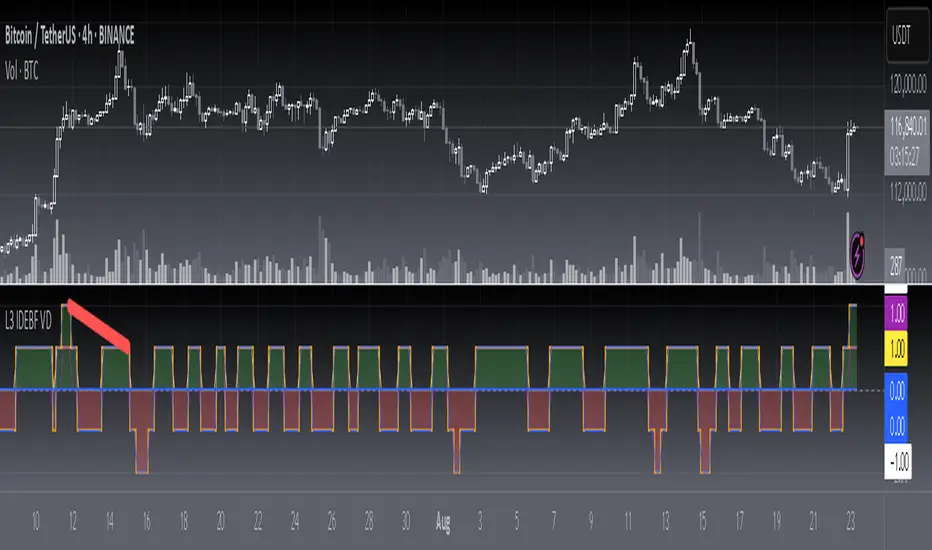
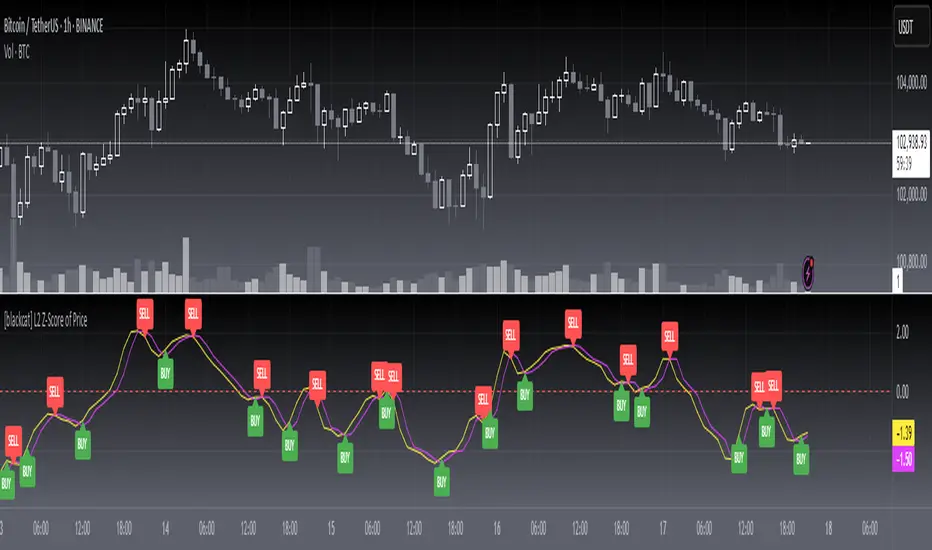
[blackcat] L3 Improved Dual Ehlers BPF for Volatility DetectionOVERVIEW
This script implements an advanced L3 Improved Dual Ehlers Bandpass Filter (BPF) for volatility detection, combining both L1 and L2 calculation methods to create a comprehensive trading signal. The script leverages John Ehlers' sophisticated digital signal processing techniques to identify market cycles and extract meaningful trading signals from price action. By combining multiple cycle detection methods and filtering approaches, it provides traders with a powerful tool for identifying trend changes, momentum shifts, and potential reversal points across various market conditions and timeframes. The L3 approach uniquely combines the outputs of both L1 (01 range) and L2 (-11 range) methods, creating a signal that ranges from -1~2 and provides enhanced sensitivity to market dynamics.
FEATURES
🔄 Dual Calculation Methods: Choose between L1 (01 range), L2 (-11 range), or combine both for L3 signal (-1~2 range) to match your trading style
📊 Multiple Cycle Detection: Seven different dominant cycle calculation methods including HoDyDC (Hilbert Transform Dominant Cycle), PhAcDC (Phase Accumulation Dominant Cycle), DuDiDC (Duane Dominant Cycle), CycPer (Cycle Period), BPZC (Bandpass Zero Crossing), AutoPer (Autocorrelation Period), and DFTDC (Discrete Fourier Transform Dominant Cycle)
🎛️ Flexible Mixing Options: Six sophisticated mixing methods including weighted averaging, simple sum, difference extraction, dominant-only, subdominant-only, and adaptive mixing that adjusts based on signal strength
🌊 Bandpass Filtering: Precise bandwidth control for both dominant and subdominant filters, allowing fine-tuning of frequency response characteristics
📈 Advanced Divergence Detection: Robust algorithm for identifying bullish and bearish divergences with customizable lookback periods and range constraints
🎨 Comprehensive Visualization: Extensive customization options for all signals, colors, plot styles, and display elements
🔔 Comprehensive Alert System: Built-in alerts for divergence signals, zero line crosses, and various market conditions
📊 Real-time Cycle Information: Optional display of dominant and subdominant cycle periods for educational purposes
🔄 Adaptive Signal Processing: Dynamic adjustment of parameters based on market conditions and volatility
🎯 Multiple Signal Outputs: Simultaneous generation of L1, L2, and L3 signals for different trading strategies
HOW TO USE
Select Calculation Method: Choose between "l1" (01 range), "l2" (-11 range), or "both" (L3, -1~2 range) in the Calculation Method settings based on your preferred signal characteristics
Configure Cycle Detection: Select your preferred Dominant Cycle Method from the seven available options and adjust the Cycle Part parameter (0.1-0.9) to fine-tune cycle sensitivity
Set Subdominant Parameters: Configure the subdominant cycle either as a ratio of the dominant cycle or as a fixed period, depending on your analysis approach
Adjust Filter Bandwidth: Fine-tune the bandwidth settings for both dominant and subdominant filters (0.1-1.0) to control the frequency response and signal smoothing
Choose Mixing Method: Select how to combine the filters - weighted averaging for balance, sum for maximum sensitivity, difference for trend isolation, or adaptive mixing for dynamic response
Configure Smoothing: Select from SMA, EMA, or HMA smoothing methods with adjustable length (1-20 bars) to reduce noise in the final signal
Customize Visualization: Enable/disable individual plots, divergence detection, zero line, fill areas, and customize all colors to match your chart preferences
Set Divergence Parameters: Configure lookback ranges (5-60 bars) for divergence detection to match your trading timeframe and style
Monitor Signals: Watch for crosses above/below zero line and divergence patterns, paying attention to signal strength and consistency
Set Up Alerts: Configure alerts for divergence signals, zero line crosses, and other market conditions to stay informed of trading opportunities
LIMITATIONS
The script requires the dc_ta library from blackcat1402 for several advanced cycle calculation methods (HoDyDC, PhAcDC, DuDiDC, CycPer, BPZC, AutoPer, DFTDC)
L1 method operates in 01 range while L2 method uses -11 range, requiring different interpretation approaches
Combined L3 signal ranges from -1~2 when both methods are selected, creating unique signal characteristics that traders must adapt to
Divergence detection accuracy depends on proper lookback period settings and market volatility conditions
Performance may be impacted with very long lookback ranges (>60 bars) or when multiple plots are simultaneously enabled
The script is designed for non-overlay use and may not display correctly on certain chart types or with conflicting indicators
Adaptive mixing method requires careful threshold tuning to avoid excessive signal fluctuation
Cycle detection algorithms may produce unreliable results during low volatility or highly choppy market conditions
The script assumes regular price data and may not perform optimally with irregular or gapped price sequences
NOTES
The script implements advanced mathematical calculations including bandpass filters, Hilbert transforms, and various cycle detection algorithms developed by John Ehlers
For optimal results, experiment with different cycle detection methods and bandwidth settings across various market conditions and timeframes
The adaptive mixing method automatically adjusts weights based on signal strength, providing dynamic response to changing market conditions
Divergence detection works best when the "Plot Divergence" option is enabled and when combined with other technical analysis tools
Zero line crosses can indicate potential trend changes or momentum shifts, especially when confirmed by volume or other indicators
The script includes commented code for cycle information display that can be enabled if you want to monitor cycle periods in real-time
Different calculation methods may perform better in different market environments - L1 tends to be smoother while L2 is more sensitive
The subdominant cycle helps filter out noise and provides additional confirmation for signals generated by the dominant cycle
Bandwidth settings control the filter's frequency response - lower values provide more smoothing while higher values increase sensitivity
Mixing methods offer different approaches to combining signals - weighted averaging is generally most reliable for most trading applications
THANKS
Special thanks to John Ehlers for his pioneering work in cycle analysis and digital signal processing for financial markets. This script implements and significantly improves upon his bandpass filter methodology, incorporating multiple advanced techniques from his extensive body of work. Also heartfelt thanks to blackcat1402 for the dc_ta library that provides essential cycle calculation methods and for maintaining such a valuable resource for the Pine Script community. Additional appreciation to the TradingView platform for providing the tools and environment that make sophisticated technical analysis accessible to traders worldwide. This script represents a collaborative effort in advancing the field of algorithmic trading and technical analysis.
Pine Script® Indikator