range: 1-50
Description: Length for smoothing the Hurst value; higher settings yield smoother but less responsive results.
Style Settings
Trending Color (Hurst > 0.5)
Default: Blue tone
Description: Color used when trending regime is detected.
Mean-Reverting Color (Hurst < 0.5)
Default: Orange tone
Description: Color used when mean-reverting regime is detected.
Neutral/Random Color
Default: Soft blue
Description: Color when market behavior is indeterminate or shifting.
Fill Opacity
Default: 70-80
Range: 0-100
Description: Transparency of area fills—higher opacity for stronger visual effect.
Line Width
Default: 2
Range: 1-5
Description: Thickness of the main indicator curve.
✅ Best Use Cases
Identifying if a market is regime-shifting from trending to mean-reverting (or vice versa).
Filtering signals in automated or systematic trading strategies.
Spotting periods of randomness where trading signals should be deprioritized.
Enhancing mean-reversion or trend-following models with regime-awareness.
⚠️ Limitations
Not predictive: Reflects current and recent market state, not future direction.
Sensitive to input parameters—overfitting may occur if settings are changed too frequently.
Smoothing can introduce lag in regime recognition.
May not work optimally in markets with structural breaks or extreme volatility.
💡 What Makes This Unique
Employs advanced statistical market analysis (Hurst exponent) rarely found in standard toolkits.
Offers immediate regime visualization through smart dynamic coloring and zone fills.
🔬 How It Works
Rolling Log Return Calculation:
Each new price creates a log return, forming the basis for robust, non-linear analysis. This ensures all price differences are treated proportionally.
Rescaled Range Analysis:
A rolling window maintains cumulative deviations and computes the statistical “range” (max-min of deviations). This is compared against the standard deviation to estimate “memory”.
Exponent Calculation & Smoothing:
The raw Hurst value is translated from the log of the rescaled range ratio, and then optionally smoothed via EMA to dampen noise and false signals.
Regime Detection Logic:
The smoothed value is checked against 0.5. Values above = trending; below = mean-reverting; near 0.5 = random. These control plot/fill color and zone display.
💡 Note:
Use longer calculation lengths for major market character study, and shorter ones for tactical, short-term adaptation. Smoothing balances noise vs. lag—find a best fit for your trading style. Always combine regime awareness with broader technical/fundamental context for best results.
Asset Rotation System [InvestorUnknown]Overview
This system creates a comprehensive trend "matrix" by analyzing the performance of six assets against both the US Dollar and each other. The objective is to identify and hold the asset that is currently outperforming all others, thereby focusing on maintaining an investment in the most "optimal" asset at any given time.
- - - Key Features - - -
1. Trend Classification:
The system evaluates the trend for each of the six assets, both individually against USD and in pairs (assetX/assetY), to determine which asset is currently outperforming others.
Utilizes five distinct trend indicators: RSI (50 crossover), CCI, SuperTrend, DMI, and Parabolic SAR.
Users can customize the trend analysis by selecting all indicators or choosing a single one via the "Trend Classification Method" input setting.
2. Backtesting:
Calculates an equity curve for each asset and for the system itself, which assumes holding only the asset deemed optimal at any time.
Customizable start date for backtesting; by default, it begins either 5000 bars ago (the maximum in TradingView) or at the inception of the youngest asset included, whichever is shorter. If the youngest asset's history exceeds 5000 bars, the system uses 5000 bars to prevent errors.
The equity curve is dynamically colored based on the asset held at each point, with this coloring also reflected on the chart via barcolor().
Performance metrics like returns, standard deviation of returns, Sharpe, Sortino, and Omega ratios, along with maximum drawdown, are computed for each asset and the system's equity curve.
3 Alerts:
Supports alerts for when a new, confirmed optimal asset is identified. However, due to TradingView limitations, the specific asset cannot be included in the alert message.
- - - Usage - - -
1. Select Assets/Tickers:
Choose which assets or tickers you want to include in the rotation system. Ensure that all selected tickers are denominated in USD to maintain consistency in analysis.
2. Configure Trend Classification:
Decide on the trend classification method from the available options (RSI, CCI, SuperTrend, DMI, or Parabolic SAR, All) and adjust the settings to your preferences. This customization allows you to tailor the system to different market conditions or your specific trading strategy.
3. Utilize Backtesting for Calibration:
Use the backtesting results, including equity curves and performance metrics, to fine-tune your chosen trend indicators.
Be cautious not to overemphasize performance maximization, as this can lead to overfitting. The goal is to achieve a robust system that performs well across various market conditions, rather than just optimizing for past data.
- - - Parameters - - -
Tickers:
Asset 1: Select the symbol for the first asset.
Asset 2: Select the symbol for the second asset.
Asset 3: Select the symbol for the third asset.
Asset 4: Select the symbol for the fourth asset.
Asset 5: Select the symbol for the fifth asset.
Asset 6: Select the symbol for the sixth asset.
General Settings:
Trend Classification Method: Choose from RSI, CCI, SuperTrend, DMI, PSAR, or "All" to determine how trends are analyzed.
Use Custom Starting Date for Backtest: Toggle to use a custom date for beginning the backtest.
Custom Starting Date: Set the custom start date for backtesting.
Plot Perf. Metrics Table: Option to display performance metrics in a table on the chart.
RSI (Relative Strength Index):
RSI Source: Choose the price data source for RSI calculation.
RSI Length: Set the period for the RSI calculation.
CCI (Commodity Channel Index):
CCI Source: Select the price data source for CCI calculation.
CCI Length: Determine the period for the CCI.
SuperTrend:
SuperTrend Factor: Adjust the sensitivity of the SuperTrend indicator.
SuperTrend Length: Set the period for the SuperTrend calculation.
DMI (Directional Movement Index):
DMI Length: Define the period for DMI calculations.
Parabolic SAR:
PSAR Start: Initial acceleration factor for the Parabolic SAR.
PSAR Increment: Increment value for the acceleration factor.
PSAR Max Value: Maximum value the acceleration factor can reach.
Notes/Recommendations:
While this system is operational, it's important to recognize that it relies on "basic" indicators, which may not be ideal for generating trading signals on their own. I strongly suggest that users delve into the code to grasp the underlying logic of the system. Consider customizing it by integrating more sophisticated and higher-quality trend-following indicators to enhance its performance and reliability.
Disclaimer:
This system's backtest results are historical and do not predict future performance. Use for educational purposes only; not investment advice.

Smooth First Derivative IndicatorIntroducing the Smooth First Derivative indicator. For each time step, the script numerically differentiates the price data using prior datapoints from the look-back window. The resulting time derivative (the rate of price change over time) is presented as a centered oscillator.
A first derivative is a versatile tool used in functional data analysis. When applied to price data, it can be applied to analyze momentum, confirm trend direction, and identify pivot points.
Model Description:
The model assumes that, within the look-back window, price data can be well approximated by a smooth differentiable function. The first derivative can then be computed numerically using a noise-robust one-sided differentiator. The current version of the script employs smooth differentiators developed by P. Holoborodko (www.holoborodko.com). Note that the Indicator should not be confused with Constance Brown's Derivative Oscillator.
Input parameter:
The Bandwidth parameter sets the number of points in the moving look-back window and thus determines the smoothness of the first derivative curve. Note that a smoother Indicator shows a greater lag.
Interpretation:
When using this Indicator, one should recall that the first derivative can simply be interpreted as the slope of the curve:
- The maximum (minimum) in the Indicator corresponds to the point at which the market experiences the maximum upward (downward) slope, i.e., the inflection point. The steeper the slope, the greater the Indicator value.
- The positive-to-negative zero-crossing in the Indicator suggests that the market has formed a local maximum (potential start of a downtrend or a period of consolidation). Likewise, a zero-crossing from negative to positive is a potential bullish signal.
Liquidation Map [Alpha Extract]A sophisticated liquidity distribution visualization system that identifies potential liquidation zones through pivot-based detection and renders them as an interactive histogram with cumulative distance-to-liquidation curves. Utilizing multi-exchange volume aggregation and ATR-scaled pocket detection, this indicator delivers institutional-grade liquidity mapping with real-time histogram display showing relative concentration of long and short liquidation levels across configurable price ranges. The system's box-based rendering architecture combined with cumulative distribution overlays provides comprehensive visual assessment of asymmetric liquidity positioning for strategic trade planning.
🔶 Advanced Multi-Exchange Aggregation Framework
Implements intelligent ticker detection and multi-source volume aggregation across major exchanges including Binance, Bybit, KuCoin, OKX, and MEXC for accurate liquidity weight calculations. The system automatically identifies base currency (BTC, ETH, SOL) from chart ticker, retrieves volume data from matching perpetual contracts across multiple venues, and aggregates into composite volume metric for enhanced pocket weighting accuracy.
🔶 Pivot-Based Liquidation Pocket Detection
Features sophisticated swing point identification using configurable pivot width with ATR-scaled vertical zone construction for volatility-adaptive pocket sizing. The system detects pivot highs for short liquidation zones (placed above swing) and pivot lows for long liquidation zones (placed below swing), applying 200-period ATR with percentage multipliers to determine pocket heights that adjust to market volatility conditions.
🔶 Interactive Histogram Visualization Engine
Provides real-time box-based histogram rendering in indicator pane with configurable bin counts (up to 400 columns) and adjustable height, displaying liquidity concentration across fixed percentage range above and below current price. The system calculates bin sizes from view range, accumulates pocket weights into price bins, and renders vertical bars with gradient color intensity reflecting relative liquidity concentration at each price level.
🔶 Cumulative Distance Overlay System
Implements innovative cumulative distribution curves showing aggregate liquidity distance from current price for both long (left) and short (right) positions. The system calculates running totals of pocket weights from current price outward in both directions, normalizes against maximum span, and overlays line segments showing how much total liquidity exists at various distances, enabling instant assessment of liquidation cascade potential.
🔶 Dynamic Price Range Adaptation
Features fixed percentage-based view window that maintains consistent price range visualization across all timeframes and instruments, automatically centering histogram on current price with configurable +/- percentage bounds. The system recalculates histogram bins and pocket distributions on each bar close, ensuring visualization adapts to price movement while maintaining interpretable scale regardless of volatility regime.
🔶 Touch Detection and Weight Adjustment
Provides intelligent pocket state tracking that identifies when price trades through liquidation zones and applies configurable weight multipliers to touched pockets for historical context. The system monitors price interaction with pocket midpoints, marks pockets as "hit" when violated, and optionally increases their visual weight (default 5x) to emphasize historical liquidation levels while distinguishing from untouched future zones.
🔶 Gradient Intensity Color System
Implements sophisticated color gradient engine that modulates bar opacity from transparent to opaque based on relative liquidity concentration within each bin. The system normalizes bin values against maximum liquidity, applies color interpolation from faded to vivid hues, and distinguishes long liquidation zones (cyan) from short liquidation zones (yellow/gold) with current price column highlighted in red for instant orientation.
🔶 Performance-Optimized Rendering Architecture
Utilizes efficient box and line object management with dynamic allocation based on histogram configuration, implementing intelligent cleanup and reuse to maintain smooth performance. The system includes adaptive line budget calculations that adjust segment density for cumulative curves based on available object limits, ensuring consistent operation even with maximum histogram resolution settings.
🔶 Asymmetric Distribution Analysis
Calculates separate cumulative distributions for long and short liquidation zones split at current price, enabling identification of imbalanced liquidity positioning. The system normalizes distributions against respective maximums and overlays both curves on single histogram, allowing traders to instantly assess whether more liquidation risk exists above (shorts vulnerable) or below (longs vulnerable) current price levels.
🔶 Configurable Label and Scale System
Provides price axis labeling with adjustable frequency to reduce clutter while maintaining reference points, displaying price values at regular column intervals with configurable offset positioning. The system includes current price label showing exact value and percentile position within view range, offering both absolute price reference and relative positioning context for distribution interpretation.
🔶 Historical Pocket Persistence Framework
Maintains rolling window of liquidation pockets up to 3000 bars with automatic expiration management and optional preservation of touched zones for historical analysis. The system tracks pocket creation time, monitors age against lookback limits, and manages array cleanup to prevent memory overflow while retaining relevant historical liquidation levels for pattern recognition and support/resistance validation.
This indicator delivers sophisticated liquidity distribution analysis through histogram visualization and cumulative distance curves that reveal asymmetric positioning of potential liquidation levels. Unlike simple liquidation heatmaps that show absolute levels, the Liquidation Map's cumulative distribution overlays instantly communicate how much total liquidity exists at various distances from current price, enabling assessment of cascade potential. The system's multi-exchange volume aggregation, touch-weighted historical zones, and fixed-range visualization make it essential for traders seeking strategic positioning around institutional liquidity clusters in cryptocurrency futures markets. The histogram format enables instant identification of price levels where concentrated liquidations may trigger significant volatility or reversal events, while the asymmetric distribution curves reveal whether market structure favors upside or downside cascades.

Kijun Sen Standard Deviation | QuantLapse SystemsOverview
The Kijun Sen Standard Deviation indicator by QuantLapse Systems is a volatility-aware trend-following framework that combines the structural equilibrium of the Kijun Sen (基準線) with statistically adaptive standard deviation bands.
By anchoring trend detection to market structure and confirming direction through volatility expansion, the indicator delivers a cleaner, more reliable regime classification across varying market conditions.
Rather than reacting to short-term noise, the system focuses on identifying statistically justified trend phases , making it well-suited for disciplined, rule-based trading.
Technical Composition, Calculation, Key Components & Features
📌 Kijun Sen (基準線) – Structural Trend Baseline
Calculated as the midpoint between the highest high and lowest low over a user-defined period.
Represents market equilibrium and structural balance rather than short-term momentum.
Naturally adapts to expanding and contracting price ranges.
Provides a stable baseline for regime detection and volatility validation.
Acts as the anchor for deviation bands and persistent trend-state logic.
Unlike fast or reactive moving averages, the Kijun Sen emphasizes price structure and equilibrium , making it especially effective for higher-quality trend confirmation.
📌 Volatility Adjustment – Standard Deviation Bands
Standard deviation is calculated over a configurable lookback to measure current price dispersion.
Upper and lower envelopes are formed by applying a deviation multiplier to the Kijun Sen.
Band width expands during volatility surges and contracts during consolidation.
Creates proportional, volatility-aware thresholds instead of static offsets.
Visually represents market energy through expanding and compressing channels.
These adaptive bands ensure that trend signals only occur when volatility supports directional movement.
📌 Trend Signal & Regime Calculation
Bullish Trend is confirmed when price closes above the upper deviation band.
Bearish Trend is confirmed when price closes below the lower deviation band.
Once established, the trend state persists until an opposing volatility break occurs.
This persistence reduces whipsaws and improves regime stability.
Trend state is reinforced with color-coded lines, envelopes, and background shading.
This volatility-confirmed persistence model is visible in the chart, where trends remain intact through minor pullbacks and only flip on decisive expansion.
How It Works in Trading
✅ Volatility-Confirmed Trend Detection – Requires expansion beyond deviation bands.
✅ Noise Suppression – Filters low-energy price movement within volatility envelopes.
✅ Regime Persistence – Maintains trend state until statistical invalidation.
✅ Immediate Visual Context – Direction, strength, and transitions are clear at a glance.
Visual Representation
Trend signals are displayed directly on price using both line and background context:
🟢 Green / Teal Kijun & Envelope → Confirmed bullish regime.
🔴 Red / Pink Kijun & Envelope → Confirmed bearish regime.
Semi-transparent band fill visualizes volatility expansion and compression.
Buy and Sell labels appear only on confirmed regime transitions.
The lower panel includes:
Strategy equity curve based on trend exposure.
Buy & Hold equity for performance comparison.
Background regime shading synchronized with trend state.
Features and User Inputs
The Kijun Sen Standard Deviation framework offers a focused yet powerful set of configurable inputs:
Kijun Sen Length – Controls structural trend sensitivity.
Standard Deviation Controls – Adjust lookback length and multiplier for regime strictness.
Backtesting & Date Filters – Define evaluation periods and starting conditions.
Display Options – Toggle labels, equity curves, and background shading.
Color Customization – Fully configurable buy/sell colors for trends and equity curves.
These controls allow users to balance responsiveness, stability, and clarity without overfitting.
Practical Applications
The Kijun Sen Standard Deviation indicator is designed for traders who prioritize structure, volatility confirmation, and regime awareness.
Primary Trend Filtering – Identify and stay aligned with dominant market direction.
Volatility-Aware Trend Following – Participate only when price expansion confirms intent.
Risk-Managed Exposure – Avoid chop during compression and transitional phases.
Systematic Strategy Development – Use as a regime engine or higher-timeframe filter.
Performance Evaluation – Compare trend-following equity against buy-and-hold benchmarks.
This framework bridges classical Ichimoku structure with modern statistical validation.
Conclusion
The Kijun Sen Standard Deviation indicator by QuantLapse Systems represents a refined evolution of Ichimoku-based trend analysis.
By integrating the structural equilibrium of the Kijun Sen with adaptive standard deviation confirmation, the system delivers clearer regime classification, reduced noise, and more reliable trend participation.
Rather than attempting to predict price, it focuses on confirming when trends are statistically justified .
Who should use Kijun Sen Standard Deviation:
📊 Trend-Following Traders – Stay aligned with dominant market structure.
⚡ Momentum & Swing Traders – Enter only on volatility-backed expansions.
🤖 Systematic & Algorithmic Traders – Ideal as a regime filter or trend-state engine.
Past performance is not indicative of future results.
Disclaimer: All trading involves risk, and no indicator can guarantee profitability.
Strategic Advice: Always backtest thoroughly, optimize parameters responsibly, and align settings with your timeframe, asset class, and risk tolerance before live deployment.
